
시계열 데이터(Time Series Data)는 특정 시간 순서에 따라 발생하는 데이터를 의미한다. 시계열 데이터의 주요 특징은 데이터의 각 값이 시간이라는 차원에 따라 순차적으로 배열된다는 점이다. 이러한 데이터는 순서가 중요하며, 각 데이터 포인트는 이전 값과 연관이 있다. 즉, 독립적인 데이터가 아니라 시간적으로 연결된 데이터라는 점에서 특수하다. 예를 들어, 주식 가격, 기온 변화, 경제 지표 등의 데이터는 모두 시간에 따라 변화하는 순차적인 특성을 지닌다.
순차 데이터(sequential data)는 단순히 데이터가 일정한 순서로 배열된 것만을 의미하지만, 시계열 데이터는 각 데이터 포인트가 시간이라는 차원에 맞춰 배열된 데이터를 말한다. 이때 중요한 점은, 시계열 데이터에서 각 데이터 포인트가 이전의 값에 영향을 미친다는 것이다. 예를 들어, 주식 가격의 경우 오늘의 가격은 어제의 가격에 영향을 받을 수 있으며, 이러한 관계를 모델이 학습해야 한다.
시계열 데이터의 대표적인 예는 주식 시장 데이터이다. 주식의 일일 가격을 추적한다고 할 때 각 가격은 특정 날짜에 해당하는 값이며 가격의 변동은 시간에 따라 달라진다. 예를 들어, 특정 주식의 일일 가격을 추적할 때, 오늘의 주식 가격은 어제의 가격을 바탕으로 예측할 수 있는 경우가 많다. 이는 주식 시장의 특성상 순차적인 관계가 형성되어 있기 때문이다. 또 다른 예시는 기온이다. 매일 기온 데이터를 수집한다고 할 때, 각 기온 값은 하루를 기준으로 기록된다. 오늘의 기온은 어제의 기온과 관계가 있으며, 이러한 데이터는 시간에 따른 변화와 패턴을 분석하는 데 사용된다. 기온 데이터를 바탕으로 날씨 예측을 하는 모델은 지난 며칠간의 기온 데이터를 분석하여 앞으로의 기온을 예측할 수 있다
시계열 데이터는 때때로 다변량(multivariate) 형태로 존재할 수도 있다. 즉, 시간에 따른 여러 가지 변수를 동시에 추적하는 경우이다. 예를 들어, 주식 시장에서 하나의 회사의 주식 가격뿐만 아니라 다른 여러 변수(예: 거래량, 다른 주식의 가격, 경제 지표 등)도 함께 추적할 수 있다. 이런 경우, 각 변수는 시간에 따른 순차적인 데이터를 포함하며, 서로 다른 변수들 간의 상관관계를 분석하는 데 중요한 역할을 한다.
시계열 데이터는 단순한 순차적 데이터와 달리 시간의 흐름에 따른 데이터의 연관성을 고려해야 한다. 이는 주식 가격, 날씨 데이터, 경제 지표 등 다양한 분야에서 중요한 분석 도구로 활용되며 미래를 예측하거나 특정 패턴을 인식하는 데 유용하다. 시계열 데이터의 특징은 바로 시간에 따른 변화와 그 변화가 다른 변수들과 어떻게 상호작용하는지를 분석하는 데 중점을 둔다는 것이다.
1. Time Series Analysis: 전통적인 시계열 분석
전통적인 시계열 분석 기법에는 이동 평균(Moving Average), 지수 평활법(Exponential Smoothing), ARIMA(자기 회귀 누적 이동 평균, Autoregressive Integrated Moving Average) 모델이 포함된다.
이동 평균 (Moving Average): 이동 평균은 특정 시간 간격으로 평균을 계산하여 데이터를 평활화하는 방법이다. 예를 들어, 주식 시장에서 5일 간의 평균 주가를 계산하여 현재의 주가를 예측하는 데 사용할 수 있다. 이는 단기적인 변동을 부드럽게 하고, 추세를 파악하는 데 유용하다.
지수 평활법 (Exponential Smoothing): 과거의 데이터에 가중치를 두고 예측을 진행하는 방법이다. 최근의 데이터에 더 높은 가중치를 부여해 예측의 정확도를 높인다. 예를 들어, 주식 가격 예측 시, 최근 몇 주간의 데이터를 더 중요하게 반영하여 예측 모델을 만들 수 있다.
ARIMA: ARIMA 모델은 시간에 따른 자기 상관을 고려하여 예측을 진행한다. 이는 시계열 데이터의 자기 회귀(AR), 차분(I), 이동 평균(MA) 세 가지 요소를 결합한 모델로, 주식 시장 예측이나 날씨 예측과 같이 시간이 지남에 따라 반복되는 패턴을 찾는 데 사용된다.
2. Machine Learning: 머신러닝을 활용한 시계열 모델링
머신러닝 기법에서는 로지스틱 회귀(Logistic Regression), 선형 회귀(Linear Regression), SVM(서포트 벡터 머신), 랜덤 포레스트(Random Forest), 히든 마르코프 모델(Hidden Markov Model) 등이 사용된다.
선형 회귀(Linear Regression): 선형 회귀는 과거 데이터를 기반으로 선형 관계를 찾아 미래를 예측하는 기법이다. 예를 들어, 주식 가격 예측에서 가격 = w₀ + w₁ * 날짜와 같은 선형 방정식을 사용하여 예측할 수 있다.
서포트 벡터 머신(SVM): SVM은 시계열 데이터에서 분류 문제를 해결할 때 유용하다. 예를 들어, 주식이 상승할지 하락할지를 예측하는 데 사용될 수 있다. SVM은 데이터를 고차원 공간으로 변환하여, 더 정확한 분류를 가능하게 한다.
랜덤 포레스트(Random Forest): 랜덤 포레스트는 여러 개의 결정 트리를 사용하여 예측을 진행하는 앙상블 학습 기법이다. 이를 통해 데이터의 노이즈를 줄이고, 더 정확한 예측을 할 수 있다.
3. Deep Learning: 딥러닝을 활용한 시계열 모델링
딥러닝 기법에서는 순환 신경망(RNN), 다층 RNN, 양방향 RNN(Bi-directional RNN), LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit), Seq2Seq 모델 등이 사용된다.
순환 신경망(RNN): RNN은 시계열 데이터를 처리하기 위한 기본적인 딥러닝 모델로, 입력 데이터가 시간 순서대로 전달되며, 이전 상태가 현재 상태에 영향을 미친다. 예를 들어, 주식 가격 예측에서 과거의 주식 가격 정보가 현재 예측에 영향을 미친다.
LSTM과 GRU: LSTM과 GRU는 RNN의 문제점인 기울기 소실 문제를 해결하는 기법이다. LSTM은 긴 시퀀스 데이터를 처리하는 데 유리하며, 주식 시장 예측이나 자연어 처리에 널리 사용된다. 예를 들어, 주식의 장기적인 추세를 예측할 때 LSTM이 효과적이다.
Seq2Seq: Seq2Seq 모델은 입력 시퀀스를 다른 길이의 출력 시퀀스로 변환하는 모델이다. 주로 기계 번역과 같은 작업에 사용되지만, 시계열 예측에도 응용될 수 있다. 예를 들어, 과거의 주식 가격을 입력으로 받아 미래의 가격을 예측하는 데 사용될 수 있다.

인공신경망 (Artificial Neural Network, ANN) 수많은 뉴런 (Neuron)과 각 뉴런을 연결하는 시냅스 (Synapse)로 구성된 인간의 뇌 신경망을 노드 (Node)와 링크 (Link)로 모형화한 네트워크 형태의 지도학습 모형이다. 즉, 인공신경망은 수많은 뉴런과 뉴런이 시냅스로 상호 연결되어 정보를 처리하는 뇌의 정보처리 및 전달 프로세스를 모방하여 분류 또는 수치 예측을 수행한다. 지금까지 살펴본 머신러닝 지도학습 모형들이 단순히 인간의 학습 방식을 모방한 것이라면, 인공신경망은 인간의 생물학적 신경계를 모형화해 인간의 정보 처리 및 추론 과정을 모방한 것이다.
초기의 인공신경망은 성능 면에서 랜덤 포레스트나 SVM보다 좋지 않아 실용성이 떨어졌지만, 2000년 이후부터 알고리즘과 하드웨어의 발전으로 성능이 개선되면서 딥러닝 (Deep Learning)이라는 이름으로 다시 불리게 되어 많은 분야에서 활용되고 있다. 인공신경망은 노드로 표현되는 인공 뉴런이 가중치를 가지는 링크로 연결되어 있는 망 (Network) 구조를 가지며, 입력 데이터를 받아들이는 입력층 (Input Layer), 처리된 결과가 출력되는 출력층 (Out Layer), 입력층과 출력층 사이에 위치해 외부로 보여지지 않는 은닉층 (Hidden Layer)으로 구성된다. 입력 데이터는 입력층을 통해 받아들여지며, 이렇게 입력된 데이터들은 은닉층을 지나면서 처리가 이루어지고, 출력층을 통해 최종 결과가 출력된다.

이렇게 입력층에서 시작된 정보가 출력층까지 순서대로 진행되는 인공신경망을 피드포워드 신경망 (Feedforward Neural Network, FNN)이라고도 한다. 입력층의 노드는 입력 뉴런 (Input Neuron)이라고 하고, 특별한 연산 없이 입력값을 그대로 출력시켜 은닉층으로 전달하기 때문에 입력 뉴런은 입력값 자체를 말하기도 한다. 이와 달리 은닉층과 출력층의 뉴런은 전달받은 데이터에 대해 특정한 연산을 수행하게 된다.

[그림 2] 인공 뉴런의 개념적 표현
은닉층과 출력층의 인공 뉴런은 링크를 통해 입력값을 받아 가중합을 구하고, 이 값을 활성화 함수 (Activation Function)에 적용하여 출력 신호를 내보낸다. 출력 신호는 최종적인 해 (Solution)이거나 다른 뉴런의 입력값이 된다. 여기서 활성화 함수는 뉴런의 활성화 여부를 판단하는 함수로 가중합이 활성화 함수가 가지고 있는 임계치보다 크면 뉴런은 활성화되고, 작으면 뉴런은 비활성화된다. 이러한 메커니즘은 인간의 뇌를 구성하는 신경 세포 뉴런이 전위가 일정치 이상이 되면 활성화되어 시냅스를 통해 신호를 전달하는 모습을 모방한 것이다. 이러한 뉴런의 동작 원리를 수식으로 나타내면 다음과 같다.

상기 수식에서 출력값으로 0과 1을 가지는 뉴런의 경우 가중합이 임계치(θ)를 넘으면 활성화되어 1을 출력하고, 임계치 이하면 비활성화되어 0을 출력한다. 오른쪽 식은 임계치를 0으로 표준화시키기 위하여 일정한 편향값 (Bias)으로 b를 삽입한 것이다. 편향은 뉴런이 얼마나 쉽게 활성화되느냐를 조정하는 활성화 가능도로서 항상 1을 출력하는 편향 노드로 표현된다. 이는 출력층을 제외한 모든 층에 포함되나 편의상 그림에서 표시하지 않는 경우도 많으므로 본서에서도 이후 그림에 편향 노드는 생략하기로 한다.
한편, 입력층과 출력층과는 달리 은닉층은 하나 이상의 층을 가질 수 있는데, 이렇게 은닉층의 개수가 많아져 깊어진 인공신경망을 딥러닝이라고 한다.
출력층은 인공신경망의 마지막 층으로서 최종적인 값을 출력한다. 출력층에서 사용되는 활성화 함수는 문제 유형에 따라 달라지는데, 일반적으로 수치 예측에는 입력을 그대로 출력하는 항등 함수 (Identity Function)를, 분류 예측에는 시그모이드 함수(이진 분류)나 소프트맥스 함수(다중 분류)를 사용하게 된다.
인공신경망은 대량의 데이터에 내재된 신호를 잡아내어 매우 복잡한 모형을 만들 수 있기 때문에 기존 모형으로는 예측하기 어려운 문제를 해결할 수 있으나, 하드웨어의 성능이 좋아야 하고, 학습 시간이 오래 걸리는 편이며, 인자의 튜닝이 비교적 까다롭다는 단점이 있다. 또한 은닉층에서 실제값은 기록되지 않아 분석자가 알 수 없기 때문에 출력값에 대한 논리적 추론이 불가능하다. 이렇게 모형의 출력값만 알고 분석과정을 사용자가 알 수 없는 모형을 블랙박스 모형 (Black Box Model)이라 한다. 아래의 표는 인공신경망의 장단점을 요약하고 있다.
[표 1] 인공신경망 모형의 장단점
| 장점 | 인공신경망 구조에서 각 뉴런은 하나의 독립 프로세스이므로 병렬 처리에 유리하다. |
| 적용 가능한 문제의 영역이 광범위하다. 즉, 입력변수의 형태에 의존적이지 않다. | |
| 복잡한 데이터 집합에 내재된 패턴을 찾아내는 능력이 있다. | |
| 많은 노드에 정보가 분산되어 있기 때문에 일부 노드에서 결함이 발생하더라도 전체 시스템에 큰 영향을 주지 않는다. | |
| 단점 | 블랙박스 모형이기 때문에 분류나 예측 결과만을 제공할 뿐 어떻게 그런 결과가 나왔는지에 대해 사용자가 알기 어렵다. |
| 복잡한 학습 과정을 거치기 때문에 최적의 모형을 구축하는 데 많은 시간이 소요될 수 있다. | |
| 은닉층의 과다 설정은 학습 데이터 집합과 거의 일치하는 모형을 유도해낼 수 있으므로 과잉적합 문제를 발생시킬 수 있다. |
[1] 퍼셉트론
퍼셉트론 (Perceptron)은 다수의 신호를 입력으로 받아 하나의 결합된 신호를 출력하는 모형으로서 인공신경망이 작동되는 원리를 제공하는 기본 알고리즘이다. 퍼셉트론은 층의 수에 따라 단층 퍼셉트론과 다층 퍼셉트론으로 구분할 수 있다.
(1) 단층 퍼셉트론
단층 퍼셉트론 (Single Layer Perceptron)은 입력층과 출력층만으로 구성되어 있다. 앞서 언급했듯이 입력층에는 어떠한 연산도 일어나지 않기 때문에 단층 퍼셉트론은 출력층에 속하는 하나의 뉴런만을 사용하므로 인공 뉴런의 수학적 모형을 일컫는 용어로 사용되기도 한다.
[그림 3] 단층 퍼셉트론의 개념적 표현
단층 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다. 그 중 일반적으로 사용하는 것은 헤비 사이드 계단 함수 (Heaviside Step Function)이며, 종종 부호 함수 (Sign Function)를 사용하기도 한다. 각 함수의 일반적인 모형은 다음과 같다.

- z는 가중합을 의미한다.
(2) 다층 퍼셉트론
단층 퍼셉트론은 일종의 선형 분류기이기 때문에 분류 예측 문제에서 복잡한 식별 경계를 만들 수 없다. 즉, 단층 퍼셉트론 모형으로는 선형 분리가 불가능한 배타적 논리합 XOR (eXclusive OR) 분류 문제를 해결할 수 없다. 여기에서 XOR 문제는 다음과 같이 배타적인 두 개의 명제 가운데 하나만 참일 경우만 결과를 참으로 판단하는 논리합 연산이다.
[표 2] XOR 문제
| x1 | x2 | XOR |
| 0 | 0 | 0 (-) |
| 0 | 1 | 1 (+) |
| 1 | 0 | 1 (+) |
| 1 | 1 | 0 (-) |
이러한 XOR 문제는 [그림 10-4]와 같이 (+), (-)를 직선(선형)으로 분리할 수 없다.

[그림 4] 선형 분리가 불가능한 XOR 문제
이러한 문제를 해결하기 위해 고안된 것이 다층 퍼셉트론이다. 다층 퍼셉트론 (Multi Layer Perceptron, MLP)은 말 그대로 여러 개의 퍼셉트론을 쌓아 올려 다층의 퍼셉트론을 만든 것으로서 입력층과 출력층 사이에 중간층인 은닉층을 추가한 것이다. 보통 인공신경망은 다층 퍼셉트론을 의미하기도 한다.

[그림 5] 다층 퍼셉트론
[표 3]은 다층 퍼셉트론을 이용하여 XOR 문제를 해결하는 개념적 과정을 나타내고 있다. 은닉노드 h1은 x1, x2의 1(True)에 대한 논리곱(AND)에 의한 결과값을 산출하고, 은닉노드 h2는 x1, x2의 0(False)에 대한 논리곱에 의한 결과값을 산출한다. 다시 y는 은닉노드 h1과 h2의 0에 대한 논리곱 결과값을 산출하여 이 결과를 XOR 문제의 최종 해로 결정하게 된다.
[표 3] 다층 퍼셉트론을 이용한 XOR 문제
| x1 | x2 | h1 | h2 | y | XOR |
| 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 | 0 | 0 |
인공신경망이 발전함에 따라 다층 퍼셉트론에는 계단 함수 외의 다양한 비선형 활성화 함수가 도입되었다. 다층 퍼셉트론이 사용하는 대표적인 비선형 활성화 함수는 다음과 같다.
- 시그모이드 함수 (Sigmoid Function)
시그모이드 함수는 앞서 로지스틱 회귀모형에서 다루었던 대표적인 비선형 활성화 함수로서 입력값을 0과 1 사이의 값으로 변환해준다. 시그모이드 함수는 계산이 쉽고, 해석이 용이해 가장 기본적으로 사용되는 활성화 함수이다.

