
생성형 모델은 데이터 생성 과정에 중점을 둔 모델로, 주어진 데이터셋과 유사한 새로운 데이터를 생성하기 위해 학습된다. 이 모델은 데이터의 잠재 확률 분포 p(x)를 학습하고, 이를 활용해 새로운 샘플을 생성하거나 기존 데이터의 특성을 이해하는 데 사용된다. 이 과정은 확률적이며, 데이터 생성이 랜덤 샘플링에 기반하기 때문에 같은 입력 데이터라도 결과가 달라질 수 있다. 생성 모델은 쉽게 말해 학습한 데이터를 흉내 내는 모델이라고 생각하면 쉽다. 예를 들어, 빵집에서 맛있는 빵을 만드는 비법을 배운다고 해보자. 이 모델은 빵집에서 맛있다고 평가받는 빵의 특징을 배우고 나서, 그 비슷한 빵을 만들어낸다. 완전히 똑같진 않지만, 빵집에서 만든 것과 유사한 느낌의 빵을 만들어낼 수 있는 것이다. 여기서 중요한 점은 빵집에서 어떤 빵을 만드는지 알고 있어야 비슷한 빵을 만들 수 있다는 것이다.

생성 모델에는 두 가지 방식이 있다. 첫 번째는 명확히 배우는 방법(Explicit)이다. 빵집에서 사용하는 정확한 재료의 양, 오븐의 온도, 굽는 시간을 꼼꼼히 배워서 이를 따라 빵을 만드는 것이다. 두 번째는 대충 짐작해서 배우는 방법(Implicit)이다. 여기서는 정확히 재료나 방법을 알지 못하지만, 빵의 맛과 향, 모양을 보고 흉내 내는 식으로 빵을 만든다. 다른 예시로 어떤 그림을 학습 데이터로 받았다고 생각해보자. 이 그림 속에는 구름, 나무, 강이 있는데, 생성 모델은 이런 요소들의 분포를 배워서 비슷한 풍경 그림을 만들어낸다. 학습 데이터에서 구름은 하늘 위에 있고, 강은 아래쪽에 있다는 정보를 잘 학습했다면, 새로 만든 그림에서도 그런 특징을 유지한다. 중요한 점은 학습 데이터의 특징(분포)을 얼마나 잘 배웠느냐가 새로 만든 그림이 원래와 얼마나 비슷한지를 결정한다는 것이다.

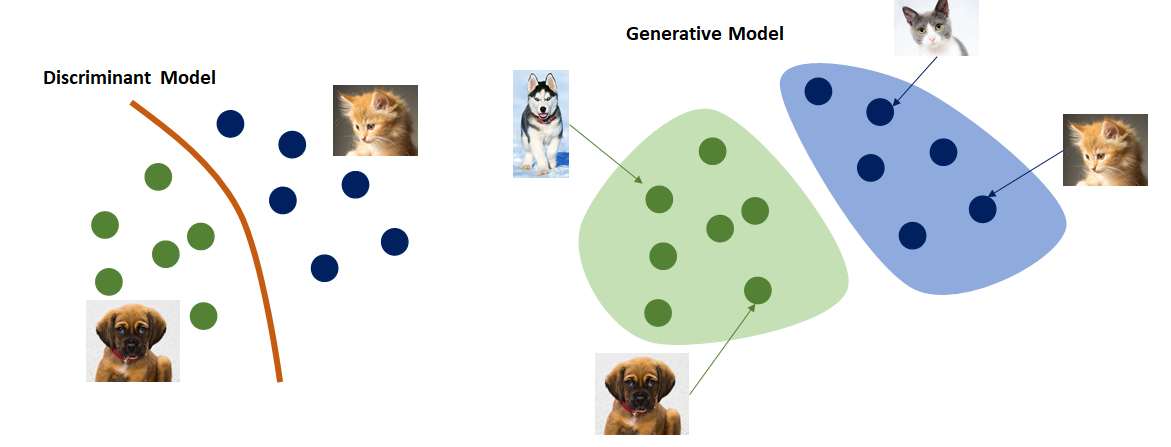
Discriminative 모델과 Generative 모델의 가장 큰 차이는 데이터 처리 방식과 목적에 있다. Discriminative 모델은 주어진 입력 데이터 x\mathbf{x}로부터 특정 클래스 yy를 예측하는 데 초점을 맞추며, 조건부 확률 p(y∣x)p(y|\mathbf{x})를 학습한다. 이는 데이터 간의 경계를 학습해 "이 데이터가 어떤 클래스에 속하는가?"라는 문제를 해결한다. 반면, Generative 모델은 데이터의 전체 분포 p(x)p(\mathbf{x}) 또는 p(x,y)p(\mathbf{x}, y)를 학습하여 데이터를 생성하거나 이해하는 데 중점을 둔다. 이를 통해 새로운 샘플을 생성하거나 기존 데이터의 특징을 모델링할 수 있다. 간단히 말해, Discriminative 모델은 데이터를 "판별"하는 데, Generative 모델은 데이터를 "생성"하거나 "이해"하는 데 사용된다.

