Programming Principles[1] : 프로그래밍 기본 (Basic Algorithms)
프로그래밍의 기초를 배우기 위해서는 먼저 기본적인 알고리즘의 이론에 대해 이해할 필요가 있다. 알고리즘(Algorithms)은 특정 문제를 해결하기 위해 명확하게 정의된 일련의 절차나 단계들을 의미한다. 알고리즘은 주어진 입력을 처리하여 원하는 출력으로 변환하는 방법을 체계적으로 설명하며, 컴퓨터 과학, 수학, 데이터 처리, 인공지능 등 다양한 분야에서 사용된다. 알고리즘의 문제 정의와 구성 요소는 다음과 같다.
문제 (Problem) : 해결하고자 하는 특정 질문이나 과제이며 일반적으로 문제는 여러 경우에 대해 일반화된 형태로 표현
파라미터 (Parameter) : 문제에서 값이 주어지지 않은 변수로, 문제의 조건이나 상황을 정의하는데 사용된다. 파라미터는 문제를 구체화하는 데 중요한 요소로, 문제의 일반적인 형태를 특정 상황에 맞게 변형할 수 있다.
문제의 사례 (Instance) : 문제의 파라미터에 특정 값을 지정한 상태로 추상적인 형태가 아닌, 구체적인 값을 가진 상태
사례에 대한 해답 (Solution) : 주어진 문제의 사례에 대해 도출된 정답으로 입력된 특정 사례에 대한 해결책을 의미
프로그래밍은 단순히 문법을 익히는 것이 아니라, 문제를 해결하는 논리적 사고를 기르는 과정이다. 알고리즘은 특정 문제를 해결하기 위한 절차나 규칙의 집합이며, 이를 만자 이해할 수 있어야 효율적인 코드 작성이 가능해진다. 객체 지향 이론과 자료구조, 본격적인 알고리즘을 학습하기 이전에 먼저 알고리즘에 대한 기본적인 개념을 정리하고, 프로그래밍 언어의 문법에 대해 정리해두었다.
1. 알고리즘의 표현
1. 자연어 (Natural Language) : 사람들이 일상적으로 사용하는 언어를 통해 알고리즘을 설명하는 방식이다. 자연어는 누구나 쉽게 이해할 수 있기 때문에, 알고리즘의 기본 개념이나 단순한 절차를 설명할 때 유용하지만 문법적 구조나 표현의 차이로 인해 모호해질 수 있으며, 정확한 절차를 전달하기 어려울 수 있다.
2. 의사코드(Pseudo code) : 알고리즘의 논리적 흐름을 표현하기 위해 자연어와 프로그래밍 언어의 혼합체를 사용하는 방법으로 자연어보다 명확하고 구조화된 표현을 제공하며, 논리적 흐름을 쉽게 이해할 수 있다. 또한 특정 프로그래밍 언어에 종속되지 않으므로, 다양한 언어로 구현할 수 있는 유연성을 가진다.

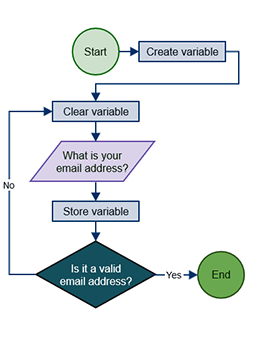
3. 순서도(Flowchart) : 알고리즘을 시각적으로 표현하는 방법으로, 도형과 화살표를 사용하여 절차의 흐름을 나타낸다. 알고리즘의 절차와 흐름을 시각적으로 표현하여, 전체적인 구조를 한눈에 파악할 수 있어 절차가 명확하고 오류를 쉽게 찾을 수 있다.

4. 프로그래밍 언어(Programming Language) : 알고리즘을 실제로 실행할 수 있도록 코드로 구현하는 방식이다. 프로그래밍 언어는 컴퓨터가 직접 실행할 수 있는 형태로 알고리즘을 표현하며, 정확한 문법과 구조를 요구한다. 코드로 구현된 알고리즘은 특정한 입력에 대해 구체적인 출력을 생성할 수 있으며, 실제 문제를 해결하는 데 사용된다.
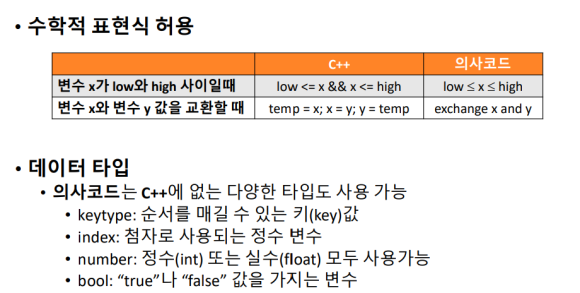
C++과 같은 프로그래밍 언어 코드는 실행 가능한 언어로, 엄격한 문법과 규칙을 따른다. 배열 인덱스는 0부터 시작하며, 배열 크기는 고정되어야 한다. 반면, 의사코드는 알고리즘의 논리를 표현하기 위한 도구로, 더 유연하고 직관적인 표현을 허용한다. 의사코드는 배열 인덱스를 임의로 설정하거나 배열 크기를 동적으로 정의할 수 있으며, C++에 없는 다양한 데이터 타입과 수학적 표현을 사용할 수 있다.
2. 알고리즘의 분석