[그림 6] 시그모이드 함수
- 하이퍼볼릭 탄젠트 함수 (Hyperbolic Tangent Function, Tanh Function)
Tanh 함수는 스케일이 조정된 시그모이드 함수로서 입력값을 -1과 1 사이의 값으로 변환해준다. Tanh 함수는 은닉층에서 활성화 함수로 자주 사용되며, 조금 더 극단적인 분류가 이루어지므로 실제 분류 예측 문제에 있어서 더 선호된다.

[그림 7] 하이퍼볼릭 탄젠트 함수
- 렐루 함수 (Rectified Linear Unit Function, ReLU Function)
ReLU 함수는 은닉층에서 가장 많이 사용되는 활성화 함수로서, 입력값이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하일 경우는 0을 출력해주는 함수이다. ReLU 함수는 0을 출력하는 경우를 제외하고, 강제적인 수치 변환이 이루어지지 않으므로 학습이 훨씬 빨라지며, 비용이 크지 않고 구현이 매우 간단하다는 장점이 있다.

[그림 8] 렐루 함수
[2] 오차 역전파법
오차 역전파법 (Back Propagation)은 인공신경망이 학습하는 메커니즘을 설명하는 알고리즘으로서 모형의 오차를 최소화하기 위해 출력층부터 입력층까지 역의 방향으로 오차를 전파하며 가중치와 편향을 조정해 나간다.
아래 그림에서 보는 바와 같이 인공신경망은 입력층에서 출력층 방향으로 데이터를 처리하며 그 결과를 차례로 전파하는 순전파 (Forward Propagation)를 통해 예측값을 출력하며, 예측값과 실제값을 비교하여 발생한 오차값을 이용하여 다시 역방향으로 가중치를 수정해 나간다.

[그림 9] 오차 역전파법을 이용한 학습 메커니즘
인공신경망에서 오차를 계산할 때 사용되는 대표적인 손실 함수는 다음과 같다.
- 평균제곱오차 (Mean Squared Error, MSE)

주로 수치를 예측할 때 사용되는 손실 함수로 실제값(y)과 예측값(y)의 차이를 제곱한 값의 평균을 나타낸다. 손실 함수의 값이 최소화될수록 최적화된 모형이므로 MSE를 최소화하는 방향으로 모형이 학습된다.
- 교차 엔트로피 오차 (Cross Entropy Error, CEE)

교차 엔트로피 오차는 종속변수가 범주형일 때 주로 사용되는 손실 함수이다. 위 식에서 y는 원핫인코딩된 범주이고, yi는 특정 범주에 속할 확률이다. 만약, 이진 분류의 경우y=[1, 0], y=[0.7, 0.3]과 같이 처리되며, 결과적으로 예측값이 클래스 1에 속할 경우를 제외한 나머지는 무조건 0이 나오므로 CEE는 클래스 1에 속할 확률에 대한 자연로그를 계산하는 식이 된다. 따라서 확률이 낮을수록 CEE 값은 커지기 때문에 MSE와 마찬가지로 CEE를 최소화하는 방향으로 모형이 학습된다.
오차 역전파법은 이러한 손실 함수 값이 최소가 되는 가중치와 편향을 찾는 방법이다. 대부분의 인공신경망 알고리즘은 가중치 갱신을 위해 경사하강법 (Gradient Decent)을 사용하는데, 이는 손실 함수의 기울기가 가장 완만해지는 지점을 찾아가는 최적화 방법이다. 수학적으로 설명하자면, 가중치 w에 대해 편미분하여 현재 w위치에서의 접선의 기울기를 구한 다음 기울기를 낮은 방향으로 조금씩 이동시켜서 경사가 가장 완만해지는(기울기가 가장 작아지는) 지점에 이를 때까지 반복하게 된다.

[그림 10] 경사하강법의 개요
이러한 경사하강법을 수식으로 나타내면 다음과 같다.
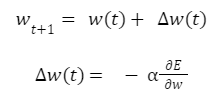
wt+1는 초기 가중치 wt에 손실 함수 E에 대해서 w로 편미분한 값 ∆w(t)를 더하여 갱신한 가중치를 의미한다. 여기에서 는 학습률 (Learning Rate)을 의미하는데, 학습률의 크기에 따라 전역 최솟값에 도달하는 이동거리가 달라지므로 결국 가중치 갱신의 크기를 조절하게 된다.

[그림 11] 학습률 크기에 따른 경사하강법
학습률이 작으면 안전하게 전역 최솟값에 도달하지만 반복 횟수가 많아져 계산 시간이 오래 걸리는 단점이 있으며, 반대로 학습률이 높으면 한 번에 학습되는 이동 거리가 커서 전역 최솟값을 쉽게 찾지 못하는 단점이 있다.
인공신경망도 다른 머신러닝 모형과 마찬가지로 모형이 학습 데이터에 과잉적합 되는 것을 막기 위해 일정 단계에 도달했을 때 학습을 정지시킬 수 있는 기준이 필요한데, 인공신경망에서는 최소 정확도, 최소 오차 변화율, 최대 훈련 반복 수, 최대 훈련 시간 등을 고려할 수 있다.
1. RNN
1) Sequential Model
Sequential Model, 특히 순서가 중요한 데이터(예: 시계열 데이터)를 다루는 모델은 순차적으로 다음 데이터를 예측하기 위해 이전 데이터에 의존하는 특성을 가진다. 예를 들어, 주가 예측이나 자연어 처리처럼 현재 또는 미래의 상태가 과거의 데이터를 기반으로 결정되는 경우가 있다.
Naive Sequential Model의 경우, 예측을 위해 사용되는 입력 데이터의 길이가 시간이 지남에 따라 점점 길어지는 문제가 발생한다. 현재 시점에서 예측을 하려면 초기 시점부터 현재 시점까지 모든 데이터를 고려해야 하기 때문에 시간이 지날수록 데이터가 축적되어 입력 길이가 길어지게 된다. 이렇게 입력 데이터의 길이가 늘어나면, 고정된 입력 크기를 가정하는 다른 모델과는 달리 Sequential Model에서는 일정한 입력 크기를 유지하기 어렵다.
이를 해결하기 위해 순환신경망(RNN)이나 LSTM, GRU 같은 모델들이 고안되었으며, 이러한 모델들은 과거 데이터를 고정된 크기의 상태(state)에 압축하여 기억하는 방식으로 입력 길이 문제를 해결해 나간다. 이를 통해 Sequential Model에서도 효율적인 예측이 가능하도록 한다.

2) Auto Regressive Model
첫번째는 과거 데이터를 다 보지말고 지금으로부터 개 전까지의 데이터만 보는 것이다. 그러면 input으로 넣는 길이를 고정할 수 있는데, 슬라이딩 윈도우 기법이 한 예시이다. 이 방법에서는 "지금으로부터 τ개 전까지의 데이터" 만을 사용하여 입력 길이를 고정한다. 이를 통해서 예측 시 매번 고정된 길이의 데이터만 모델에 입력할 수 있게 된다. 구체적인 예로 주가 예측 모델을 생각해보자. 과거의 모든 데이터를 보지 않고 최근 τ=5일 동안의 주가 데이터만 사용해 다음 날 주가를 예측하려고 한다고 가정하자.
- 처음 τ 일 동안의 데이터만 사용한다면, 첫 번째 예측은 1일부터 5일까지의 데이터를 이용해 6일차 주가를 예측하는 식이 된다.
- 그다음 예측에서는 2일부터 6일까지의 데이터로 7일차 주가를 예측한다. 이전 데이터의 모든 시점을 보는 대신 최근 τ 개의 데이터만 활용하는 방식으로 계속 창(window)을 밀어가며 예측하는 것이다.
이렇게 하면 입력 길이는 항상 τ=5로 고정되기 때문에 입력 길이 문제를 해결할 수 있다. 다만, 이 방법의 단점은 시간 축에서 더 먼 과거 데이터를 무시하게 되므로, 매우 장기적인 트렌드나 패턴을 반영하기 어렵다는 것이다. 하지만 특정 시간 범위 내의 단기적인 패턴을 예측하는 데에는 효과적이며, 이를 통해 예측의 복잡성과 모델 학습의 효율성을 높일 수 있다.

τ가 1인 경우, 즉 바로 이전 데이터 한 개만을 사용하는 모델인 Markov Model도 이에 해당한다. Markov 가정(Markov Assumption)은 현재 상태가 주어지면, 과거의 상태가 주어졌을 때 미래의 상태는 현재 상태에만 의존한다는 원리를 기반으로 한다. 즉, 미래의 상태는 현재의 상태에만 의존하고, 그 이전의 상태들은 더 이상 고려하지 않는다는 것이다.
Markov 모델에서 현재 상태 St가 주어졌을 때, 미래 상태 St+1는 과거 상태 St−1와 무관하고, 오직 St에만 의존한다고 가정한다. 이는 수식으로 표현하면 다음과 같다.

즉, 미래 상태 St+1의 확률 분포는 현재 상태 St만을 기반으로 결정된다. 과거 상태들은 현재 상태를 알면 영향을 미치지 않는다고 가정한다. Markov 가정을 기반으로 하는 모델에서는 joint distribution을 간단하게 표현할 수 있다. 예를 들어, 일련의 상태 S1,S2,…,STS_1, S_2, \dots, S_T에 대해 전체 확률 분포를 고려할 때, Markov 가정을 적용하면 각 상태의 분포는 현재 상태와 이전 상태들만을 고려하게 된다.

여기서 각 상태는 이전 상태에만 의존하고, 그 이전 상태들은 고려하지 않기 때문에, joint distribution을 간단하게 표현할 수 있다. 이를 통해 모델의 계산 복잡도를 크게 줄일 수 있으며, 수학적으로 다루기가 매우 쉬워진다.
Markov 모델은 Generative Model에서 많이 활용된다. Generative Model은 데이터를 생성하는 과정을 모델링하는 데 사용되며, 이 모델은 특정한 상태가 주어졌을 때 그 다음 상태가 어떻게 변화할지에 대한 규칙을 학습하고, 이를 기반으로 새로운 데이터를 생성한다. 예를 들어, Hidden Markov Model(HMM)은 감지할 수 없는 상태들이 순차적으로 발생하는 과정을 모델링하는 데 사용된다. 이 모델은 각 시점에서 상태가 어떤 확률 분포를 따르는지, 그리고 각 상태에서 관측된 데이터가 어떤 확률 분포를 따르는지를 학습하여, 상태의 변화를 예측하거나 새로운 데이터를 생성할 수 있다. Markov 가정을 통해 모델이 더 간단해지고 계산 효율성이 높아지기 때문에, 이러한 모델들은 많은 실험적 환경에서 매우 유용하게 사용된다.

이렇게 과거의 일부만 보는 방식은 input의 크기를 고정할 수 있고, joint distribution을 쉽게 표현할 수 있다는 장점이 있다. 하지만 우리가 선택한 과거보다 더 과거의 정보가 중요함에도 그 정보가 버려질 수 있고, 바로 가까운 과거 정보에만 의존하는 문제가 발생할 수 있다.
3) Latent Auto Regressive Model
과거의 정보를 압축하여 하나의 데이터로 받는 아이디어가 등장했다. 이는 latent autoregressive model이라고 불린다. 이 모델은 과거 데이터를 모두 직접적으로 사용하는 대신, 과거의 정보를 요약하거나 압축하여 하나의 잠재 변수(latent variable)로 만든 후 이를 기반으로 다음 데이터를 예측하는 방법이다. 마치 여러 개의 파일을 하나의 압축된 파일로 받는 것처럼, 이 모델은 과거의 상태들을 모두 저장하지 않고, 중요한 정보만을 압축하여 다음 시점의 예측에 사용한다.
latent autoregressive model에서 중요한 점은, 이 압축된 정보가 바로 latent state로 표현된다는 것이다. 모델은 이 잠재 상태를 통해 과거의 중요한 패턴이나 특징을 모두 담아내며, 그 정보만을 가지고 예측을 수행한다. 이렇게 함으로써, 모델은 입력 크기를 고정하면서도 시간의 흐름에 따른 데이터를 효과적으로 처리할 수 있다.
이를 통해 모델은 계산 효율성을 높일 수 있고, 더 긴 시계열 데이터를 처리할 때 발생할 수 있는 문제를 완화할 수 있다. 예를 들어, Recurrent Neural Networks (RNN) 또는 Long Short-Term Memory (LSTM) 네트워크에서의 hidden state가 이러한 압축된 정보 역할을 한다. 과거 데이터를 모두 기억하는 대신, 중요한 정보만을 요약하여 효율적으로 예측을 할 수 있는 것이다.
결국, latent autoregressive model은 Markov 모델에서의 상태 전이 문제를 해결하고, 과거 데이터를 압축하여 중요한 정보만을 담은 상태를 생성하는 방법으로, 더 복잡한 시계열 예측 문제나 생성 모델에서 매우 유용하게 활용될 수 있다.

4) RNN 소개
RNN(Recurrent Neural Network)은 Latent Autoregressive Model의 한 예로, 순차적인 데이터를 처리하는 모델이다. RNN은 **현재의 입력 값 xtx_t**과 **과거 데이터의 압축된 정보 ht−1h_{t-1}**를 함께 받아들여, **다음 출력 값 yty_t**을 예측한다. 이 때 ht−1h_{t-1}는 과거의 정보를 요약하여 압축한 잠재 상태로, 이전 시점까지의 데이터에서 중요한 패턴이나 특징을 보존하고 있다.
RNN의 핵심 아이디어는 순차적인 정보를 처리하면서 각 시점의 출력을 예측할 때, 과거의 정보와 현재의 입력을 모두 활용한다는 점이다. 이를 위해 RNN은 두 가지 주요 요소를 처리한다:
- 현재 입력 값 xtx_t: 모델이 예측을 할 때, 현재 시점에서 제공되는 데이터이다. 예를 들어, 자연어 처리에서 현재 단어가 될 수 있다.
- 과거 데이터의 압축된 정보 ht−1h_{t-1}: 이전 시점에서 모델이 기억하고 있던 중요한 정보로, 이전 데이터들을 압축하여 생성된 잠재 상태이다. 이 정보는 RNN 내부에서 계속 업데이트되며, 시간이 지남에 따라 점차적으로 과거의 중요한 특징을 반영한다.
RNN은 순환 구조를 통해 **예측된 출력 yty_t**을 다시 다음 단계로 전달한다. 이 출력은 현재 입력 값과 과거의 압축된 정보가 모두 포함되어 있기 때문에, 모델은 미래 예측 시점으로 이동할 때마다 이전의 정보들을 계속적으로 반영할 수 있다. 즉, RNN의 출력 값은 현재 입력과 과거 정보가 결합되어, 다음 시점의 예측에 사용되며, 이전 시점의 예측도 계속 업데이트되면서 모델을 개선해 나간다.
이와 같은 구조 덕분에 RNN은 시간에 따른 데이터의 패턴을 잘 학습할 수 있으며, 시계열 예측이나 자연어 처리, 음성 인식 등 다양한 순차적 데이터 처리에 유용하다. RNN은 계속해서 과거의 정보를 압축하고 업데이트하면서, 이전의 상태들을 점진적으로 기억하고 반영하므로, 점차적으로 데이터의 시간적 의존성을 이해할 수 있다.