공간 복잡도(Memory Complexity)는 알고리즘이 입력 크기(n)에 따라 얼마나 많은 메모리 공간을 사용하는지를 측정하는 방법으로 알고리즘이 문제를 해결하기 위해 추가로 사용하는 메모리 자원을 나타낸다. 예를 들어, 버블 정렬(Bubble Sort)은 정렬을 수행할 때 입력 배열 외에 별도의 메모리를 거의 사용하지 않으므로 공간 복잡도는 O(1), 즉 상수 공간이다. 반면, 병합 정렬(Merge Sort)은 정렬을 위해 추가적인 배열을 할당해야 하므로 공간 복잡도는 O(n)이다.
시간 복잡도(Time Complexity)는 알고리즘이 주어진 입력 크기(n)에 따라 얼마나 많은 단위 연산(명령어)을 수행하는지를 측정하는 방법이다. 이는 알고리즘이 커지는 입력에 대해 얼마나 효율적으로 실행되는지를 분석하며, 빅오 표기법(O notation)을 사용해 최악의 경우 시간 복잡도를 나타낸다. 예를 들어, 배열의 모든 원소를 한 번씩 검사하는 선형 탐색(linear search)은 입력 크기 n에 비례해 시간이 증가하므로 시간 복잡도는 O(n)이다. 반면, 이진 탐색(binary search)은 정렬된 배열에서 원소를 찾는 알고리즘으로, 절반씩 나눠서 탐색하기 때문에 시간 복잡도는 O(log n)이다.
시간 복잡도 분석은 알고리즘의 성능을 평가할 때 기계나 표현 척도에 독립적이어야 하며, 문제 자체의 복잡도를 나타내야 한다. 이를 위해 단위 연산(예: 비교문, 지정문)과 같은 기본적인 연산의 횟수를 기준으로 측정한다. 또한, 입력 크기(예: 배열의 크기, 행렬의 행과 열의 크기, 트리의 마디와 이음선 수)도 중요한 요소로, 입력 크기에 따라 알고리즘의 성능이 어떻게 변화하는지를 분석한다.

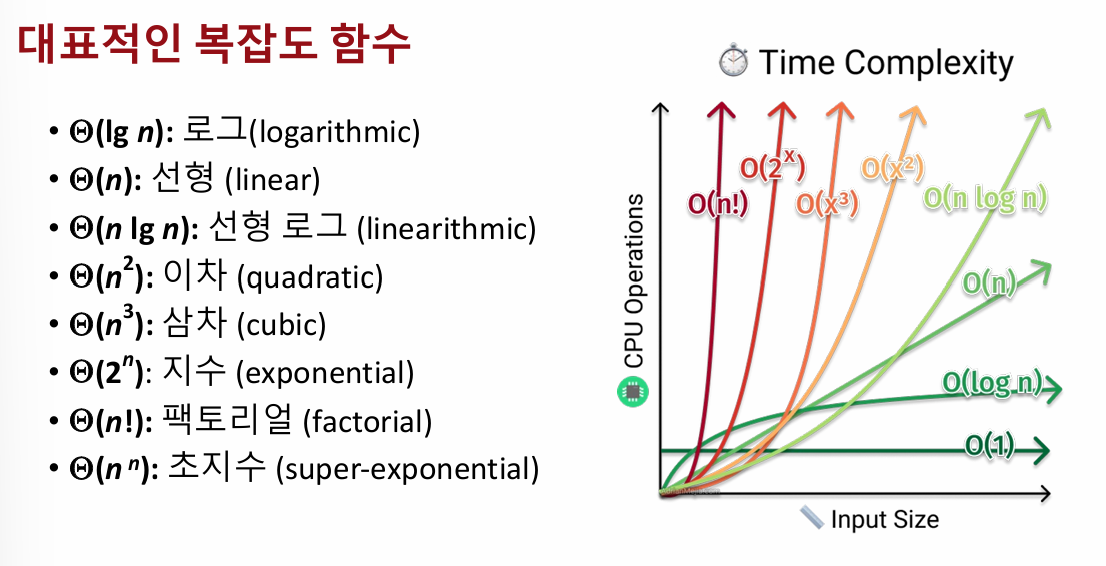
시간 복잡도 분석 방법은 알고리즘의 특성과 성능 요구에 따라 다르게 사용된다. 일정 시간복잡도(T(n))는 입력값과 무관한 알고리즘에서 사용되며, 평균 시간복잡도(A(n))는 일반적인 경우에 사용되지만 계산이 복잡할 수 있다. 성능이 중요한 시스템에서는 최악 시간복잡도(W(n))가 주로 사용되어 최악의 경우 성능을 보장한다. 최선 시간복잡도(B(n))는 거의 사용되지 않으며, 핵발전소 통제 예시를 통해 주로 최악 시간복잡도를 다룬다. 복잡도 함수는 양의 정수에서 양의 실수로 매핑되는 함수로, 예시로는 f(n) = n, n², lg n, 3n² + 4n 등이 있다.
3. 복잡도 함수

점근적 상태 : 함수 f(n)의 점근적 상태는 n이 무한히 커질 때의 함수의 행동을 설명한다. 예를 들어, f(n)=1/n일 경우, 이 커짐에 따라 함수의 값은 점점 작아져 0에 수렴한다. 이를 수학적으로 표현하면, 다음과 같이 극한을 고려할 수 있다.

이와 같은 경우, 함수 f(n)는 n이 커짐에 따라 0으로 수렴하므로, 점근적으로 '0'에 가까워지는 성질을 가진다. 이러한 특성은 가 어떤 입력 크기에서 얼마나 빠르게 감소하는지를 나타내며, 알고리즘 분석에 있어 효율성을 평가할 때 중요하다. 점근적 분석은 보통 최악, 평균, 최선의 시간복잡도를 비교할 때 유용하게 사용된다.
복잡도 함수 표기법
• O( ): 빅 오(Big O) - 점근적 상한 (asymptotic upper bound)
빅 오(Big O) 표기법은 알고리즘의 시간 복잡도나 공간 복잡도를 설명하는 방식으로, 입력 크기 n이 매우 클 때, 알고리즘이 어떻게 동작하는지 보여준다. 즉, 입력 크기가 증가함에 따라 실행 시간이 얼마나 빨리 증가하는지를 표현하는 방법인 것이다.


빅 오 표기법에서 가장 중요한 개념은 상한선(upper bound)이다. 즉, 주어진 함수 g(n)의 성장을 어떤 기준 함수 f(n)로 묶을 수 있는지를 확인하는 과정으로 목표는 g(n) ≤ c × f(n)을 만족하는 c와 N을 찾는 것이다. 주어진 식에서 g(n) = n² + 10n이고, 우리는 이를 O(n²)로 표현하려고 한다. 즉, 우리가 찾고자 하는 것은 n² + 10n이 어느 정도로 n²보다 빨리 자라지 않는지를 확인하는 것이다.


n² + 10n의 성장을 n²에 의해 얼마나 억제될 수 있는지 확인해야 한다. 빅 오 표기법에서, 상한선을 설정하기 위해 함수 n² + 10n을 적절한 배수인 c × n²과 비교하는 과정을 거치는데 이 과정에서 상수 c와 N을 찾으면, 그 함수는 빅 오 표기법으로 O(n²)에 속한다고 결론내릴 수 있다. 따라서 2n²와 11n²과의 비교는, 각각 c = 2와 c = 11로 설정된 상한선을 찾아 빅 오의 정의에 부합하는지 확인하는 과정이다.



• W( ): 오메가(Omega) - 점근적 하한 (asymptotic lower bound)
오메가(Ω) 표기법은 점근적 하한(asymptotic lower bound)을 나타내는 수학적 표현이다. 이는 주어진 함수 g(n)이 f(n)보다 최소한 어느 정도 빠르게 증가하는지, 즉 최소 성장 속도를 나타낸다. g(n) ∈ Ω(f(n))는 g(n)이 f(n)의 하한선 아래로 내려가지 않는다는 의미이다.


좀 더 구체적으로, g(n) ≥ c × f(n)가 성립하는 양의 상수 c와 음이 아닌 정수 N이 존재해야 한다. 즉, n이 충분히 큰 경우, g(n)은 항상 f(n)의 배수 이상이라는 것을 보장한다. 예를 들어, g(n) = 3n²이고 f(n) = n²라면, g(n)은 f(n)보다 빠르게 또는 최소한 동일하게 증가한다. 따라서 g(n) ≥ 1 × n²라는 불평등이 성립하고, 상수 c = 1과 N = 1을 선택하면, g(n) ∈ Ω(n²)임을 알 수 있다.