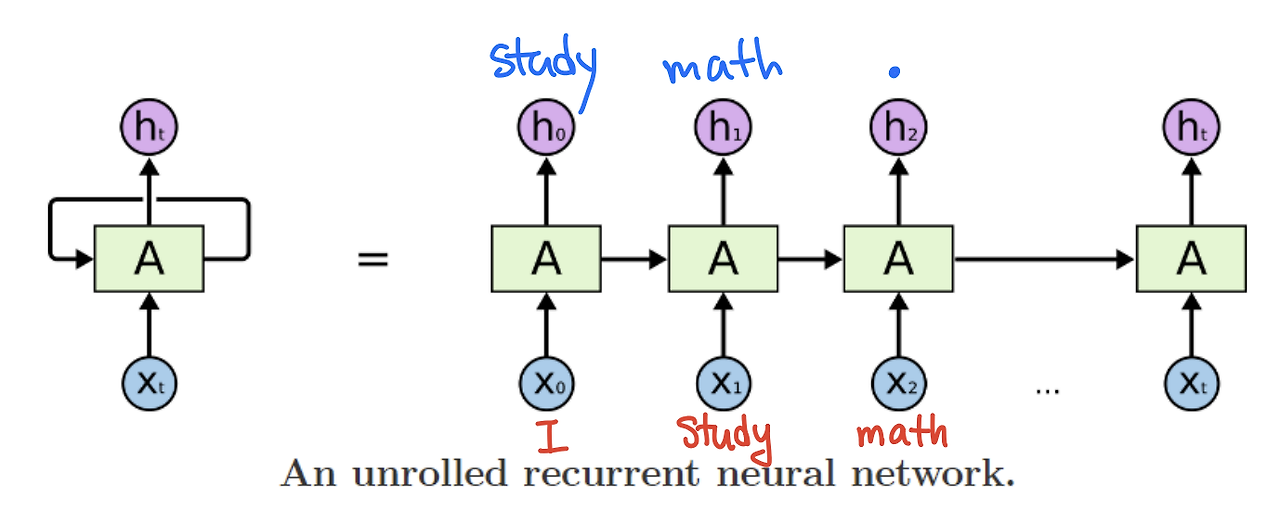
자연어 처리(NLP)에서는 언어의 어순과 문맥이 중요한 순차적 데이터로 취급되기 때문에, RNN(Recurrent Neural Network) 기반 모델이 많이 사용되었다. RNN은 주어진 입력 데이터를 처리하면서, 이전에 발생한 정보도 함께 기억하며 처리하는 특성 덕분에 자연어와 같은 순차적 데이터를 다루는 데 유용하다. 특히, 문장의 생성 과정에서 각 단어는 그 앞선 단어와 문맥에 따라 결정되므로, RNN은 이를 모델링하는 데 매우 적합하다.
예를 들어, "I study math."라는 문장을 생성하려면, 모델은 각 단어를 차례로 예측해야 한다. 첫 번째 단어인 "I"를 모델에 입력하면, 모델은 다음에 올 단어 "study"를 예측한다. 그 후, "study"를 입력으로 넣으면, 모델은 그 다음에 올 단어 "math"를 예측하고, 마지막으로 "math"를 입력으로 넣으면 문장의 끝을 나타내는 마침표 "."를 예측할 수 있다. 이처럼 RNN은 순차적인 예측을 통해 문장을 생성하는 방식으로 작동한다.
이 과정에서 RNN은 각 시점에서 입력된 단어와 그 이전의 정보를 기반으로 다음 단어를 예측한다. 모델은 문맥을 이해하면서 점차적으로 문장을 완성해 나가며, 어순과 문법 규칙을 학습하여 자연스러운 문장을 생성하는 데 사용된다. 따라서 RNN은 자연어와 같이 시간에 따라 변화하는 정보를 다루는 데 강점을 가지며, 문맥을 반영한 단어 예측을 가능하게 한다.
하지만 RNN은 긴 문장이나 문맥을 다루는 데 어려움이 있었고, 이를 개선하기 위해 Transformer 모델이 등장하였다. Transformer는 병렬 처리와 더 긴 범위의 문맥을 처리할 수 있어, 자연어 처리에서 큰 혁신을 일으켰다. 그럼에도 RNN 기반 모델은 여전히 많은 NLP 문제에서 유용하게 사용되고 있다.
- RNN을 구성하는 요소(벡터)들은 다음과 같다.

- 현재 time step을 t라고 하면, 은 이전 hidden-state vector로 과거 정보들을 가지고 있다.
- 는 현재 time step에 들어오는 input vector이다.
- 는 현재 time step에서 내뱉는 사실상 output vector이다. 는 과거 정보와 현재 input의 정보를 합쳐서 input으로 받는 친구이다. 즉 와 를 합쳐서(concat) 선형변환()을 한 결과이다.
- 마지막으로 는 우리가 보고자 하는 결과값으로, 를 원하는 형태로 지지고 볶아서(?) 나오는 결과이다.
task에 따라 매 time step 마다 나오기도 하고 마지막 time step에만 나오기도 한다.
(예시. 품사예측 - 단어마다 예측해야 하므로 매 time step마다 결과가 나옴 /
문장 긍정, 부정 판단 - 문장이 끝나는 time step에서만 결과가 나오면 됨)
- RNN에서 중요한 점은, 매 time step 마다 같은 함수와 같은 파라미터를 사용한다는 것이다. 즉 하나의 linear transform matrix만 사용되며 매 time step은 파라미터를 공유한다.
- hidden states 계산과 파라미터 수를 더 자세히 생각해보자.
- embedding vector 의 차원을 3, 의 차원을 2라고 생각하자.
(를 input vector로 이해해도 되지만,
엄밀히 말하면 input vector에서 embedding과정을 한 번 거친 벡터를 말한다) - 먼저 와 를 concat한다(아래 그림에서 가장 오른쪽 부분) -> 그렇게 concat한 벡터는 차원이 5
- 이 concat한 벡터에 linear tranformation을 적용해서 차원을 만들어준다.
-> 차원도 2이므로 linear transform matrix(W)의 차원은 (2 x 5) - 여기에서 W를 각각 와 에 대해 쪼개서 생각하면,
에는 가 적용되고(초록색 글씨) 에는 가 적용되는 것이고, 위에처럼 한 번에 계산하는 것은 이 둘을 더한 것과 같다. - 그 뒤 계산된 +에 non-linear activation인 tanh를 씌우면 이 된다.
- 마지막으로 는 를 linear transform() 해서 만들 수 있다.
- 여기에서 bias가 없다고 하면 모델의 파라미터 수(제외)는 transform matrix(W)의 차원 수(10)와 동일하다.
(는 원하는 output 형태에 따라 다르므로 고려하지 않았다. output 형태도 알면 총 파라미터 수를 구할 수 있다.)
- embedding vector 의 차원을 3, 의 차원을 2라고 생각하자.
6) Type of RNNs
- RNN은 input과 output의 개수와 출력 시점에 따라 크게 5종류가 있다.
- one to one

- input 하나, output 하나
- 사실상 sequence가 아닌 형태
- 그냥 기본 input, output 형식. time step도 아님
- one to many

- input 하나 output 여러 개
- 예시 ) 이미지를 input으로 넣으면 이미지에 대한 설명글이 나오는 모델
- 처음에 이미지를 넣고 나서 다음 sequence에는 0으로 채워진 텐서를 input으로 넣는다.
-> (그래도 괜찮나..?)
- many to one

- input 여러개 output 하나
- 예시) 문장을 넣고 그 문장의 긍정/부정 판단
- many to many(input 먼저 output 나중)

- input 여러개 output 여러개
- input을 차례로 받고 나서 output 차례로 내보냄
- 예시) 기계 번역
- 질문 ) 기계 번역은 동시에 하면 안되나..? -> 문맥을 고려해서 번역해야 하므로 먼저 input 받고 하는 것 같다..(나는 차를 마시고 그녀에게 차였다.) transformer를 보면 입력 출력이 두 개로 분리가 되는 것 자체가 장점인 것 같기도 하다
- many to many(input과 output 동시에)
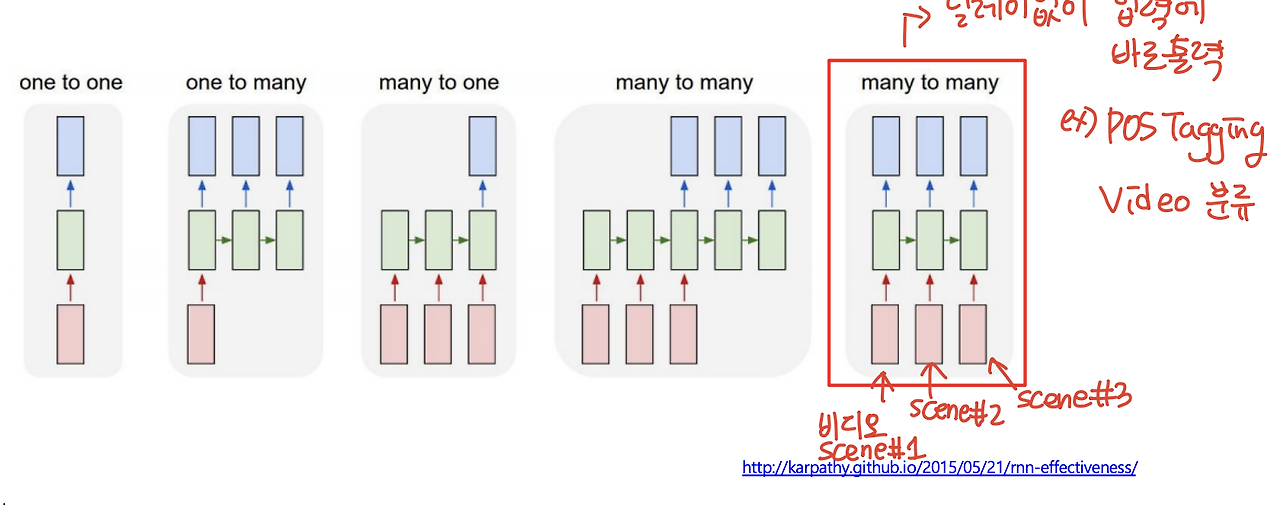
- input 여러개 output 여러개
- 딜레이 없이 넣으면 바로 출력
- 예시) 품사 분석, POS Tagging, Video scene 분류하기
7) Character-level language Model
- 단어가 아닌 문자 단위로 Language Model을 구축한다고 생각해보자.
- "hello"가 있으면 -> Vocabulary : [h, e, l, o]
- "hello"를 가지고 학습한다고 생각하면,
- "h"가 들어가면 "e"가 나오고, "e"가 들어가면 "ㅣ"가 나오고...이런식으로 다음 문자를 예측한다.
- 참고로 처음에는 이전 hidden state이 없기 때문에 0으로 채워진 hidden vector를 hidden state로 사용한다.

- output은 hidden vector에 linear transform을 취해 구하게 되고, 단어 [h, e, l, o] 중에 ground truth의 확률을 높이기 위해 softmax loss를 사용해 학습한다.
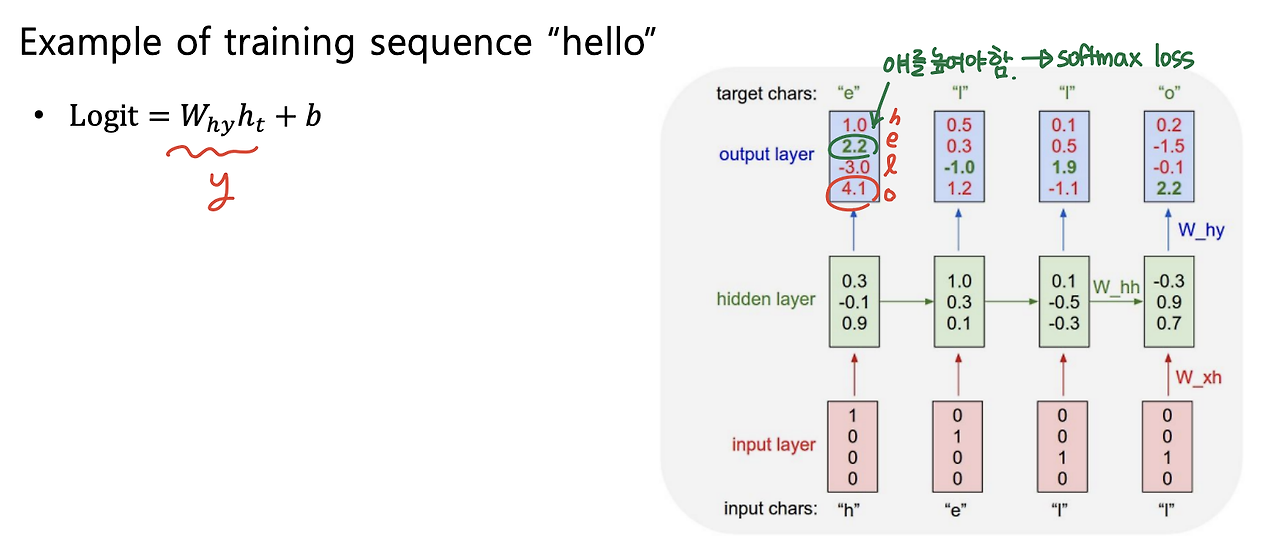
- 학습이 끝나고 inference단계에서는 아래 그림과 같이 output 값이 다음 input으로 들어가서 예측을 하는 형식으로 진행된다.

8)trained RNN이 할 수 있는 것
- 셰익스피어 희곡을 학습하고 희곡을 쓸 수 있음
- 대화문을 읽고, 대화문을 생성해낼 수 있음(왼쪽이 원래 대화문, 오른쪽이 RNN model로 생성한 대화문)

- 논문을 쓸 수 있음
- C code를 짤 수 있음
(출처 : http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
9) BPTT(Backpropagation Through Time)
- RNN의 backward 방식
- forward할 때 전체 sequence에 대해 loss를 저장했다면, backward에서도 gradient 구하기 위해 전체 시퀀스를 고려해야 함

- 그런데 시퀀스가 너무 긴 경우에는 시퀀스를 작은 단위로 나눠서(chunk) forward와 backward를 할 수도 있다.

10) How RNN works
- RNN이 학습할 때 hidden state가 정보를 어떻게 저장하고 있는지 확인
- hidden state 벡터에서 찾고자 하는 정보가 어디에 있는지를 역추적하는 방식으로 분석을 수행(예를 들어hidden state가 3차원이라고 하면 띄어쓰기에 대한 정보는 3개 중 어디에 있는지를 역추적)
- 즉, hidden state 의 차원하나를 고정하고 그 값이 학습 진행에 따라 어떻게 변하는지를 분석함으로써 RNN 특성을 분석할 수 있다.
- 파랑은 특정 위치의 hidden state 값이 음수, 빨강은 값이 양수
- Quote Detection cell
- 문장에서 큰 따옴표부터 그 사이에서는 값이 음수이고 다른 구간에서는 양수인 것을 볼 수 있다.

- 문장에서 큰 따옴표부터 그 사이에서는 값이 음수이고 다른 구간에서는 양수인 것을 볼 수 있다.
- If statement cell
- If 구문에서만 값이 양수이다.

- If 구문에서만 값이 양수이다.
- 즉 hidden state에서 시퀀스의 특징 및 패턴을 저장하고 있는 것을 알 수 있다.
9) Vanilla RNN의 한계
- Vanilla RNN에서는 계속 이전 정보에 linear transformation을 하고 activation 함수를 씌우는 방식으로 hidden state를 업데이트한다. 그렇기 때문에 linear transformation과 activation 함수가 계속 곱해진다.
- 그렇기 때문에 back propagation을 할 때에도 계속 gradient 값을 곱하게 된다.
- 이 경우, 계속 곱해지는 값이 1보다 작으면 전체 값은 0으로 수렴하고 / 1보다 크면 무한히 발산하는 문제가 발생하는데 이러한 문제를 gradient vanishing / gradient exploding이라 한다.
- gradient exploding이 일어나면 loss 값이 수렴되지 않으므로 학습이 진행되지 않고, gradient vanishing 문제가 일어나면 업데이트를 하는 항이 0에 수렴하므로 파라미터 업데이트가 되지 않는다. 즉 얘도 학습이 진행되지 않는다.
- tanh, sigmoid의 gradient 값은 0에서 1사이 이므로 gradient vanishing 문제가 일어날 확률이 높고, ReLU를 사용하면 gradient exploding이 일어날 수 있다.
- 값을 계속 곱해나가기 때문에 발생하는 문제이므로, 이를 해결해야 한다.

2. LSTM(Long Short Term Memory)
1) LSTM Intro
- Core Idea : transformation 없이 바로 cell state 정보를 보내자
- Long-Term Dependency(장기 의존성) 문제를 해결하는 것이 목표
- 장기 의존성
시퀀스 데이터는 문맥(context) 의존성을 가진다.
아래와 같은 예문을 살펴보자.
"나는 그제 가족과 함께 광화문 광장에서 즐겁게 놀았다"
이 문장의 핵심인 '나는'과 '놀았다'는 7이라는 시간 차이를 두고 서로 의존성을 갖는다.
이와 같이 대부분의 시퀀스 데이터에서 요소들은 각기다른 시간 차이를 두고 서로 관련성을 갖고있다.
관련된 요소가 멀리 떨어져 있는 경우 시퀀스에 장기 의존성이 존재한다고 한다.
(출처)
- 장기 의존성
- 즉, 계속 1보다 작은 값을 곱해감으로써 과거 데이터를 많이 잊어버리는 RNN의 문제를 해결하는 것에 집중
2) RNN vs LSTM
- RNN
- LSTM
- -> (cell state)가 추가됨!
- : 과거 정보를 가지고 있는 온전한 정보
- : 를 한 번 더 가공한 정보, 에서 다음으로 보낼 정보만 빼내서 가져온 정보
3) LSTM Gate
- LSTM에는 4개의 gate라는 것이 존재한다.