만약 n ∈ Ω(n²)라고 가정하면, 이는 n이 n²보다 빠르게 또는 최소한 같은 속도로 성장한다는 의미이다. 수학적으로 n ≥ c × n²라는 부등식이 성립해야 하고, 여기서 c는 양의 상수이다. 그러나 이 부등식을 n으로 나누면 1n≥c\frac{1}{n} ≥ c가 되는데, n이 커질수록 1n\frac{1}{n}은 0에 가까워져서 어떤 양의 상수 c를 항상 초과할 수 없다. 예를 들어, n = 10일 때는 110=0.1\frac{1}{10} = 0.1이지만, n이 100이 되면 1100=0.01\frac{1}{100} = 0.01로 줄어든다. 따라서, 원래의 가정은 모순이므로 n ∉ Ω(n²)임을 알 수 있다.

• Q( ): 쎄타 (Theta) - 점근적 상한 및 하한 (asymptotic tight bound)
Θ(Theta) 표기법은 점근적 상한 및 하한을 동시에 나타내는 수학적 표현으로, 알고리즘의 성장률을 정확하게 나타낸다. 주어진 복잡도 함수 f(n)에 대해, g(n) ∈ Θ(f(n))라는 것은 g(n)이 f(n)과 같은 성장 속도를 가진다는 것을 의미한다. 이는 수학적으로 c × f(n) ≤ g(n) ≤ d × f(n)가 성립하는 양의 상수 c와 d, 그리고 음이 아닌 정수 N이 존재해야 함을 뜻한다. 예를 들어, 만약 g(n) = n²이라면, g(n)은 O(n²)이고 Ω(n²)이므로 Θ(n²)에 속한다. 즉, n이 충분히 커질 때, n²은 항상 c × n²와 d × n² 사이에 존재하므로, g(n)은 f(n)의 정확한 경계를 제공하는 것이다.


g(n) = n² + 3n이라는 예시를 들어보자. 상한을 확인하기 위해 d = 2를 선택하면 n² + 3n ≤ 2n²가 성립하는 n의 값이 존재하며, 예를 들어 n ≥ 4일 때 이 불등식이 성립한다. 하한을 확인하기 위해 c = 1을 선택하면 n² + 3n ≥ n²도 n ≥ 1일 때 성립한다. 따라서 g(n) = n² + 3n은 O(n²)와 Ω(n²) 모두에 속하므로, g(n) ∈ Θ(n²)라고 결론지을 수 있다. 이는 g(n)이 n이 커질수록 f(n)과 동일한 성장 속도를 가지며, 알고리즘의 효율성을 명확하게 정의하는 데 도움을 준다.

4. 프로그래밍 문법

알고리즘이 추상적인 개념에 머무르지 않고 실제로 실행 가능한 형태로 구현되어야 하기 때문에 알고리즘을 학습하기 위해서는 프로그래밍 언어를 배워야 한다. 컴퓨터가 이해할 수 있는 코드로 작성하여 실험하고, 실행 시간과 공간 복잡도를 측정하면 알고리즘의 성능을 분석하고 최적화할 수 있다 . 특히 C++은 알고리즘 학습에 적합한 언어로 꼽히는데, 표준 라이브러리(STL)를 통해 효율적인 자료구조와 알고리즘을 쉽게 활용할 수 있으며, 저수준 메모리 관리 기능을 제공해 연산 속도를 최적화할 수 있기 때문이다. 프로그래밍 언어를 다루기 위해선, 먼저 기본 문법을 이해해야한다.
4.1 변수와 자료형
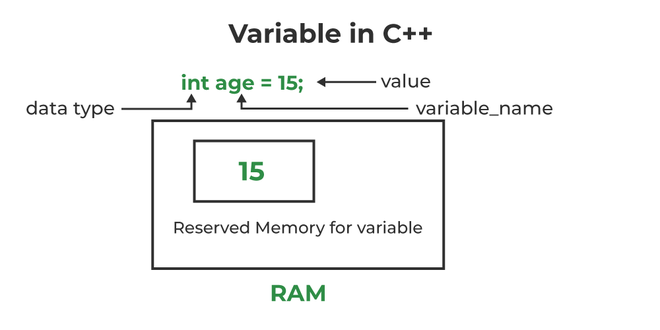
변수(Variables)는 프로그램 내에서 데이터를 저장하고 처리할 수 있는 메모리 공간으로, 선언할 때 자료형과 변수 이름을 지정하여 사용할 수 있다. 예를 들어 int score = 0;는 정수형 변수 score를 선언하고 초기값으로 0을 할당하는 코드이다. 모든 변수는 선언과 동시에 초기화하는 것이 중요하며, 초기화하지 않으면 해당 메모리 위치에 남아 있는 이전 값(쓰레기 값)이 저장될 수 있다. 이러한 쓰레기 값은 예상치 못한 동작을 유발할 수 있어, 안전한 프로그래밍을 위해 항상 초기값을 지정하는 습관이 필요하다.
int i = 0; // 고전적 초기화
int i { 100 } // 보편적 초기화변수명은 숫자로 시작하면 안되고 사이에 공백이 들어가면 안됨
자료형(Data type)은 컴퓨터가 데이터를 이해하고 처리할 수 있도록 데이터의 종류와 크기를 정의하는 요소로 주요한 자료형에는 정수형, 부동 소수점형, 문자형, 부울형이 있다. 정수형은 소수점 없는 정수 값을 저장하며, short는 16비트, int는 32비트, long은 32비트, long long은 64비트를 차지해 더 큰 숫자를 저장할 수 있다. 부동 소수점형은 소수점을 포함한 실수 값을 저장하며 float는 32비트, double은 64비트, long double은 64비트 이상을 사용할 수 있다. 부동 소수점형은 정밀한 소수 계산이 필요한 상황에 주로 쓰인다.
auto d = 1.0 // 자동 타입 추론(automatic type deduction) 함수의 매게 변수로는 사용이 불가
const int i = 1 // 기호 상수 - 변수 선언 앞에 const를 붙이면 상수가 됨C++에서는 콘솔 입출력을 처리하기 위해 cin과 cout 객체를 사용한다. cin은 표준 입력 스트림을 통해 사용자로부터 데이터를 입력받는데 사용된다. 입력된 데이터는 변수의 타입에 따라 자동으로 형 변환되어 저장되며 예를 들어 int number; cin >> number;라는 코드는 사용자로부터 정수를 입력받아 number 변수에 저장한다. 반면, cout은 표준 출력 스트림을 통해 데이터를 콘솔에 출력하는 데 사용된다. 문자열, 정수, 실수 등의 다양한 데이터 타입을 손쉽게 출력할 수 있으며, 예를 들어 cout << "Hello, World!" << endl;은 "Hello, World!"를 출력하고 줄 바꿈을 추가한다.
또한, C++는 값을 증가하거나 감소시키는 증감 연산자(++, --)를 지원하는데, 이 연산자는 변수의 값을 1씩 늘리거나 줄인다. 후위 증가 연산자(i++)는 현재 명령을 실행한 후에 값을 증가시키며, 전위 증가 연산자(++i)는 값을 먼저 증가시킨 후 명령을 실행한다. 이를 통해 연산 순서에 따라 미세하게 다른 결과를 얻을 수 있어 유용하다.