- 먼저 input과 이전 hidden state를 concat하고 선형변환해서, 그것을 gate에 따라 4등분하고 각각 sigmoid 또는 tanh를 씌운다.
- 4개의 gate는 각각 input gate, forget gate, output gate, gate gate이다.
- 이 때 sigmoid함수는 0~1사이의 함숫값을 가지므로 과 곱해지면 값의 일부를 가져오는 것과 같은 효과를 낸다. 따라서 sigmoid가 붙은 gate들은 정보에서 일정 비율의 정보만 가져오는 역할을 한다.
- tanh는 -1~1 사이의 함숫값을 가지고, hidden을 유의미한 정보로 만들기 위해 쓰인다. Gate gate에 사용된다.
- 그럼 이제 하나씩 살펴 보자.
- f : Forget gate, Whether to erase cell
- forget gate는 이전 hidden state()와 input()을 concat하고 선형변환한 후(bias가 있으면 더하기), sigmoid를 씌워 0~1사이 값으로 만든 벡터이다.
- 이후 forget gate는 이전의 cell state()에 곱해져서 이전 정보에서 몇 퍼센트를 기억할 것인지(=몇퍼센트를 잊어버릴 것인지)를 정하게 된다.
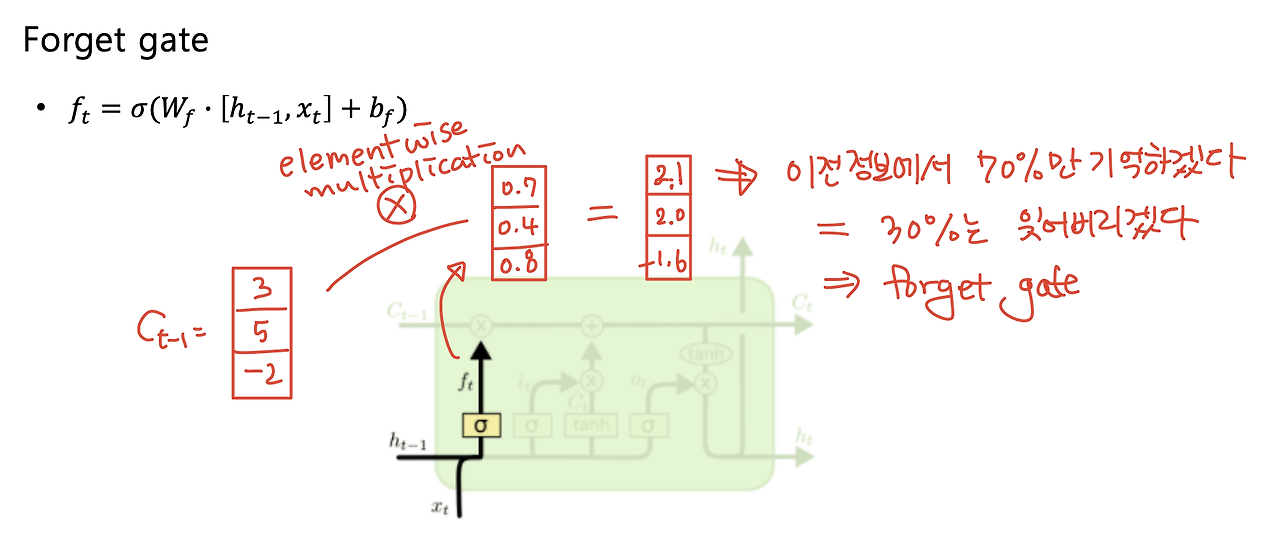
- i : input gate, Whether to write to cell & g : Gate gate, How much to write to cell
- input gate와 gate gate는 서로 곱해지는 친구들이다.
- gate gate를 먼저 보면, hidden state()와 input()을 concat하고 선형변환한 후(bias가 있으면 더하기) tanh를 씌운 결과이다. (아래 그림의 ) gate gate는 앞에서 forget gate와 곱해진 의 현재 정보 버전이라고 생각하면된다.
- input gate는 forget gate와 유사한 역할을 한다. 즉 forget gate가 과거의 정보 중 뭘 기억하고 뭘 잊어버릴지 그 비율을 정해주는 것이라면, input gate는 현재의 정보를 얼마나 가져갈지를 정한다.
- 따라서 (현재 time step의 cell state) = (과거 정보의 일부) + (현재 정보의 일부)로 표현되며, 이를 수식으로 표현하면 이다.

- o : Output gate, How much to reveal cell
- 위에서 구한 현재 time step의 cell state()는 현재 time step에서 기억할 모든 정보를 가지고 있다.
- output gate는 에서 또 한 번 필요한 정보만 필터링하기 위한 gate로,
forget gate와 input gate와 유사한 역할을 한다. - 따라서 우리가 출력형태로 내보낼 값인 는 에 tanh를 씌운 결과에 output gate를 곱하여 구해진다. 즉, 의 정보중 output gate에서 주어진 일정 비율만을 가져온 값이 이다.

- f : Forget gate, Whether to erase cell
3. GRU(Gated Recurrent Unit)
1) GRU
- LSTM에서 은닉 상태를 업데이트하는 계산을 줄여서 네트워크 구조를 단순화한 모델
- LSTM보다 적은 메모리의 요구량과 빠른 수행시간을 특징으로 한다.
2) LSTM vs GRU
- LSTM
- , 존재
- input gate, forget gate
- GRU
- 로 합쳐버림(GRU의 는 LSTM의 와 유사)
- input gate()만 사용, forget gate는 ()로 대체
-> input gate와 forget gate가 독립적이지 않고, 하나가 커지면 하나가 작아짐
-> 현재 정보를 많이 챙길수록 과거 정보를 많이 못 가져감
4. Backpropagation in LSTM & GRU
- Vanilla RNN에서는 를 계속 곱하는 식으로 과거의 정보를 저장했다.
- 하지만 LSTM, GRU에서는 정보를 담는 vector가 update되는 과정이 이전 time step의 cell state vector에서 일정 비율을 가져오고(forget gate, input gate, output gate등 곱하기), 필요로 하는 정보는 곱셈이 아닌 덧셈을 통해 연산해준다는 점에서 gradient 문제를 해결할 수 있다.
- 덧셈 연산은 역전파를 수행할 때 gradient를 복사해주는 효과가 있기 때문에 멀리 있는 time step까지 gradient를 큰 변형 없이 전달 가능하다.
https://velog.io/@leejy1373/Deep-learning-%EA%B8%B0%EC%B4%88-8.-Sequential-Models-RNN
시계열 데이터를 효율적으로 처리하는 방법은 지난 몇 년 동안 빠르게 발전했습니다. 특히, CMU에 계신 Albert Gu 교수님은 긴 시계열 의존성(Long-Range Dependencies, LRDs)을 처리하는 데 집중한 HiPPO(2020), LSSL(2021), 그리고 S4(2022)와 같은 연구들을 하고 계십니다.
이번 글에서는 연구의 흐름과 각 모델의 기술적 배경과 주요 기여를 설명하고, 어려운 개념들을 풀어봅니다. 이미지들은 아래 Reference에 적어둔 강의, 블로그 또는 논문에에서 발췌하여 편집 또는 사용하였습니다.
Background
1. Sequence Modeling의 필요성
Sequence Modeling은 시간에 따라 변화하는 데이터를 분석하고 예측하는 기술로 음성 인식, 금융 시계열 분석, 바이오 신호 분석 등에 널리 사용된다. 금융 시계열 분석에서는 주식 가격이나 환율 등의 변동을 예측하는 데 사용되며 과거의 가격 데이터를 바탕으로 미래의 가격을 예측하는 데 이용하며 생체 신호 분석에서는 심전도(ECG)나 뇌파(EEG) 데이터를 처리하여 건강 상태를 모니터링하거나 질병을 조기에 진단하는 데 활용된다. 특히 긴 시퀀스 데이터를 다룰 때, 기존의 모델들은 시퀀스 길이가 길어질수록 중요한 정보를 놓치거나 처리 속도가 느려지는 문제를 겪을 수 있기 때문에 이를 해결하기 위한 기술들이 필요하다.

2. Sequence Modeling의 주요 과제
긴 시퀀스를 다룰 때 중요한 두 가지 과제가 있다. 첫째, 데이터의 시간적 연속성을 유지하면서 효과적으로 처리할 수 있는 모델이 필요하다. 예를 들어, 음성 인식에서 길고 복잡한 문장을 처리할 때, 단어와 단어 사이의 시간적 관계를 잘 반영해야만 정확한 인식이 가능하다. 둘째, 학습 과정에서 발생하는 Vanishing Gradient 문제를 해결해야 합니다. 이는 RNN과 같은 순차 모델들이 긴 시퀀스를 처리할 때, 시간이 지남에 따라 기울기가 점점 작아져 학습이 어려워지는 현상이다. 예를 들어 긴 문장을 처리하는 도중 앞부분의 정보가 뒤로 전달되면서 점점 약해져 모델이 초반의 중요한 정보를 잃어버리는 문제가 발생할 수 있다. 이를 해결하려면, LSTM이나 GRU와 같은 고급 모델들이 필요하며 이들은 기울기 소실 문제를 완화시키는 구조를 가지고 있다.
3. State Space Model(SSM) 소개

State Space Model(SSM)은 제어 이론에서 유래한 모델로 시스템의 상태(state)와 출력을 수학적으로 표현하는 방법이다. 이 모델은 주로 두 가지 방정식으로 구성된다. 첫 번째는 시스템의 상태를 결정하는 상태 방정식으로, 입력 데이터(x)와 이전 상태를 바탕으로 현재 상태(h)를 계산한다. 두 번째는 출력 방정식으로, 계산된 상태(h)를 이용해 시스템의 출력을 y로 변환한다. 이 방식은 시간에 따른 시스템의 동작을 추적하고 예측하는 데 유용하며, 다양한 분야에서 시스템 분석과 제어에 널리 사용된다.

State Space Model(SSM)은 세 가지 방식으로 표현될 수 있다. 첫째, 연속 표현(Continuous Representation)은 시간에 따라 연속적으로 변하는 상태를 미분 방정식으로 모델링하여 시스템의 동적 변화를 수학적으로 설명한다. 둘째, 순차적 표현(Recurrent Representation)은 RNN처럼 시간 순서에 따라 상태를 갱신하며 이전 상태와 입력 데이터를 순차적으로 처리해 시계열 데이터를 효과적으로 다룬다. 셋째, 합성곱 표현(Convolution Representation)은 시계열이나 공간적 정보를 필터링해 주변 상태 정보를 고려하여 상태를 갱신하는 방식으로, 긴 시퀀스 처리에 효율적이다. 각 표현 방식은 모델링 대상의 특성과 목적에 맞게 선택되어 다양한 시스템 분석에 활용된다.

1. 연속 표현 (Continuous Representation)
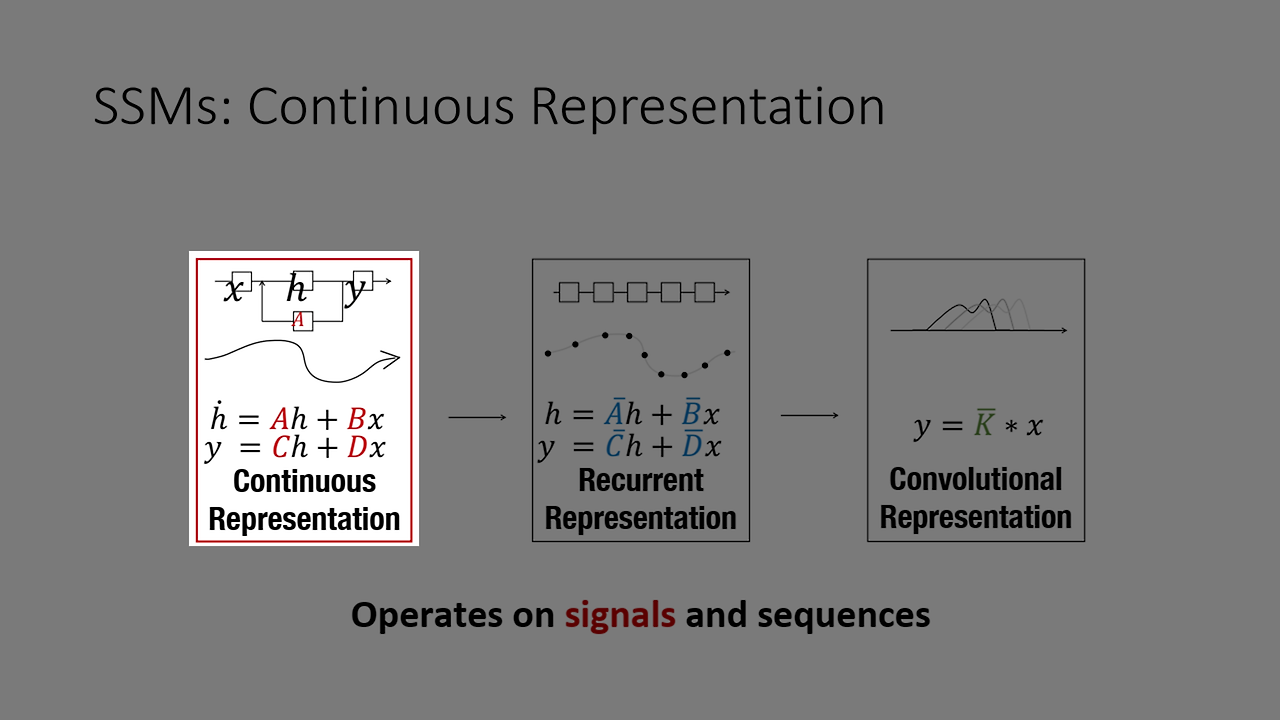
State Space Model(SSM)은 연속 표현(continuous representation)을 통해 시퀀스 데이터의 연속성을 자연스럽게 모델링할 수 있다. 예를 들어, 날씨 변화 예측을 위한 시스템이 있다고 하자. 여기서 상태 방정식과 출력 방정식을 사용해 현재 날씨 상태를 추적하고 미래 날씨를 예측할 수 있다. 상태 방정식 h′(t)=Ah(t)+Bx(t)는 이전 상태 h(t)와 새로운 입력 데이터 x(t)를 통해 현재 상태 h′(t)를 계산한다.
예를 들어, x(t)가 온도, 습도 등 현재 기상 데이터를 나타내면 h(t)는 이전 상태에서 계산된 날씨 상태이고, A와 B는 시스템이 시간이 지나면서 상태가 어떻게 변화하는지 결정하는 계수들이다. 출력 방정식 y(t)=Ch(t)+Dx(t)은 계산된 상태 h(t)와 입력 x(t)를 결합해 예측값 y(t)을 생성한다. 이때, C와 D는 상태를 출력으로 변환하는 계수들로, 예측된 날씨 상태를 최종 출력으로 변환해 준다. 이를 통해 SSM은 연속적인 입력을 받아 시계열 데이터를 분석하고, 시간에 따라 연속적으로 변하는 출력을 생성해 주는 역할을 한다.

SSM에서 연속된 시계열 표현 y를 기계나 사람이 이해할 수 있는 형태로 변환하려면 이산화(discretization) 작업이 필요하다. 이산화는 연속적인 함수, 모델, 변수, 방정식을 이산적인 구성요소로 변환하는 과정으로 연속적인 시간 표현을 특정 간격의 이산 시간 단계로 나누어 디지털화하는 방식이다. 예를 들어, 온도를 연속적으로 측정하는 센서 데이터가 있다고 할 때, 이 데이터를 컴퓨터가 처리하기 위해서는 일정한 시간 간격으로 샘플링하여 이산 시간 데이터로 변환한다. 이러한 이산화 과정은 수치적 평가와 컴퓨터 구현에 필수적이며 연속적 시스템을 디지털 환경에서 분석하고 제어할 수 있게 된다.
2. Recurrent Representation
다음으로 Recurrent Representation은 상태 공간 모델에서 순차적으로 상태 를 업데이트하는 구조이다. 즉, -번째 시간 단계에서의 상태 는 이전 상태 에 의존한다.

위 그림에서 이전의 실선 그래프는 데이터가 연속적(continuous)으로 이어진 모습을 보여주지만, 현재의 그래프는 블록으로 나뉘어 있다. 이는 데이터가 연속된 값 대신 특정 간격으로 나뉜 이산적(discrete) 값으로 변환된 결과이다. 이렇게 데이터를 이산화(discretization)하면 시간 순서에 따라 나열된 블록 형태가 나타나며, 이는 마치 Recurrent Neural Network(RNN) 구조와 유사한 모습을 띤다. RNN 역시 시간 단계마다 이전 출력이 다음 입력에 반영되는 형태로 데이터를 처리하기 때문에, 이산화된 시계열 데이터의 블록 형태와 시각적으로 비슷한 구조를 가지게 된다.

Zero-Order Hold (ZOH)는 연속 신호를 이산화하는 데 사용되는 방법으로 각 샘플링 구간 동안 신호 값을 일정하게 유지한다. 예를 들어 온도 센서가 주기적으로 온도를 측정한다고 하면 ZOH는 각 측정 값이 다음 측정까지 일정하게 유지되도록 처리하여 디지털 신호로 변환한다. 이를 통해 연속 시간 시스템을 이산 시간 시스템으로 변환할 수 있다.
SSM에서 연속 시간 상태 방정식이 h′(t)=Ah(t)+Bx(t)h'(t) = Ah(t) + Bx(t)와 y(t)=Ch(t)+Dx(t)y(t) = Ch(t) + Dx(t)로 주어진다면, ZOH를 적용해 이산화된 상태 방정식을 도출한다. ZOH 가정에 따라 x(t)=x(kΔt)x(t) = x(k\Delta t)로 설정하면, 이 값이 t=kΔtt = k\Delta t부터 t=(k+1)Δtt = (k+1)\Delta t 구간 동안 일정하게 유지된다. 상태 h(t)h(t)를 구하기 위해 h(t)=eA(t−kΔt)h(kΔt)+∫kΔtteA(t−τ)Bx(kΔt)dτh(t) = e^{A(t-k\Delta t)} h(k\Delta t) + \int_{k\Delta t}^{t} e^{A(t - \tau)} B x(k\Delta t) d\tau를 계산해 현재 상태 h(t)h(t)를 얻는다.
이를 통해 이산 시간 모델을 정의하면 hk+1=Aˉhk+Bˉxkh_{k+1} = \bar{A} h_k + \bar{B} x_k와 yk=Chk+Dxky_k = Ch_k + Dx_k가 된다. 여기서, Aˉ=eAΔt\bar{A} = e^{A \Delta t}와 Bˉ=A−1(eAΔt−I)B\bar{B} = A^{-1}(e^{A \Delta t} - I) B는 이산 시간 상태 행렬이다. 이 과정은 ZOH를 통해 시스템이 각 샘플링 구간에서 값을 일정하게 유지하여 시간에 따른 변화를 이산적으로 모델링하게 만든다.

이제 이산화한 결과를 살펴보면 다음과 같이 각각의 T=0, T=1, T=2에 대해서 이전 time k-1의 의 input과 현시점 의 input을 받아서 를 도출하고 이를 통해 를 재귀적으로 호출하는 것을 볼 수 있습니다.
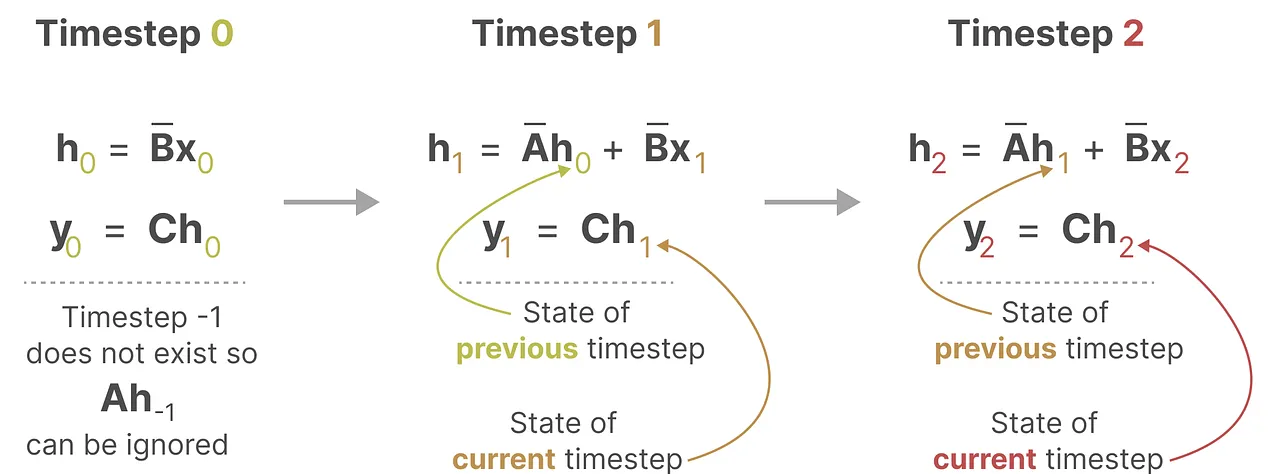
바로 RNN과 유사한 형태로 말이죠!!

3. Convolution Representation
Recurrent Representation의 순차적인 상태 업데이트를 Convolution Representation으로 바꾸기 전에 먼저 시간 순으로 를 살펴보겠습니다.
예를 들어,
- 첫 번째 상태(k=1)는 다음과 같습니다:
- 상태 :
- 출력 :
- 상태 :
- 두 번째 상태(k=2)는 다음과 같습니다:
- 상태 :
- 출력 :
- 상태 :
- 세 번째 상태(k=3)는 다음과 같습니다:
- 상태 :
- 출력 :
- 상태 :
- 네 번째 상태(k=4)는 다음과 같습니다:
- 상태 :
- 출력 :
- 상태 :
- 다섯 번째 상태(k=5)는 다음과 같습니다:
- 상태 :
- 출력 :
- 상태 :
규칙이 좀 보이시나요?! 좀 더 이쁘게 제가 만든 그림을 밑에 보여드리겠습니다. (*D term은 생략함)

1. (첫 번째 출력)
- 상태:
- 여기서 커널의 마지막 항목 가 입력 와 곱해져 첫 번째 출력 가 계산됩니다.
- 패딩이 있기 때문에 커널의 앞 두 항목은 입력과 상호작용하지 않고 패딩(0)에 해당합니다.
- 출력:
- 첫 번째 출력은 로 표현됩니다.
2. (두 번째 출력)
- 상태:
- 이제 커널의 두 번째 항목이 , 마지막 항목이 과 곱해지면서 두 번째 상태가 계산됩니다.
- 패딩 값이 하나 남아있고, 커널의 첫 번째 항목은 여전히 패딩(0)과 상호작용합니다.
- 출력:
- 두 번째 출력은 이전 입력과 현재 입력의 합으로 계산됩니다.
3. (세 번째 출력)
- 상태:
- 세 번째 상태에서는 커널의 모든 항목이 실제 입력과 상호작용하기 시작합니다.
- 커널의 첫 번째 항목은 , 두 번째 항목은 , 세 번째 항목은 와 곱해집니다.
- 출력:
- 세 번째 출력은 , , 에 대한 커널 가중합으로 계산됩니다.
4. (네 번째 출력)
- 상태:
- 네 번째 상태에서는 커널이 , , 과 상호작용합니다.
- 더 이상 패딩이 적용되지 않으며, 입력 시퀀스와 커널 간의 완전한 상호작용이 이루어집니다.
- 출력:
- 네 번째 출력은 , , 에 대한 커널 가중합입니다.
Convolution Representation 방식의 장점은 Recurrent Representation에서 각 시간 단계별로 순차적으로 상태를 업데이트하는 대신, 모든 시간 단계의 출력을 한 번에 계산할 수 있다는 점입니다.
- 병렬 처리 가능: Recurrent Representation에서는 각 시간 단계별로 순차적으로 상태를 업데이트해야 하므로 계산이 직렬화되어 있습니다. 그러나 Convolution Representation에서는 커널을 이용하여 입력 시퀀스 전체에 걸쳐 동시에 출력을 계산할 수 있어, 병렬화가 가능해집니다. 이는 특히 긴 시퀀스를 처리할 때 효율적인 계산을 가능하게 합니다.
- 더 큰 커널 적용 가능: 예시에서는 커널 사이즈를 3으로 설정했지만, 이론적으로는 더 큰 커널도 사용할 수 있습니다. 더 큰 커널은 더 긴 범위의 과거 입력을 한 번에 처리할 수 있어, 더 넓은 문맥 정보를 활용할 수 있게 합니다. 이는 시퀀스 데이터에서 장기적인 종속성을 더 잘 반영하는 데 도움이 됩니다.
- 효율성: 합성곱 연산은 일반적으로 GPU와 같은 병렬화가 가능한 하드웨어에서 매우 빠르게 처리될 수 있습니다. 이는 Recurrent Representation에 비해 계산 속도에서 큰 이점을 제공합니다.
그러나, 이상적으로 이러한 deepSSM을 바로 적용하기에는 많은 문제점들이 있었는데요.

아래 연구들은 이런 Convolution Representation을 어떻게 효율적으로 계산하고 처리할 수 있는가에 대한 연구들입니다.
- HiPPO : Recurrent Memory with Optimal Polynomial Projections (2020)
- LSSL : Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers (2021)
- S4 : Efficiently Modeling Long Sequences with Structured State Spaces (2022)
Research
이 논문들은 각각 시계열 데이터를 다루는 기존 모델의 한계를 극복하는 중요한 기술적 발전을 담고 있습니다.
- HiPPO: Recurrent Memory with Optimal Polynomial Projections (NeurIPS, 2020)
- 목적: 긴 시퀀스에 대한 메모리 문제를 해결하고, 메모리를 효율적으로 유지하면서 입력 정보를 계속 업데이트하는 방법을 제안합니다.
- 효과: 이 연구는 메모리 효율성과 정보 유지 간의 균형을 찾는 데 초점을 맞춥니다. 이를 통해 긴 시퀀스에서도 정보를 효과적으로 처리할 수 있게 됩니다.
- LSSL: Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers (NeurIPS, 2021)
- 목적: 이 연구는 연속 시간 모델과 선형 상태 공간 레이어(LSSL)를 결합하여, 시간에 따른 연속적인 변화와 비연속적인 변화를 동시에 처리할 수 있게 만듭니다.
- 효과: LSSL은 모델의 유연성을 높여서, 시계열 데이터뿐 아니라 다양한 종류의 연속적 데이터를 처리할 수 있도록 돕습니다.
- S4: Efficiently Modeling Long Sequences with Structured State Spaces (ICLR, 2022)
- 목적: S4는 Convolution Representation의 효율성을 극대화하면서도, 장기적인 종속성을 더 잘 처리할 수 있게 최적화되었습니다.
- 효과: S4는 특히 장기적인 패턴 학습에 강점이 있어, 기존의 모델보다 훨씬 긴 시퀀스에서도 우수한 성능을 보입니다.
1. HiPPO: Recurrent Memory with Optimal Polynomial Projections (Neurips 2020)

Preliminary
본격적으로 HiPPO를 살펴보기에 앞서, 다음 수학 개념들을 어느 정도 이해하고 있어야 관련 내용을 더 잘 이해할 수 있습니다: 라게르(Laguerre) 다항식, 르장드르(Legendre) 다항식, 그리고 다항식 투영 연산자입니다. 이 개념들은 시계열 데이터를 분석하고 근사하는 데 중요한 역할을 하며, 복잡한 데이터를 수학적으로 다루는 강력한 도구입니다. 각 개념을 차례로 설명하겠습니다.
1. 다항식 투영 연산자(Polynomial Projection Operator)
- 다항식 투영 연산자는 복잡한 데이터를 특정 직교 다항식 기저를 사용하여 더 간단한 다항식으로 표현하는 과정입니다. 시계열 데이터나 함수가 주어졌을 때, 이를 직교하는 다항식들의 선형 결합으로 근사합니다.
💡 직교 다항식 기저(Orthogonal Polynomial Basis)는 여러 다항식 중에서도 서로 직교(orthogonal)하는 성질을 가진 다항식들의 집합을 의미합니다.
- 직교성은 두 함수(또는 두 다항식) 사이의 내적(inner product)이 0이라는 의미입니다. 직교성은 데이터나 함수의 서로 다른 성분이 서로 영향을 미치지 않는 독립적인 관계를 나타냅니다.
- 기저란 주어진 공간을 구성하는 "기본" 요소들의 집합을 의미합니다. 기저 벡터의 선형 결합을 통해 공간 내의 모든 벡터(또는 함수)를 표현할 수 있는 것처럼, 기저 다항식을 사용하면 주어진 함수나 데이터를 그 기저 다항식들의 선형 결합으로 표현할 수 있습니다.
- 3차 다항식 공간에서는 다음과 같은 기저를 생각할 수 있습니다:
- 3차 이하의 모든 다항식은 이들의 선형 결합으로 표현될 수 있습니다:
- 3차 다항식 공간에서는 다음과 같은 기저를 생각할 수 있습니다:
- 다항식 투영의 핵심 : 주어진 함수나 데이터를 직교 다항식 기저 위에 "투영"하여 가장 적합한 근사값을 찾는 것입니다. 직교 다항식은 서로 독립이기 때문에, 데이터를 여러 개의 독립적인 성분으로 분해하여 분석하는 것이 가능합니다.
- 오차 최소화 : 투영 연산자는 보통 최소 제곱법(least squares method)을 사용하여 주어진 데이터를 다항식 기저로 표현하는 과정에서 오차를 최소화합니다.
일반적으로 "내적!" 하면 고등학교에서 배운 가 생각나실겁니다. 하지만, 함수 간의 내적은 이를 확장한 개념으로 단순히 각도나 크기와 같은 직관적인 개념으로 설명되지 않습니다.
💬 (REVIEW) 벡터 내적 :
- 와 는 벡터입니다.
- 와 는 각 벡터의 길이(크기, magnitude)입니다.
- 는 두 벡터 사이의 각도입니다.
- 두 벡터의 내적은 두 벡터 사이의 유사도를 측정하는데, 벡터가 평행할수록 내적의 값은 크고, 직교(즉, 90도일 때)할수록 내적은 0이 됩니다.
✨ (NEW) 함수 내적 :
- 와 는 함수입니다.
- 는 함수가 정의된 구간입니다.
- 는 가중 함수로, 내적 계산에서 특정 구간에 가중치를 부여하는 역할을 합니다.
- 함수의 내적은 벡터 내적처럼 함수 사이의 유사도를 측정하는 역할을 합니다.
- 투영 연산자의 작동 방식:
- 기저 다항식 선택: 특정 구간에서 직교하는 다항식을 선택합니다.
↳ 예를 들어, 구간 [-1, 1]에서 르장드르 다항식, 구간 [0, ∞)에서 라게르 다항식을 사용할 수 있습니다. (아래 참고) - 계수 결정: 다항식 투영 연산자는 주어진 데이터에 가장 적합한 다항식 기저의 계수를 찾아냅니다.
↳ 이를 통해 데이터를 표현하는 함수가 각 다항식의 선형 결합으로 나타납니다. - 함수 근사: 투영된 결과는 원래 데이터에 대한 "최적의 근사"를 제공합니다.
↳ 이를 통해 데이터를 단순화하거나 분석할 수 있습니다.
- 기저 다항식 선택: 특정 구간에서 직교하는 다항식을 선택합니다.
2. 르장드르 다항식(Legendre Polynomials)
- 르장드르 다항식은 구간 [-1, 1]에서 가중 함수 에 대해 직교성을 갖는 다항식입니다.
- 르장드르 다항식의 직교성은 다음 수식으로 표현됩니다:
- 이 수식은 서로 다른 차수의 르장드르 다항식들이 구간 [-1, 1]에서 직교함을 나타냅니다. 여기서:
- 와 는 각각 차수가 다른 르장드르 다항식입니다.
- 는 크로네커 델타로, 일 때는 1, 그렇지 않으면 0을 의미합니다. 즉, 같은 차수일 경우 내적이 1이 되고, 다른 차수일 경우 내적이 0이 됩니다.
- 또한, 르장드르 다항식은 다음과 같은 경계 조건을 만족합니다:이는 르장드르 다항식의 값이 구간 끝점에서 어떻게 동작하는지를 보여줍니다.

- (참고) HiPPO에서는 Legendre 다항식이 시간 축에 따른 데이터를 압축하는 데 사용됩니다. 이를 통해 이전 시점에서의 데이터를 효과적으로 메모리에 저장하고 기억할 수 있습니다.
3. 라게르 다항식(Laguerre Polynomials)
- 라게르 다항식은 [0, ∞) 구간에서 가중 함수 에 대해 직교성을 갖는 다항식입니다.
- 라게르 다항식의 직교성은 다음 수식으로 표현됩니다:
- 이 수식은 서로 다른 차수의 라게르 다항식들이 가중 함수 에 대해 직교함을 나타냅니다. 여기서:
- 와 는 각각 일반화된 라게르 다항식으로, 매개변수 에 따라 달라집니다.
- 는 크로네커 델타로, 일 때는 1, 그렇지 않으면 0입니다.
- 표준 라게르 다항식은 매개변수 일 때의 특수한 경우로, 다음과 같은 직교성을 가집니다:

- (참고) HiPPO에서는 Laguerre 다항식을 사용하여 과거 데이터를 표현하고 기억하는 방식으로, 특히 메모리 관리에 사용됩니다. 이 다항식은 시간이 지남에 따라 데이터가 어떻게 변하는지 모델링하는 데 적합합니다.
HiPPO Preliminary
HiPPO에서는 다항식 투영 연산자(Legendre 다항식과 Laguerre 다항식)을 통해 시간 축에 따른 데이터를 압축하고, 메모리 사용량을 줄이며, 중요한 정보를 요약하여 저장하는 방식으로 사용됩니다.
- 이 다항식들은 입력 데이터를 다항식 공간에 투영하여, 이전 시점의 데이터를 효율적으로 기억하고 업데이트하는 데 도움을 줍니다.
- Legendre 다항식은 구간 [-1, 1] 내에서 시계열 데이터를 모델링하고, 직교성을 통해 메모리의 효율적인 관리가 가능합니다.
- Laguerre 다항식은 주로 신호 처리에서 긴 시간에 걸쳐 데이터를 처리할 때 사용되며, HiPPO에서는 데이터를 요약하고 저장하는 데 사용합니다.
Introduction (서론)
- Introductin에서는 먼저 Sequential 데이터의 처리를 위한 현존하는 RNN 모델의 제약 사항들을 아래와 같이 서술합니다:
- Limited Memory Horizon: RNN은 긴 시퀀스를 처리할 때 이전 정보의 기억이 약해지는 경향이 있습니다. 즉, 모델이 이전 데이터에서 중요한 정보를 잊어버리는 문제에 직면하게 됩니다.
- Vanishing Gradients: RNN은 역전파 과정에서 기울기가 매우 작아져서 가중치 업데이트가 거의 이루어지지 않는 문제에 직면합니다. 이로 인해 모델이 장기 의존성을 학습하기가 매우 어려워집니다.
- 시퀀스 길이 및 시간 척도에 대한 선행 정보 요구: 기존 RNN 및 그 변형들은 특정한 시퀀스 길이나 시간 척도에 대한 선행 정보(prior)를 필요로 합니다. 그러나 이러한 선행 정보는 불확실한 환경이나 데이터 분포 변화에 대해 일반화하기 어렵습니다.
- 이론적 보장 결여(Theoretical Guarantees):
- 기존 방법들은 장기 의존성을 얼마나 잘 캡처할 수 있는지에 대한 이론적 보장이 부족합니다. 특히, 기울기 경계 등과 같은 성능에 대한 이론적 근거가 결여되어 있어, 효과적인 성능을 기대하기 어렵습니다.
- 장기 및 복잡한 시간 의존성 모델링의 어려움: RNN은 복잡한 시간 의존성을 모델링하는 데 한계가 있으며, 이로 인해 의료 데이터와 같은 다양한 샘플링 주기를 가진 데이터에서 효과적으로 작동하지 못할 수 있습니다.
- 논문에서는 이러한 한계점을 해결하기 위해 HiPPO(High-order Polynomial Projection Operators)라는 새로운 프레임워크를 제안합니다.
- HiPPO는 연속 신호 및 이산 시계열 데이터를 최적의 방법으로 압축하고 과거 데이터를 모델링하여 장기 의존성을 잘 처리할 수 있도록 도와줍니다.