auto d = 1.0 // 자동 타입 추론(automatic type deduction) 함수의 매게 변수로는 사용이 불가
const int i = 1 // 기호 상수 - 변수 선언 앞에 const를 붙이면 상수가 됨4.2. 제어 구조
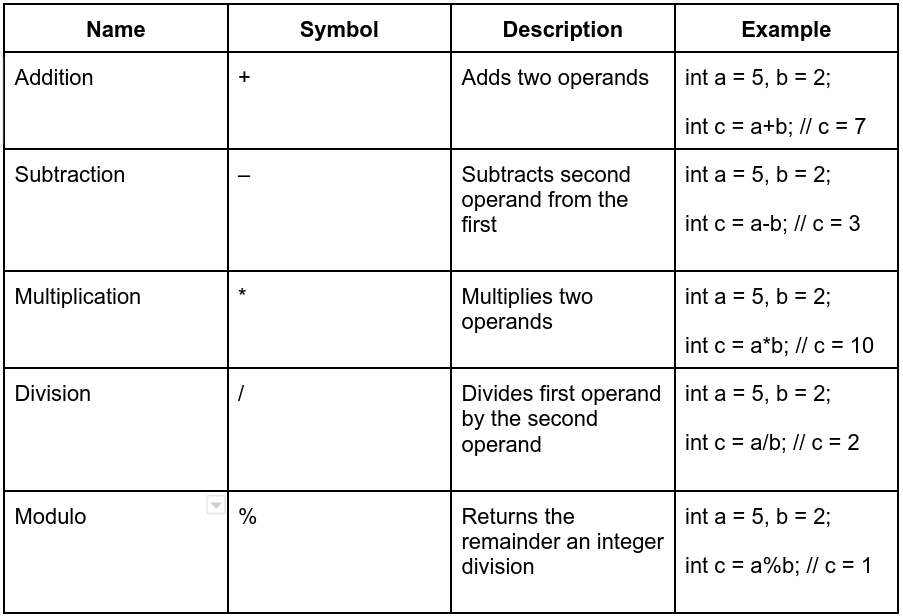
관계 연산자(relational operator)는 두 개의 피연산자를 비교하여 그 결과를 참(true) 또는 거짓(false)으로 판단하는 데 사용된다. 예를 들어, ==는 두 값이 같은지를, >는 왼쪽 값이 오른쪽 값보다 큰지를, !=는 두 값이 다른지를 비교한다. 반면에 논리 연산자(logical operator)는 여러 조건을 결합하여 복합적인 참 또는 거짓의 결과를 도출하는 데 사용된다. &&(논리 AND)는 모든 조건이 참일 때만 참을 반환하고, ||(논리 OR)는 하나 이상의 조건이 참이면 참을 반환하며, !(논리 NOT)는 조건의 참/거짓을 반대로 뒤집는다. 이 두 종류의 연산자는 프로그래밍에서 조건문을 작성할 때 필수적인 요소이다.
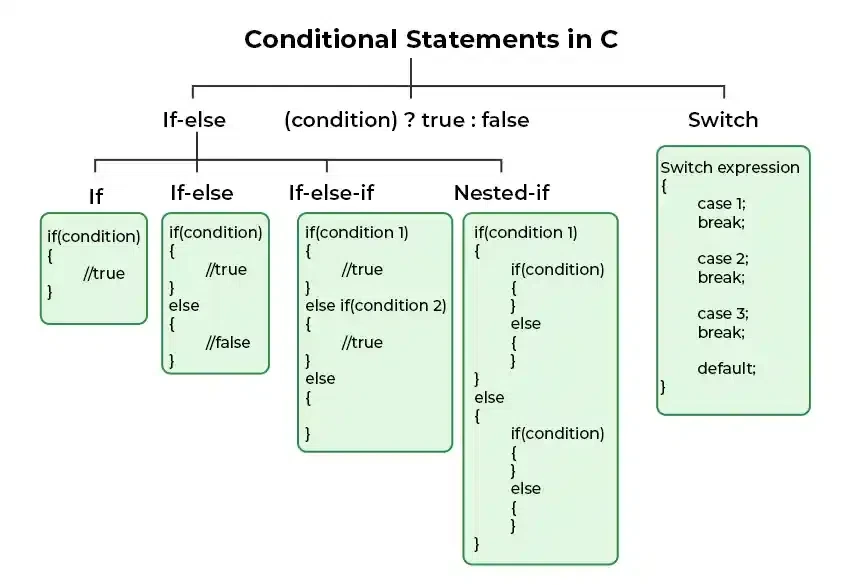
조건문(Conditional statement)과 반복문(iteration statement)도 제어 구조에 해당한다. if문은 조건이 참일 때 명령을 실행하고 거짓일 경우 아무 작업도 수행하지 않으며, 조건은 반드시 괄호로 묶어야 하고 두 개 이상의 조건이 있을 경우 중괄호로 코드 블록을 설정해야 한다. 사용자 실수로 인한 예외 발생 시에는 else 구문을 활용한 예외 처리가 필요하며, if ~ else 구조로 코드를 작성하면 CPU의 부하를 줄일 수 있다. switch문은 특정 수식을 계산하여 case와 비교하고 일치하는 경우 해당 문장을 실행하다가 break에 도달하면 종료되며, 기본적으로 정수형이나 문자형 상수에만 사용되므로 다룰 수 있는 조건이 제한적이다. 한정된 값이나 정형화된 값의 분기에 적합하며, 모든 switch문은 if문으로 변환 가능하지만 그 반대는 불가능하다. break문이 없을 경우 하위 명령문이 모두 실행되므로 반드시 명시해야 한다.
while문은 동일한 처리 과정을 여러 번 반복하며, 무한 루프를 생성하는 데 많이 사용된다. do while 루프는 조건과 관계없이 최소 한 번 실행되는 while문으로, 문장이 반드시 한 번 실행되어야 할 때 유용하다. for문은 특정 횟수만큼 반복할 때 사용되며 주로 배열에 활용되는데 반복 루프를 벗어나기 위해 break문을 사용하고, 현재 반복 과정의 나머지를 건너뛰고 다음 반복을 시작하려면 continue문을 사용한다.
4.3. 배열
배열(array)은 같은 종류의 데이터들이 순차적으로 메모리에 저장되는 자료구조로, 배열명은 곧 주소를 나타낸다. 배열의 특정 인덱스만 초기화하면 나머지 요소들은 쓰레기값으로 채워지며, 범위 기반 for 루프를 통해 배열을 순회할 수 있다.