The HiPPO Framework: High-order Polynomial Projection Operators (HiPPO 프레임워크: 고차 다항식 투영 연산자)
HiPPO 프레임워크의 목표는 시간에 따라 변화하는 데이터를 압축된 형태로 유지하며, 각 시간 t에서 과거 데이터를 효율적으로 표현하는 것입니다.
- 이 프레임워크는 온라인 함수 근사를 통해 메모리 메커니즘을 고안하고, 고차 다항식 투영 연산자를 사용하는 방식으로 순차 데이터를 처리합니다
문제 정의

- 입력 함수 의 누적 이력을 온라인으로 압축하여 표현하는 방법을 논의합니다.
- Online Approximation (온라인 근사):
- 각 시간 마다 를 근사하기 위해 측도 가 변화합니다.
- 이 측도는 다양한 과거 입력의 중요도를 조절하며, 최적의 다항식 근사를 찾아내는 과정에서 활용됩니다.
- Online Approximation (온라인 근사):
- 함수의 역사 를 유지하기 위해서는 두 가지 필수 요소가 도출됩니다: 근사 방법과 서브스페이스.
- Function Approximation with respect to a Measure (측도에 대한 함수 근사):
- 근사 품질을 정량화하는 방법은 확률 측도 를 통해 내적을 정의하는 방식입니다.
- 내적은 로 표현되며, 함수 와 사이의 거리 또는 오차를 측정할 수 있는 기준을 제공합니다.
- Polynomial Basis Expansion (다항식 기초 확장):
- 다항식을 기반으로 한 부분 공간 를 사용하여 함수를 근사합니다.
- 이 부분 공간은 차수 미만의 다항식으로 구성되며, 이는 입력 함수의 근사를 위해 사용할 수 있는 기준을 제공합니다.
- 이러한 기초 확장은 다양한 함수들을 효과적으로 표현할 수 있는 기반을 제공합니다.
- Function Approximation with respect to a Measure (측도에 대한 함수 근사):

HiPPO 핵심 아이디어
1. Choose suitable basis (적절한 기저 선택)
- 의미:
- 특정 함수 를 근사하기 위해, 그 함수의 공간에서 적절한 다항식 기저를 선택하는 단계입니다.
- 이 기저는 함수의 성질과 시간 가변 측정 에 따라 달라지며, 일반적으로는 orthogonal 다항식이 사용됩니다.
- 세부 사항:
- 선택된 기저 는 차원의 다항식 공간을 구성하며, 이 기저에 대해 함수 를 projection 합니다.
- 이는 주어진 함수와 기저의 관계를 정의하기 위한 것입니다. 최적의 계수 는 다음과 같은 내적을 통해 계산됩니다:
- 이 단계의 목적은 입력 신호의 중요한 특성들을 보존하면서 복잡한 함수를 그 기저에 맞춰 간단한 다항식으로 표현하는 것입니다.
2. Differentiate the projection (프로젝션 미분)
- 의미:
- 선택한 기저에 대해 시간 에 따라 projection을 미분하는 단계입니다.
- 이는 주어진 함수의 시간적 변화를 포착하고, projection 계수의 동역학을 이해하는 데 필요합니다.
- 세부 사항:
- 미분을 통해 얻은 관계는 projection의 변화량을 설명하며, 일반적으로 이러한 미분은 자기 유사성을 가지는 방정식 형태로 표현됩니다.
- 이 단계는 프로젝션 계수가 시간에 따라 어떻게 변화하는지를 설명하는 ODE(상미분방정식)를 수립하는 데 필수적입니다. 이를 통해, 의 동역학이 정량적으로 분석 가능하게 됩니다.
HiPPO 프레임워크
HiPPO는 함수 근사를 위한 일종의 동적 시스템 방법론으로, 주어진 함수 를 시간에 따라 압축하고 저장하는 과정을 다룹니다. 이 과정은 측도에 기반한 직교 기저를 사용하여 함수를 다항식 공간으로 투영(projection)하고, 시간에 따라 변화하는 함수의 정보를 효율적으로 표현할 수 있도록 설계되었습니다.
아래와 그림으로 정리를 하니까 이해가 되는군요! 🔥 (오랜만에 수식보니까 머리가😱)

글로 다시 한번 좀 정리해볼까요?
① Projection 연산 : 함수 를 다항식 공간으로 투영
- 투영 연산자 는 함수 를 일정 시간 까지의 정보로 제한하여 다항식 공간 에 투영합니다. 즉, 주어진 의 정보를 다항식 로 근사하여 나타냅니다.
- 이 과정에서 중요한 것은, 투영을 통해 얻은 다항식이 시간 이전의 함수 정보 를 최대한 정확하게 표현하는 것입니다. 투영 연산의 목표는, 주어진 측도 하에서 오차가 최소화되도록 다항식 로 함수를 근사하는 것입니다.
② Coefficients 계산: 계수 구하기
- 투영된 다항식 는 다항식 기저 함수들의 선형 결합으로 표현되며, 각 기저 함수에 곱해지는 계수 는 시간에 따라 변화합니다.
- HiPPO는 이 계수 를 효율적으로 계산하여, 함수 의 과거 기록을 압축하는 방식으로 표현합니다. 는 의 벡터로, 이는 선택된 개의 기저 함수에 대한 계수를 의미합니다.
③ 미분 방정식 (ODE)으로 계수의 진화 모델링
- 투영된 함수의 계수 는 시간에 따라 진화하며, 이 변화는 상미분 방정식(ODE)으로 표현됩니다:
- 이 방정식은 계수 가 시간 에 따라 어떻게 변화하는지를 설명합니다. 와 는 각각 계수와 함수의 변화율을 나타내는 행렬입니다.
- 중요한 점은, HiPPO가 이 ODE를 통해 함수를 시간에 따라 온라인 방식으로 압축한다는 것입니다. 즉, 실시간으로 함수의 정보를 저장하고 진화시킵니다.
💡 High Order Projection: Measure Families and HiPPO ODEs
- HiPPO 프레임워크에서 고차 다항식 투영(High Order Projection)을 통해 과거 데이터를 다항식 형태로 효율적으로 압축하고 이를 실시간으로 업데이트하는 것입니다.
- 특히, HiPPO에서는 LagT(Translated Laguerre Measure)와 LegT(Translated Legendre Measure) 두 가지 측정(Measure) 방법을 제시하고, 이를 바탕으로 미분 방정식(ODE)을 사용하여 메모리를 업데이트하는 방식을 제안합니다.
💬 Translated Laguerre Measure (LagT)
- LagT는 최근의 데이터가 더 중요하다는 가정을 반영합니다.
- 과거로 갈수록 데이터의 중요도가 지수적으로 감소합니다.
- Measure 정의:
- 이 수식은 일 때만 정의되며, 과거로 갈수록 라는 함수가 지수적으로 감소함을 나타냅니다.
- 이는 최근의 데이터가 과거의 데이터보다 중요하다는 의미입니다.
- ODE 형태:
- 여기서 는 투영된 다항식의 계수 벡터를 의미합니다.
- 이 식에서 주어진 데이터 는 LagT가 최근 데이터를 중요하게 반영하도록 설계된 방식으로 다항식 기저에 투영됩니다.
- 행렬 A와 B 정의:
- 이는 지수적 감소를 반영한 메커니즘으로, 최근의 데이터가 더 중요한 방식으로 다항식의 계수들을 업데이트합니다.
💬 Translated Legendre Measure (LegT)
- LegT는 고정된 시간 범위 내의 데이터만 중요하다고 가정합니다.
- 즉, 일정 길이의 슬라이딩 윈도우(Sliding Window) 방식으로 데이터를 처리합니다.
- Measure 정의:
- 여기서 는 슬라이딩 윈도우를 나타내며, 길이 만큼의 시간 창에서 데이터에 균등한 가중치를 부여합니다.
- 즉, 시간 창 사이의 데이터를 중요하게 다룹니다.
- ODE 형태:
- 여기서도 역시 는 다항식의 계수 벡터를 나타냅니다.
- 행렬 A와 B 정의:
- 이는 일정한 시간 창 내에서 데이터를 투영하여 유지하며, 일정 시간 범위 내의 데이터에만 중요성을 부여합니다.
④ Discrete-time HiPPO Recurrence (이산 시간 재귀 관계)
- HiPPO 프레임워크를 연속 시간(Continuous Time)에서 이산 시간(Discrete Time)으로 변환하는 방법에 대해 설명합니다.
- 이는 실질적인 시계열 데이터나 이산적인 시퀀스 데이터에 적용하기 위해 ODE를 이산화하는 과정입니다.
- ODE를 이산화하여 실질적으로 계산 가능한 형태로 만들면, 아래와 같은 재귀 관계를 얻게 됩니다:
- 이 식은 이전 시간의 계수 와 새로운 함수 값 을 사용하여 다음 시간 에서의 계수 를 계산합니다. 즉, 이 식은 함수의 정보를 이산적인 시간 단계에서 재귀적으로 업데이트하는 방식으로 구현됩니다.
- 이 과정을 통해, HiPPO는 함수의 과거 기록을 선형 결합의 형태로 압축하여 저장하고, 실시간으로 업데이트하는 효과적인 방법을 제공합니다.
- ODE를 이산화하여 실질적으로 계산 가능한 형태로 만들면, 아래와 같은 재귀 관계를 얻게 됩니다:
🕐 HiPPO-LegS: Scaled Measures for Timescale Robustness (HiPPO-LegS: 시계열 견고성을 위한 확장된 측정 방법)
- HiPPO-LegS는 시간 척도에 강건한 메모리 메커니즘을 제공하는 새로운 접근 방식입니다. 이 메커니즘은 과거 모든 시간에 대해 균등한 가중치를 부여하여 메모리를 구성합니다.

- 전체 이력 고려: LegS는 완전한 과거 이력을 고려하여 메모리를 구성하며, 이는 특정 슬라이딩 윈도우를 사용하는 기법과 달리 모든 과거 데이터를 균등하게 평가합니다.
- 반면, LagT와 LegT는 특정 시간 범위 내에서 데이터를 처리하므로 장기적 의존성을 포착하는 데 한계가 있을 수 있습니다.
- 하이퍼파라미터 필요 없음: LegS는 메모리 구성에 필요한 하이퍼파라미터 없이 동작합니다.
- 반면, LagT와 LegT는 하이퍼파라미터를 조정해야 할 수 있습니다.
- 시간 스케일에 대한 강건성: LegS는 입력 신호의 시간 척도가 바뀌어도 안정적으로 동작할 수 있습니다.
- 반면 LagT나 LegT는 특정 시간 척도에 대해 최적화된 결과를 나타낼 수 있지만, 다른 시간 척도에서는 성능이 저하될 수 있습니다.
- 시간에 따른 계산 효율성: LegS는 메모리 업데이트 과정을 간소화하여 각 시간 단계에서 더 빠르게 처리할 수 있습니다.
- LagT나 LegT는 상대적으로 복잡한 업데이트 규칙을 사용해야 할 수 있습니다.
- Gradient 및 역전파 문제 해결: LegS는 기울기 크기가 보존될 수 있는 메커니즘을 제공하여, 긴 시퀀스에 걸쳐 학습 안정성을 높입니다.
- LagT와 LegT는 때때로 그래디언트가 소실되는 문제가 발생할 수 있습니다.
- 전체 이력 고려: LegS는 완전한 과거 이력을 고려하여 메모리를 구성하며, 이는 특정 슬라이딩 윈도우를 사용하는 기법과 달리 모든 과거 데이터를 균등하게 평가합니다.
Empirical Validation (실증적 검증)

- 4.1 Long-range Memory Benchmark Tasks (장기 메모리 벤치마크 과제): 장기 메모리 의존성을 평가하는 다양한 벤치마크 과제에서 HiPPO-LegS의 성능을 검증합니다.
- 4.2 Timescale Robustness of HiPPO-LegS (HiPPO-LegS의 시계열 견고성): HiPPO-LegS가 다양한 시간 척도에서 얼마나 견고하게 성능을 발휘하는지 검증합니다.
- 4.3 Theoretical Validation and Scalability (이론적 검증 및 확장성): HiPPO 프레임워크가 이론적으로 어떻게 성능이 보장되는지와 그 확장성을 설명합니다.
- 4.4 Additional Experiments (추가 실험): 추가 실험을 통해 HiPPO 메모리 메커니즘의 유용성을 검증합니다.
Conclusion (결론)
- HiPPO 프레임워크가 메모리 문제에 대한 근본적인 해결책을 제시하며, 기존의 메모리 메커니즘을 통합하고 확장하여 더 나은 성능을 발휘할 수 있음을 결론으로 제시합니다
2. LSSL: Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers (NeurIPS, 2021)

이 논문의 목차에 따른 개념들을 다음과 같이 설명하겠습니다:
Introduction
- LSSL(Linear State-Space Layer)는 순환(Recurrent), 합성곱(Convolutional), 연속 시간 모델(Continuous-time)의 장점을 결합한 새로운 모델 패러다임으로, 시간에 따른 순차 데이터 처리를 더욱 효율적으로 할 수 있도록 설계된 구조입니다.
- 배경 및 문제 정의:
- 머신러닝에서 시퀀스 데이터(Sequential Data)를 처리하는 일반적인 방식은 RNN(Recurrent Neural Network), CNN(Convolutional Neural Network), NeuralODE(Neural Differential Equation) 등의 구조를 사용하는 것입니다. 이들은 각각 장단점이 있습니다.
- RNN은 시퀀스 데이터에 대한 상태 저장(Stateful) 성질을 갖고 있으나, 매 스텝마다 저장과 계산이 필요하므로 매우 비효율적입니다. 대표적인 문제로는 Vanishing Gradient Problem이 있습니다.
- CNN은 병렬 처리와 빠른 훈련이 가능하나, 긴 시퀀스를 처리하는 데 한계가 있습니다. 즉, 로컬 정보에 국한되어 있으며 긴 문맥(long-term dependency)을 기억하는 능력이 부족합니다.
- NeuralODE는 연속적 시간 모델을 사용하여 수학적으로 시퀀스를 처리하지만 계산 비용이 많이 들고, 특히 긴 시퀀스를 처리할 때 매우 비효율적입니다.
- 머신러닝에서 시퀀스 데이터(Sequential Data)를 처리하는 일반적인 방식은 RNN(Recurrent Neural Network), CNN(Convolutional Neural Network), NeuralODE(Neural Differential Equation) 등의 구조를 사용하는 것입니다. 이들은 각각 장단점이 있습니다.

- LSSL의 제안 및 목적:
- 본 연구에서는 이러한 RNN, CNN, NeuralODE 각각의 장점을 살리면서도 각 모델의 단점을 극복하는 새로운 구조인 Linear State-Space Layer(LSSL)를 제안합니다.
- 주요 목표는 CNN의 병렬 처리 장점, RNN의 상태 추론 능력, NeuralODE의 시간 척도(Time-scale) 적응력을 동시에 제공하는 모델을 개발하는 것입니다.
- 재귀성(Recurrent): 특정 시간 간격 를 사용하여 상태 공간 모델을 불연속화(Discretization)하면, 재귀적인 방식으로 시퀀스를 처리할 수 있습니다. 이를 통해 RNN처럼 상태를 추적할 수 있습니다.
- 합성곱성(Convolutional): 선형 시간 불변 시스템(Linear Time-Invariant System, LTI)으로서, 연속적인 합성곱으로 표현이 가능합니다. 이를 통해 CNN과 같이 병렬 처리 및 효율적인 훈련이 가능합니다.
- 연속 시간 모델(Continuous-time): LSSL은 미분 방정식으로 표현되므로 연속 시간 모델로서의 장점을 가지며, 다양한 시간 척도에 적응할 수 있는 유연성을 제공합니다.
아래 그림은 논문에서 나온 Figure1로 위에서 설명하는 LSSL의 3가지 View를 설명합니다.

- View 1. Continuous-time 관점:
- 이 모드에서는 상태 공간 모델이 연속적 시간 에 따라 변하며, 불규칙한 샘플링 데이터도 처리할 수 있습니다. (미분 방정식 형태)
- 식 는 상태가 시간에 따라 어떻게 변화하는지 나타내며, 출력은 로 정의됩니다.
- View 2. Recurrent 관점:
- 이산화(Discretization)를 통해 RNN과 같은 형태로 사용할 수 있으며 시간 간격 에 따라 상태가 변화하고, 이전 상태 정보 를 사용하여 현재 상태 와 출력을 계산합니다.
- 이를 통해 무한한 문맥(Unbounded Context)을 처리할 수 있으며, 효율적인 추론이 가능합니다.
- View 3. Convolutional 관점:
- 합성곱적 방식으로도 표현이 가능합니다. 합성곱 커널 는 선형 시스템을 기반으로 계산되며, 이를 통해 입력 시퀀스에 대해 병렬로 처리할 수 있습니다.
- CNN과 같이 로컬 정보(Local Information)를 사용하면서도, 병렬화된 훈련이 가능하다는 장점이 있습니다.
Linear State-Space Layers (LSSL)
- 3.1 LSSL의 다양한 뷰 (Different Views of the LSSL)
- LSSL의 기본 수식은 상태 공간 표현(state-space representation)인 A, B, C, D행렬을 사용하여 정의됩니다. 수식으로는 아래와 같이 표현됩니다.
- LSSL은 이 모델을 이산화(discretization)하여 라는 타임스텝을 기반으로 입력 시퀀스 를 출력 시퀀스 로 변환하는 시퀀스 투 시퀀스 맵핑을 제공합니다. 이때, 각 타임스텝의 H-dim feature 벡터를 포함한 시퀀스를 처리합니다.
- LSSL은 여러 가지 방식으로 계산될 수 있으며, 그 방식들은 크게 재귀적 모델(Recurrent Model), 합성곱 모델(Convolutional Model), 연속 시간 모델(Continuous-Time Model)로 나뉩니다. 논문은 해당 파트에서 이를 도식적으로 표현하면서 각 방식이 어떻게 다르게 작동하는지를 보여줍니다. (이는 앞에의 3. State Space Model(SSM) 소개에서도 다뤘으니 너무 깊게 가지는 않겠습니다)
① Recurrent View (재귀적 관점)
- 재귀적 관점에서는 상태 벡터 이 이전 입력 정보와 현재 입력 정보 간의 문맥을 유지합니다.

- 이를 통해 효율적인 상태 추론을 할 수 있으며, 순환 신경망(RNN)처럼 작동합니다.
② Convolutional View (합성곱 관점)
- 합성곱 관점에서, LSSL은 state 벡터를 통해 필터링된 출력을 제공합니다.
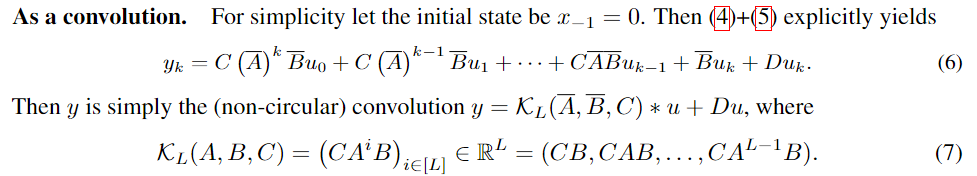
- 합성곱 관점에서 계산 효율성을 높이기 위해 FFT(빠른 푸리에 변환)를 사용할 수 있습니다.
- 3.2 LSSL의 표현력 (Expressivity of LSSLs)
- 이 절에서는 LSSL이 실제로 어느 정도까지 다양한 재귀적 특성과 합성곱적 특성 표현을 얼마나 잘 할 수 있는지를 분석합니다.
- 상태 공간 시스템과 임펄스 응답(Impulse Response) : 상태 공간 시스템은 기본적으로 연속 시간 또는 불연속 시간 시스템의 입력과 출력을 상태 변수로 표현하는 방식입니다. LSSL도 이러한 상태 공간 시스템을 기반으로 하여 입력 를 시간에 따라 상태 와 출력 로 변환합니다. 수학적으로는 다음과 같은 형태입니다:
- 여기서 입력 가 주어졌을 때 시스템이 시간에 따라 어떻게 변하는지를 나타내는 함수가 임펄스 응답 함수입니다. 임펄스 응답 함수는 시스템이 특정 입력(즉, 임펄스)에 대해 어떻게 반응하는지를 보여줍니다.
- 임펄스 응답 함수(IRF)는 시스템이나 신호 처리에서 중요한 개념입니다. 이는 시스템이 단위 임펄스 입력에 대해 어떻게 반응하는지를 나타내는 함수입니다.
- 임펄스(impulse)는 물리학에서 물체에 작용하는 힘이 시간에 걸쳐 변화하는 과정을 설명하는 개념입니다. 일반적으로 임펄스는 힘과 시간의 곱으로 정의되며, 물체의 운동량 변화와 관련이 있습니다. 수식으로 표현하면 다음과 같습니다:
- 임펄스 응답과 합성곱 연산 : 임펄스 응답 함수 는 상태 공간 모델에서 출력을 계산하는데 매우 중요합니다. 임펄스 응답을 알면 입력 신호 가 주어졌을 때 시스템의 출력을 다음과 같은 합성곱 연산으로 표현할 수 있습니다:
- 즉, 시스템의 출력은 입력 신호 와 시스템의 임펄스 응답 의 합성곱으로 계산됩니다. 여기서 합성곱 연산이 중요한 이유는, 임펄스 응답 함수가 시스템의 시간적 특성을 결정하며, 이를 통해 과거의 입력들이 현재의 출력을 어떻게 결정하는지를 설명할 수 있기 때문입니다.
- LSSL에서 합성곱의 역할 : LSSL은 상태 공간 시스템을 기반으로 하지만, 이를 이산화(Discretization)하여 합성곱으로 처리할 수 있습니다.
- 이산화된 시스템은 실제로 시간에 따라 입력이 어떻게 변하는지를 계산할 때, 임펄스 응답 함수를 사용하여 합성곱 필터로 변환할 수 있습니다.
- 즉, 상태 공간 시스템을 통해 정의된 시스템의 응답을 합성곱 필터로 표현할 수 있다는 의미입니다.
② LSSL의 RNN과의 관계
- RNN은 입력 시퀀스를 처리할 때, 이전 시간의 상태 를 현재 상태 에 전달함으로써 시간적 종속성을 유지합니다.
- 즉, RNN은 이전 타임스텝의 정보를 다음 타임스텝으로 전달하면서 상태를 갱신하고, 이를 통해 긴 시퀀스의 정보를 추적할 수 있습니다. 수학적으로 RNN의 상태 갱신 방정식은 다음과 같이 표현됩니다:
- LSSL도 RNN처럼 시간에 따른 상태 갱신을 수행합니다. LSSL의 상태 갱신 방정식은 상태 공간 모델에 기반한 미분 방정식으로 정의되는데, 이를 이산화하면 RNN과 유사한 구조가 됩니다.
↓ 이산화 수행
- 또한, RNN은 위와 같은 상태 갱신 과정에서 게이팅 메커니즘(Gating Mechanism)을 통해 각 타임스텝에서 정보를 얼마나 전달할지 조절합니다. LSTM이나 GRU에서의 게이팅 메커니즘은 RNN이 각 타임스텝에서 정보의 흐름을 조절하는 중요한 요소입니다.
- 이 게이팅 메커니즘은 사실상 시간 척도(Time-scale)를 부드럽게 하여 각 스텝에서의 상태 변화가 너무 급격하지 않게 만드는 역할을 합니다. 예를 들어, LSTM의 Forget Gate는 이전 상태를 얼마나 기억할지 조절하는데, 이는 일정한 시간 척도에서의 변화를 부드럽게 하는 역할을 합니다.

- LSSL에서도 라는 시간 간격(Time-step)이 중요한 역할을 합니다. 이 시간 간격은 각 타임스텝 간의 상태 변화를 결정하며, 이는 RNN에서 게이팅 메커니즘과 매우 유사한 역할을 합니다.
- 즉, LSSL의 시간 척도는 RNN의 게이팅 메커니즘과 본질적으로 같은 개념으로, 입력 데이터를 처리할 때 시간에 따른 변화량을 부드럽게 조절하는 역할을 합니다.
- 즉, RNN은 이전 타임스텝의 정보를 다음 타임스텝으로 전달하면서 상태를 갱신하고, 이를 통해 긴 시퀀스의 정보를 추적할 수 있습니다. 수학적으로 RNN의 상태 갱신 방정식은 다음과 같이 표현됩니다:
③ Deep LSSL
- LSSL을 하나의 레이어로 사용하지 않고 여러 레이어로 쌓아서 보다 깊은 네트워크로 확장할 수 있습니다. 이 구조는 특히 비선형 시퀀스 데이터를 처리하는 데 적합합니다.
- 기본 LSSL 구조 : LSSL은 seq-to-seq 매핑을 수행하며, 각각의 LSSL 레이어는 파라미터 와 시간 간격 로 정의됩니다. 입력 시퀀스는 H 차원의 피처로 처리되며, 각 피처가 독립적으로 학습됩니다.
- Layer Stacking : Deep LSSL은 여러 LSSL 레이어를 쌓아서 더 복잡한 시퀀스 데이터를 처리할 수 있습니다. 각 레이어는 서로 다른 상태 공간 파라미터와 시간 간격을 학습하여, 다차원적인 시간 척도에서 데이터를 처리합니다.
- Residual Connections : ResNet과 같은 Residual Connections을 사용하여 딥러닝 네트워크에서 발생할 수 있는 기울기 소실 문제를 해결합니다. 각 레이어의 출력을 다음 레이어로 직접 전달함으로써 정보가 사라지지 않게 유지하는 방식입니다.
- Normalization : LSSL의 레이어가 깊어질수록 Layer Normalization이 필요합니다. 이는 레이어가 쌓일 때 발생하는 내부 공변량 변화(Internal Covariate Shift)를 줄여주어, 학습 속도를 높이고 성능을 개선합니다.
Appendix B.1 (M) LSSL Computation
- LSSL의 계산은 시간이 많이 걸릴 수 있지만, 일부 계산을 캐싱함으로써 효율성을 높일 수 있습니다. 특히, 훈련되지 않은 와 파라미터를 고정할 경우 캐싱을 통해 계산 효율을 극대화할 수 있습니다.
- 전이 행렬(Transition Matrix): 상태 전이 행렬 는 블랙박스 매트릭스-벡터 곱 알고리즘을 사용하여 계산되며, 이를 캐싱해 둠으로써 연산을 반복하지 않아도 됩니다.
- 크릴로프 행렬(Krylov Matrix): 크릴로프 행렬은 입력과 상태 전이 행렬 , 그리고 행렬을 통해 계산되며, 이 계산은 병렬화될 수 있습니다. 제곱 연산 및 지수화를 통해 효율적으로 계산할 수 있습니다. 최종적으로 이 크릴로프 행렬은 의 형태로 캐싱되어 합성곱 연산 전에 저장됩니다.
- 복잡도: 캐싱을 사용한 이 알고리즘은 계산 복잡도가 로 줄어들지만, 이를 캐싱하기 위한 추가적인 메모리 공간이 필요합니다. 이 부분은 훈련 시 모델의 효율성을 극대화할 수 있지만, inference 시에는 더 많은 계산이 요구될 수 있습니다.
Appendix B.2 Initialization of
- 파라미터 는 HiPPO-LegS 연산자를 사용하여 초기화됩니다. HiPPO-LegS는 연속 시간 메모리화 문제를 해결하기 위해 설계된 연산자로, 상태 공간 시스템에서 긴 시퀀스 데이터를 효율적으로 처리하는 데 도움을 줍니다.
- 는 특정 규칙에 따라 대각 행렬을 구성하는데, 의 초기값은 아래와 같이 주어집니다:
- 이 초기화 방식은 LSSL의 상태 전이가 HiPPO 연산에 맞추어 최적화되도록 하며, 긴 시퀀스 메모리화 문제를 해결하는 데 도움을 줍니다.
Appendix B.3 Initialization of
- LSSL에서 는 각 레이어에서 상태 공간 시스템의 시간 간격(Time-step)을 조절하는 중요한 파라미터입니다. 는 로그 균등 분포(log-uniform distribution)를 사용하여 초기화되며, 이는 시간 척도 를 다양하게 설정함으로써 여러 시간 척도를 학습할 수 있도록 합니다.
- 최소 시간 간격 와 최대 시간 간격 를 설정하여, 데이터의 시퀀스 길이에 맞게 시간 간격을 초기화합니다.
- 이 파라미터는 시퀀스 데이터의 길이와 데이터셋마다 다르게 설정될 수 있으며, 다양한 시간 척도에 대해 모델이 적응할 수 있게 합니다.
Combining LSSLs with Continuous-time Memorization
기본 LSSL은 긴 시퀀스를 처리하는 데 있어 두 가지 문제가 있었습니다: (1) 기울기 소실 문제와 (2) 연산 복잡도 문제
- 4.1 Incorporating Long Dependencies into LSSLs (기울기 소실 문제):
- 문제: 상태 전이 행렬 를 무작위로 설정하거나 적절하게 설계하지 않으면, 긴 시퀀스를 처리할 때 기울기 소실 문제가 발생합니다. 이는 네트워크가 긴 시간 동안 중요한 정보를 유지하지 못하는 문제로, 특히 LSSL이 RNN과 같은 순환 구조를 가지고 있기 때문에 발생할 수 있습니다.
- LSSL은 긴 시퀀스 데이터를 처리할 수 있는 구조를 갖추고 있지만, 무작위(random initialized) 상태 행렬 를 사용할 경우 효과가 크지 않음을 경험적으로 확인하였습니다. (실험적으로 확인함)
- 해결책: 이를 해결하기 위해 HiPPO 프레임워크를 적용하여, 적절한 상태 전이 행렬 를 설계합니다. HiPPO는 시간에 따른 중요한 정보를 잘 유지할 수 있도록 상태 공간 모델을 최적화하여 기울기 소실 문제를 완화합니다.
- 문제: 상태 전이 행렬 를 무작위로 설정하거나 적절하게 설계하지 않으면, 긴 시퀀스를 처리할 때 기울기 소실 문제가 발생합니다. 이는 네트워크가 긴 시간 동안 중요한 정보를 유지하지 못하는 문제로, 특히 LSSL이 RNN과 같은 순환 구조를 가지고 있기 때문에 발생할 수 있습니다.
- 4.2 Theoretically Efficient Algorithms for the LSSL (연산 복잡도 문제):
- 문제: LSSL은 상태 전이 행렬 와 벡터의 곱셈(Matrix-Vector Multiplication, MVM)이나 Krylov 공간에서의 합성곱 연산이 포함되는데, 이 연산들이 매우 복잡하고 시간이 많이 걸릴 수 있습니다. 특히, 긴 시퀀스를 처리할 때 연산 복잡도가 커지는 문제가 있습니다.
- 해결책: 이를 해결하기 위해 Quasiseparable 행렬을 사용하여, 상태 전이 행렬의 특성을 활용한 효율적인 계산 방법을 제안합니다. Quasiseparable 행렬은 선형 시간 복잡도로 계산할 수 있으며, Krylov 공간에서의 연산을 더 빠르고 효율적으로 수행할 수 있게 해줍니다.
Empirical Evaluation
- 5.1 Image and Time Series Benchmarks: 시계열 이미지와 같은 데이터셋에서 LSSL의 성능을 평가한 실험 결과를 설명합니다. 여기에는 sMNIST, pMNIST, sCIFAR와 같은 유명한 벤치마크에서의 성능 비교가 포함됩니다.
- 5.2 Speech and Image Classification for Very Long Time Series: 매우 긴 시퀀스 데이터를 처리하는 음성 및 이미지 분류 문제에서 LSSL이 기존 모델보다 뛰어난 성능을 보였다는 점을 설명합니다.
- 5.3 Advantages of Recurrent, Convolutional, and Continuous-time Models: 재귀적, 컨볼루션, 연속-시간 모델의 장점을 모두 갖춘 LSSL의 장점을 강조합니다.
- 5.4 LSSL Ablations: Learning the Memory Dynamics and Timescale: LSSL이 시퀀스의 시간 스케일을 자동으로 학습할 수 있는 능력을 분석하고, 메모리 동력학을 학습하는 방법에 대한 실험 결과를 보여줍니다.