C++의 배열에서 주의할 점은 for 루프에서 변수 i를 사용하면 배열 요소의 복사본이 생성되기 때문에 원본 배열은 수정되지 않는다. 이는 포인터 개념과 관련이 있는데, 배열의 각 요소는 메모리의 특정 주소에 저장되어 있으며, 일반 변수 i는 이 주소를 가리키는 포인터가 아닌 배열 요소의 값을 직접 복사한다. 예를 들어, int i는 arr 배열의 각 요소의 값(예: 1, 2 등)을 복사하여 i에 저장하므로 i를 통해 값을 변경하더라도 arr 배열의 원래 값에는 영향을 주지 않는다. 반면, int& i 참조자를 사용하면 i는 배열 요소의 주소를 참조하는 포인터로 작동하여 원본 배열의 값을 직접 변경할 수 있다. 이러한 방식은 메모리를 보다 효율적으로 사용하고, 복사로 인한 오버헤드를 줄여 실행 속도를 개선하는 효과를 가져온다.
int sal[5] = { 0 }; // 요소를 모두 0으로 초기화 int sales[5] = { 1,2,3 }; // 고전적 초기화 + 초기값 개수가 요소보다 적으면 나머진 0으로 초기화
int scores[] { 100,200,300 }; // 보편적 초기화 + 선언과 함께 초기화 할 경우 배열 크기 생략 가능int arr[] = {1, 2, 3, 4, 5};
for (int i : arr) {
i += 10; // 이 줄은 i의 값을 10 증가시키지만, arr 배열은 변경되지 않음
}
for (int& i : arr) {
i += 10; // 이 줄은 arr 배열의 각 요소를 직접 변경
}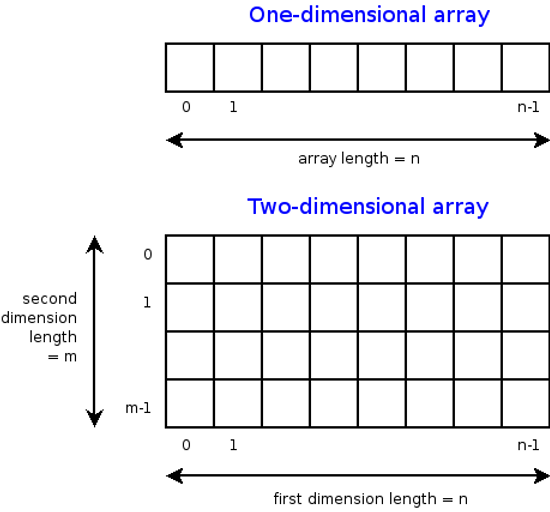
2차원 배열은 배열의 배열로 구성된 자료구조로 주로 2차원 테이블 형태로 데이터를 저장하는 데 사용된다. 이 구조에서 첫 번째 인덱스는 행 번호를 나타내고, 두 번째 인덱스는 열 번호를 나타낸다. 예를 들어 int arr[3][4]라는 2차원 배열이 있을 경우 이 배열은 3개의 행과 4개의 열로 구성되며 각 요소는 arr[0][0], arr[0][1]와 같이 행과 열의 인덱스를 통해 접근할 수 있다. 이를 통해 행렬 계산, 이미지 데이터 처리 등 다양한 응용 분야에서 효과적으로 데이터를 관리하고 사용할 수 있다.
int s[3][5] = { NULL }; // 2차원 배열 선언
int s[3][5] {{1,2,3,4,5},{2,4,6,8,10},{3,6,9,12,15}}; // 선언과 동시에 초기화
함수 포인터를 이용하면 C++ 스타일로 2차원 배열을 출력할 수 있다. 예를 들어, int arr4[3][3]라는 2차원 배열이 있을 때, for (int(&ln)[3] : arr4) 구문을 사용하여 각 행을 참조하는 ln이라는 레퍼런스를 생성할 수 있다. 이때 ln은 arr4의 각 행을 가리키며 내부 for 루프인 for (int col : ln)을 통해 각 열의 값을 순회하면서 출력할 수 있다. 이 방법을 사용하면 cout << col << " "와 같이 각 요소를 C++ 스타일로 간편하게 출력할 수 있어 가독성이 높고, 코드의 의도를 명확하게 전달할 수 있다.
for (int(&ln)[3] : arr4) { for (int col : ln) { cout << col << " "; } } //포인터를 이용하여 c++ 스타일로 2차원 배열 출력4.4. 함수
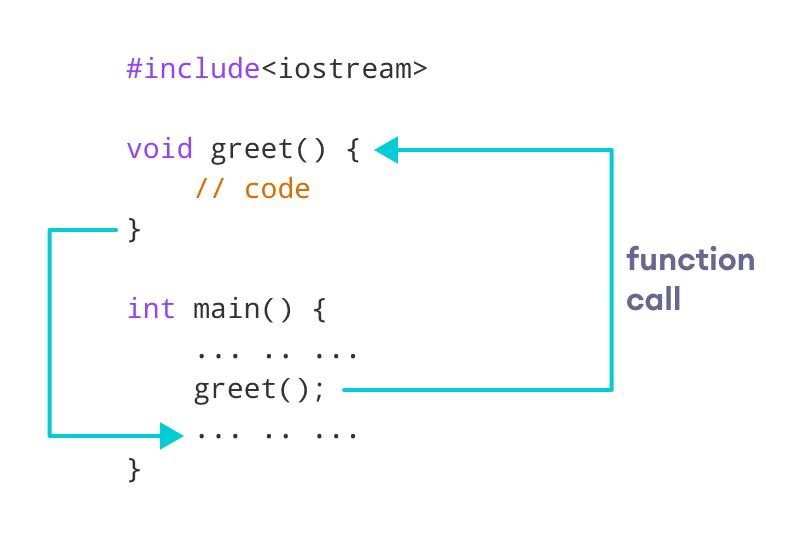
함수(function)는 특정 작업을 수행하고 그 결과를 반환하는 코드 블록으로 내장 함수와 사용자 정의 함수가 있다. 함수는 선언부와 구현부로 나뉘며, 선언부는 반환형, 함수 이름, 매개변수를 차례로 명시하는 가장 중요한 부분이다. 예를 들어, int max(int x, int y)는 선언부이며, { if(x > y) return x; else return y; }는 구현부로 함수가 수행할 내용을 담고 있다.