3. S4: Efficiently Modeling Long Sequences with Structured State Spaces (ICLR, 2022)

Introduction
- 이 섹션에서는 순차 데이터(sequence data) 모델링의 주요 과제인 장기 종속성(long-range dependencies) 문제를 다루며 기존의 모델(RNN, CNN, Transformer 등)이 긴 시퀀스를 처리하는 데 있어 겪는 문제점을 제시합니다.
- RNNs (Recurrent Neural Networks): RNN 계열 모델은 본래 순차 데이터 처리를 위해 개발되었으나, vanishing gradient(기울기 소실) 문제로 인해 긴 시퀀스를 처리하는 데 한계가 있습니다.
- CNNs (Convolutional Neural Networks): CNN은 시퀀스 길이를 확장하기 위해 dilated convolutions(확장된 컨볼루션) 등을 도입했으나 여전히 긴 시퀀스 처리에서 성능이 저하됩니다.
- Transformers: Transformers 모델은 대규모 시퀀스 처리에 널리 사용되지만, quadratic scaling(시퀀스 길이에 따른 연산 복잡도가 제곱에 비례) 문제로 인해 매우 긴 시퀀스에서는 비효율적입니다.
- 대안적 접근법으로 최근 연구에서는 상태 공간 모델(SSM)을 기반으로 한 접근법이 제안되었습니다. SSM은 제어 이론 등 다양한 분야에서 오래전부터 사용되어 온 모델로 시간에 따라 변화하는 상태를 표현하고, 이를 통해 장기적인 시계열 데이터를 처리할 수 있습니다. 그러나 기존 SSM을 딥러닝에 적용하는 데는 계산 비용과 메모리 사용량이 매우 크다는 한계에 봉착했습니다.
- 본 논문에서는 이러한 문제를 해결하기 위해 S4(Structured State Spaces) 모델을 제안합니다. 이 모델은 상태 공간 모델의 수학적 강점을 유지하면서도, 이를 더 효율적으로 계산할 수 있는 방법을 제공합니다.
- S4는 상태 행렬 A를 저랭크(low-rank)와 정규 행렬(normal matrix)로 분해하여 계산의 안정성과 효율성을 높입니다.
- 특히 S4는 Cauchy kernel을 사용하여 효율적인 계산을 가능하게 하며, 이로 인해 긴 시퀀스를 처리하는 데 필요한 연산량과 메모리 사용량을 크게 줄일 수 있습니다.
- Figure 1 설명
- (왼쪽) 상태 공간 모델: 상태 공간 모델은 입력 신호 가 주어졌을 때, 이를 은닉 상태 로 변환한 뒤, 최종적으로 출력 를 생성하는 시스템입니다.
- 상태 변환은 상태 행렬 , 입력 행렬 , 출력 행렬 , 그리고 스킵 연결을 담당하는 행렬 에 의해 정의됩니다.
- 이 모델은 제어 이론과 계산 신경과학에서 광범위하게 사용되며, 특히 연속 시간 시스템을 모델링하는 데 적합합니다.
- (중앙) 연속 시간 메모리 이론: 최근 연구에서는 특정 행렬 를 사용하면 SSM이 장기 종속성(Long-Range Dependencies, LRDs)을 수학적으로나 실험적으로 효과적으로 처리할 수 있음을 입증했습니다. (이전 연구)
- 이러한 행렬은 HiPPO라는 이론에서 유도된 특별한 행렬로, 입력의 긴 이력을 기억하는 데 최적화되어 있습니다.
- (오른쪽) 재귀 및 컨볼루션 표현: SSM은 두 가지 방식으로 계산할 수 있습니다. 재귀적 방식과 컨볼루션 방식.
- 재귀적 방식은 RNN처럼 순차적으로 계산되며, 컨볼루션 방식은 병렬화가 가능해 더 빠른 연산이 가능합니다.
- S4는 이러한 서로 다른 표현 간의 변환을 효율적으로 수행할 수 있도록 설계되었으며, 다양한 작업에 적합한 방식으로 효율적인 학습과 추론을 지원합니다.
- (왼쪽) 상태 공간 모델: 상태 공간 모델은 입력 신호 가 주어졌을 때, 이를 은닉 상태 로 변환한 뒤, 최종적으로 출력 를 생성하는 시스템입니다.

Method: Structured State Spaces (S4)
- 3.1 동기: 대각화 (Motivation: Diagonalization)
- 문제 정의 : 상태 공간 모델(SSM)의 중요한 문제는, 상태 공간의 크기가 커짐에 따라 연산 복잡도가 증가한다는 것입니다. 구체적으로, HiPPO 행렬 를 여러 번 곱하는 연산이 복잡도를 증가시키는 주 원인입니다. (∵상태 업데이트를 위해서는 A를 여러번 곱해야함)
- 상태 공간 모델에서 는 상태 갱신을 담당하는 핵심 행렬이며, 이를 사용하는 연산은 반복적으로 일어납니다. 를 직접 계산하면 에 달하는 연산량과 의 메모리 공간이 필요합니다. 이는 특히 대규모 시퀀스 모델링에서 병목이 됩니다.
이를 해결하기 위해, 켤레(conjugation)라는 수학적 기법을 도입하여 연산을 단순화할 수 있습니다.
- 상태 공간 모델에서 는 상태 갱신을 담당하는 핵심 행렬이며, 이를 사용하는 연산은 반복적으로 일어납니다. 를 직접 계산하면 에 달하는 연산량과 의 메모리 공간이 필요합니다. 이는 특히 대규모 시퀀스 모델링에서 병목이 됩니다.
- 문제 정의 : 상태 공간 모델(SSM)의 중요한 문제는, 상태 공간의 크기가 커짐에 따라 연산 복잡도가 증가한다는 것입니다. 구체적으로, HiPPO 행렬 를 여러 번 곱하는 연산이 복잡도를 증가시키는 주 원인입니다. (∵상태 업데이트를 위해서는 A를 여러번 곱해야함)
- Lemma 3.1: 켤레 관계 : 이 레마에서는 상태 공간 모델(SSM)의 행렬 , , 에 켤레 변환 을 적용하면 동일한 모델을 얻을 수 있음을 보여줍니다. 이 말은, 두 상태 공간 모델이 서로 동일한 정보를 표현하고 있지만 다른 좌표계에서 표현될 수 있다는 의미입니다. 이를 통해 시스템의 복잡한 계산을 더 단순화할 수 있습니다.켤레 변환의 의의
- 시스템 분석: 켤레 변환을 통해 시스템을 더 쉽게 분석할 수 있는 형태로 변환할 수 있습니다.
- 예를 들어, 대각화나 정규형으로의 변환이 가능합니다.
- 제어 설계: 상태 피드백 제어나 관측기 설계 시, 켤레 변환을 통해 더 간단한 형태의 시스템으로 변환하여 설계를 수행할 수 있습니다.
- 계산 효율: 특정 형태로의 변환을 통해 계산 효율을 높일 수 있습니다. 예를 들어, 대각 행렬은 계산이 매우 간단합니다.

- 두 개의 상태 공간 모델을 생각해 봅시다. 하나는 원래의 상태 벡터 를 사용하고, 다른 하나는 변환된 상태 벡터 를 사용합니다. 여기서 는 변환을 수행하는 행렬입니다.
- 각각의 상태 공간 방정식은 다음과 같습니다.
- 원래 상태 공간 모델:
- 변환된 상태 공간 모델:
- 원래 상태 공간 모델:
- 각각의 상태 공간 방정식은 다음과 같습니다.
- 이 두 모델은 동일한 시스템을 나타내며, 이는 켤레 변환 이 상태 공간 모델에서 동등 관계임을 의미합니다. 이를 통해 우리는 , , 행렬을 변환하여 동일한 연산을 다른 형태로 계산할 수 있게 됩니다. 켤레 관계는 아래 식으로 정의됩니다.
- 즉, 행렬 를 사용하여 상태 벡터 를 변환하면, 새로운 상태 벡터 로 변환된 시스템에서 더 효율적인 연산이 가능합니다.
- 행렬 를 로 변환하여 대각화하면, 가 대각 행렬일 때 계산이 단순해집니다.
- 시스템 분석: 켤레 변환을 통해 시스템을 더 쉽게 분석할 수 있는 형태로 변환할 수 있습니다.
- 켤레 관계의 의미 : 켤레 관계는 주로 복소수나 행렬에서 사용되는 개념입니다.
- 복소수에서의 켤레 : 복소수 a + bi의 켤레는 a - bi입니다. 켤레 복소수는 실수부는 같고 허수부의 부호만 반대입니다.
- 행렬에서의 켤레 전치 : 행렬 A의 켤레 전치(conjugate transpose)는 A*로 표기하며, 행렬을 전치한 후 각 원소를 켤레 복소수로 바꾼 것입니다
- 켤레 변환이란?
- 선형대수학에서 켤레 변환(conjugate transformation)은 복소수 행렬이나 벡터에 적용되는 중요한 연산입니다. 이 변환은 복소수 행렬에 대해 두 가지 연산을 순차적으로 수행합니다: ① 행렬을 전치(transpose)합니다. ② 각 원소를 켤레 복소수로 변환합니다
- Lemma 3.2: HiPPO 행렬의 대각화: 이 레마는 HiPPO 행렬 가 대각화될 수 있음을 보여줍니다. 여기서 대각화는 복잡한 행렬 연산을 더 단순하게 만들어주는 중요한 수학적 기법입니다.

- HiPPO 행렬은 시계열 데이터를 처리하기 위한 특정 유형의 행렬인데, 이 행렬의 대각화는 계산 효율성을 높이는 데 중요한 역할을 합니다.
- HiPPO 행렬 는 대각화될 수 있으며, 대각화에 사용되는 변환 행렬 와 행렬 의 각 항목 는 아래와 같이 정의됩니다.
- 이 식을 통해, 의 항목은 정도의 크기를 가집니다. 이 수식을 통해 HiPPO 행렬을 대각화하여 연산을 간소화할 수 있습니다.
- 3.2 S4 파라미터화: Normal Plus Low-Rank Parameterization (NLPR)
- 기본적인 HiPPO 행렬 는 대각 행렬이 아니며, 일반적으로 계산이 복잡합니다. 이를 해결하기 위해, 논문에서는 정규 행렬(normal matrix)과 저랭크 행렬(low-rank matrix)의 합으로 분해하는 기법을 제시합니다.
- 정의: 행렬을 뒤집고 복소수 부분의 부호를 바꾼 것(켤레 전치)과 원래 행렬을 곱했을 때, 순서를 바꿔도 같은 결과가 나오는 행렬입니다.
- 정규 행렬은 대각화가 가능하지만, HiPPO 행렬 자체는 이 속성을 만족하지 않으므로 이를 활용할 수 없습니다.
- 대신, HiPPO 행렬은 정규 행렬과 저랭크 행렬의 합으로 근사할 수 있습니다. 즉, 는 아래와 같이 분해됩니다.
- : 대각 행렬
- , : 저랭크 행렬
- 저랭크 행렬의 항목 수가 적기 때문에 계산이 효율적으로 이루어질 수 있으며, 이러한 분해는 NPLR (Normal Plus Low-Rank) 기법으로 알려져 있습니다. 이 방법을 사용하면, 를 여러 번 곱하는 연산의 복잡도를 대폭 줄일 수 있다고 합니다.
- (Theorem 1) 모든 HiPPO 행렬의 NPLR 표현 : 모든 HiPPO 행렬이 NPLR 표현을 가질 수 있음을 증명합니다. 이를 통해, S4 모델에서 사용되는 행렬 는 아래와 같이 표현됩니다.

- 는 대각 행렬
- 와 는 저랭크 행렬
- 저랭크 행렬 (Low-rank Matrix) : 저랭크 행렬은 복잡한 정보를 간단하게 표현할 수 있는 행렬입니다.
- 정의: 행렬의 랭크(독립적인 행 또는 열의 수)가 작은 행렬을 말합니다.
- 3.3 S4 Algorithms and Computational Complexity : 이 섹션에서는 S4 모델에서 제안하는 주요 알고리즘과 그 복잡도에 대해 설명합니다. 정리 2 와 정리 3 은 각각 재귀 연산과 컨볼루션 연산의 복잡도를 다룹니다.

- Theorem 2: S4 Recurrence에서는 재귀 연산의 복잡도를 으로 줄일 수 있음을 설명합니다. 재귀 연산은 상태 공간 모델에서 중요한 연산이며, 이를 효율적으로 수행하는 방법을 제안합니다.
- Theorem 3: S4 Convolution에서는 SSM의 컨볼루션 필터 를 계산하는 연산을 로 줄일 수 있음을 설명합니다. 이 필터는 시퀀스 모델에서 주로 사용되는 핵심 연산 중 하나입니다.
- 컨볼루션 필터의 계산은 4개의 케우시 곱셈(Cauchy multiplies)으로 이루어지며, 연산만 필요합니다. 이로 인해 S4 모델은 대규모 시퀀스 데이터를 처리하는 데 매우 효율적입니다.
- 케우시 곱셈(Cauchy Multiplication): 함수나 수열의 곱셈을 효율적으로 계산하는 방법으로, 다항식의 곱이나 컨볼루션 연산에서 사용됨.
Algorithm 1: S4 Convolution Kernel
- 알고리즘 1은 S4 컨볼루션 커널(S4 Convolution Kernel)을 계산하는 절차를 설명하고 있습니다. 이 알고리즘은 상태 공간 모델(SSM)을 기반으로 시퀀스 데이터에서 컨볼루션 필터를 효율적으로 계산하는 방법을 제시합니다. 아래 그림을 기준으로 설명합니다.
입력
- : 상태 공간 모델에서 상태 업데이트, 입력 및 출력에 관련된 S4 모델의 파라미터.
- : 시간 간격 또는 단계 크기(step size).
출력
- : S4 모델의 컨볼루션 커널 (SSM 최종 컨볼루션 필터)

단계별 설명
- ① SSM 생성 함수 계산
- 여기서, SSM 생성 함수(Generating Function) 는 아래와 같이 정의됩니다.
- 는 행렬 를 시간 단계 에 대해 제곱한 행렬을 의미합니다.
- 이 연산은 상태 공간 모델에서 상태 갱신을 나타내며, 와 결합하여 상태 공간의 출력을 계산할 수 있습니다. (참고로, C는 상태 공간 모델(SSM)의 출력 행렬)
- 은 단위 행렬 에서 행렬 을 뺀 것입니다. 이는 가 시스템에 미치는 영향을 반영하여 단위 행렬에서 일정 부분을 조정하는 역할을 합니다.
- 은 상태 공간 모델에서 여러 시간 스텝에 걸친 상태 변화를 고려합니다. 이를 통해 시스템의 현재 상태에 대한 정보를 추출하고, 시간이 지남에 따라 상태가 어떻게 변화하는지 계산한 후, 그 영향을 역으로 계산하는 역할을 합니다.
- 이 단계에서 최종적으로 를 계산하여 SSM을 나타내는 벡터를 얻습니다. 이를 통해 생성된 상태 벡터는 이후의 컨볼루션 커널 계산에 사용됩니다.
- ② SSM 케우시 곱셈 (Cauchy Multiplication)
- 의 각 성분을 아래와 같이 케우시 곱셈을 통해 계산합니다.
- 여기서 케우시 곱셈(Cauchy Multiplication)을 사용하여 복잡한 행렬 연산을 효율적으로 수행합니다. Cauchy 행렬은 특수한 형태의 행렬로, 여기에서는 와 행렬을 곱하여 최종 컨볼루션 필터 를 계산하는 데 사용됩니다.
- 는 대각 행렬이고, 와 는 S4 모델에서 상태와 입력에 대한 저랭크 행렬입니다.
- ③ Woodbury Identity 적용
- Woodbury Identity는 대규모 행렬의 역행렬을 계산할 때 사용하는 효율적인 방법입니다. 이를 적용하여 컨볼루션 필터의 계산을 더욱 간소화할 수 있습니다.
- Woodbury Identity는 저랭크 행렬을 포함하는 역행렬을 빠르게 계산할 수 있게 해주며, 형태의 행렬을 로 바꿔줍니다. 이로 인해 행렬 연산이 대폭 단순해집니다.
- ④ Evaluate(평가)
- 는 모든 근(roots of unity) 에서 평가됩니다.
- 이 단계에서 각 필터의 요소가 근을 통해 평가되고, 이를 통해 필터의 각 주파수 성분이 계산됩니다. (계산과정 아래 참고)
- 설정: 개의 단위 근 를 계산합니다.
- 계산: 각 에 대해 를 계산합니다. 이는 필터의 주파수 응답을 나타냅니다.
- 주파수 도메인에서의 연산: 계산된 를 사용하여 입력 신호의 주파수 성분과 곱셈을 수행합니다.
- ⑤ 역 FFT(Inverse FFT) 적용
- 마지막 단계에서 역 Fourier 변환(iFFT)을 사용하여 필터의 주파수 도메인 표현을 시간 도메인으로 변환합니다. 이 과정에서 최종적인 컨볼루션 커널 가 계산됩니다.
- 마지막 단계에서 역 Fourier 변환(iFFT)을 사용하여 필터의 주파수 도메인 표현을 시간 도메인으로 변환합니다. 이 과정에서 최종적인 컨볼루션 커널 가 계산됩니다.
Experiments
- 4.1 S4 Efficiency Benchmarks : S4는 기존의 상태 공간 모델 및 Transformer 모델에 비해 매우 빠른 학습 속도와 적은 메모리 사용량을 자랑합니다. 실험 결과, S4는 속도와 메모리 효율성 모두에서 우수한 성능을 보였습니다.
- 4.2 Learning Long Range Dependencies : Long Range Arena (LRA)** 벤치마크에서 S4는 장기 종속성을 처리하는 데 있어 탁월한 성능을 보여줍니다. 특히, 기존 모델들이 해결하지 못한 어려운 문제를 해결하는 데 성공하였습니다.
- 4.3 S4 as a General Sequence Model : S4는 이미지, 텍스트, 오디오 등 다양한 데이터 유형에서 사용될 수 있는 일반적인 시퀀스 모델로 제안됩니다. 실험을 통해 S4가 다양한 데이터 유형에서 뛰어난 성능을 발휘한다는 것을 확인할 수 있습니다.
- 4.4 SSM Ablations: the Importance of HiPPO : HiPPO 초기화를 사용한 상태 공간 모델이 성능 향상에 매우 중요하다는 것을 실험적으로 확인하였습니다.



'Artificial Intelligence > Artificial Intelligence Theory' 카테고리의 다른 글
| Deep Learning [3] : 트랜스포머 (Transformer) (0) | 2024.11.28 |
|---|---|
| Deep Learning [1] : 딥러닝 모델 개론과 정보 이론과 수학 (작성중) (0) | 2024.10.29 |