int max(int x, int y) // 선언부는 반환형 - 함수의 이름 - 매개변수를 차례대로 적음
{if(x>y) return x; else return y; } // 구현부는 중괄호 부분 함수가 수행에 필요한 문장 작성함수 원형은 함수가 정의되기 전에 미리 작성하여 컴파일러에게 매개변수 검사와 반환형 검사를 알리는 역할을 한다. 함수 호출 시 인수를 전달하는 방법에는 값으로 호출(call by value)과 참조로 호출(call by reference)이 있다. 값으로 호출은 인수의 값이 매개변수로 복사되어 원본 변수에 영향을 주지 않으며 안정성을 제공한다. 반면, 참조로 호출은 원본 인수가 함수에 전달되어 매개변수를 변경하면 원본 인수도 변경된다.
int square(int, int); // 함수 원형 정의int& ref = var; // 참조자 ref는 변수 var의 별명으로 값을 대입하면 참조하는 변수의 값이 변경중복 함수(Overloading)는 동일한 이름의 함수가 매개변수 형태에 따라 여러 개 정의될 수 있게 하며 디폴트 인수(default argument)는 매개변수가 주어지지 않을 때 기본값을 사용할 수 있도록 한다. 예를 들어, void display(char c = '*', int n = 10)에서 인수가 제공되지 않으면 기본값으로 출력된다. 주의할 점은 디폴트 인수는 반드시 마지막 인수여야 한다.
void display(char c = '*', int n = 10) { ~ } //디폴트 인수로 인수가 전달되지 않으면 디폴트 출력
인라인(inline) 함수는 C++에서 짧고 자주 호출되는 함수를 정의할 때 주로 사용하는 함수이다. 일반적으로 함수는 호출될 때마다 함수의 본체가 메모리에서 실행되지만, 인라인 함수는 컴파일러에게 이 함수를 호출하는 위치에 함수의 코드를 직접 삽입하라고 요청한다. 이렇게 하면 함수 호출에 필요한 시간과 자원을 줄일 수 있어 성능을 향상시킬 수 있다.
inline int square(int x) {
return x * x;
}
int result = square(5); // 컴파일러는 이 부분을 int result = 5 * 5;로 변환
대표적인 내장 함수인 string 클래스에서 주의할 점은 입력 시 공백을 인식하지 않기 때문에 getline(cin, sentence);와 같은 별도의 함수를 사용하여 공백을 포함한 문자열을 입력받아야 한다는 것이다.
getline(cin, sentence); // string 클래스 공백 입력지금까지 기본적인 알고리즘 이론과 프로그래밍 언어의 기초 문법을 학습하였다. 알고리즘은 프로그래밍의 핵심 개념으로, 문제 해결을 위한 체계적인 절차를 의미하며, 이를 효과적으로 구현하기 위해 알고리즘의 표현 방식, 시간 및 공간 복잡도 분석 방법을 이해하는 것이 중요하다. 빅오(Big-O), 오메가(Omega), 쎄타(Theta) 표기법을 통해 알고리즘의 성능을 평가할 수 있으며, 프로그래밍 언어(C++)를 활용하여 이를 실제 코드로 구현할 수 있다. C++에서는 변수, 자료형, 조건문, 반복문, 배열, 함수 등의 기본 개념을 익혔고, 이를 통해 알고리즘을 효율적으로 표현하고 실행할 수 있다. 이러한 학습을 통해 단순한 문법을 넘어서 알고리즘의 원리를 이해하고, 실제 문제 해결 능력을 기를 수 있는 토대를 쌓았다. 이제 이를 바탕으로 객체 지향 이론과 자료구조, 알고리즘과 같은 프로그래밍의 핵심 이론대해 정리할 것이다.