Maximum Likelihood Estimation(MLE)
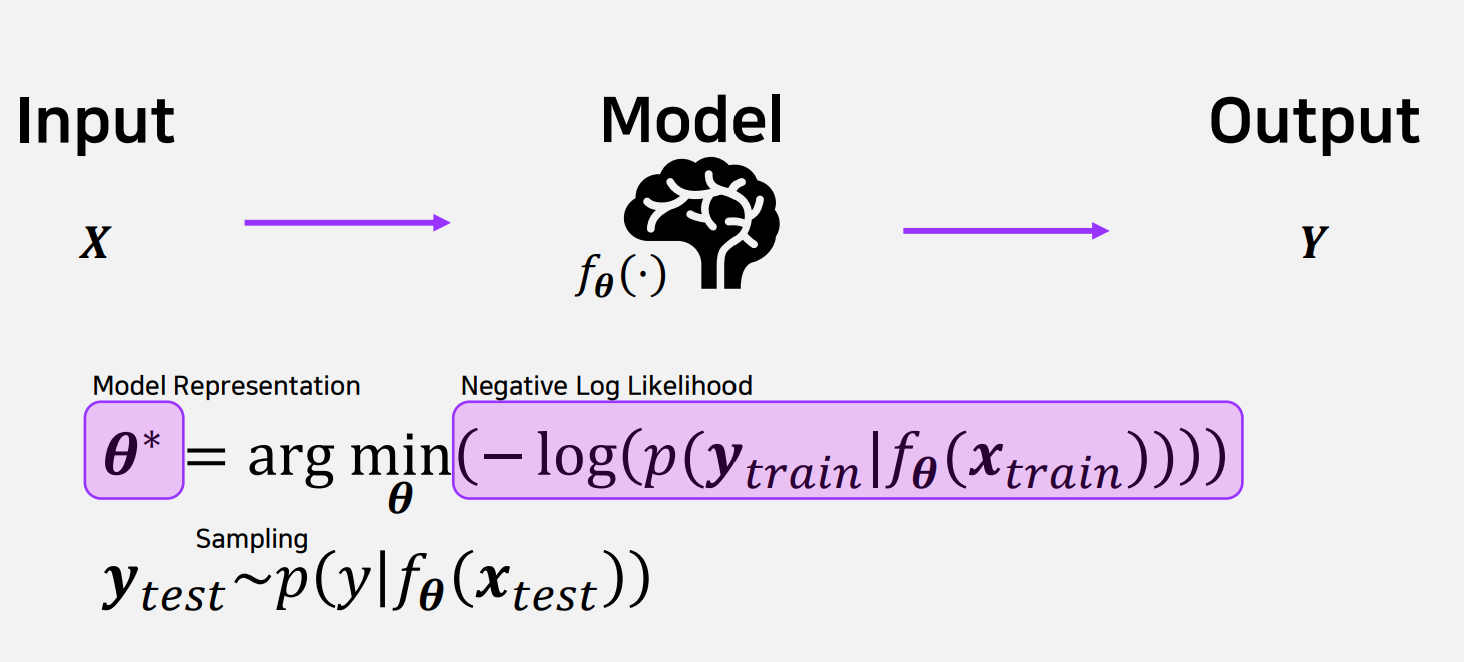
MLE는 주어진 데이터에 가장 잘 맞는 모델의 파라미터를 찾는 방법이다. MLE는 관측된 데이터가 발생할 가능성을 최대화하는 파라미터 θ를 찾아내는 것을 목표로 한다. 이를 위해 모델 fθ는 입력 데이터 와 출력 데이터 ytrain 간의 관계를 학습하며, p(ytrain∣fθ(xtrain)라는 확률 값을 계산한다. 그러나 우도를 직접 최대화하는 대신, 계산 효율성을 위해 로그를 취한 Negative Log-Likelihood(NLL)를 최소화하는 방식으로 표현된다. 이는 수학적으로 θ∗=argminθ−logp(ytrain∣fθ(xtrain))로 나타난다.
MLE의 과정은 모델이 입력 데이터를 받아 출력 데이터를 생성하도록 학습하는 것으로 시작된다. 여기서 모델은 데이터의 분포를 반영하는 확률 값을 계산하며, 파라미터 θ\theta를 조정해 NLL이 최소화되도록 최적화된다. 예를 들어, 데이터가 정규 분포를 따른다고 가정하면, MLE는 관측된 데이터로부터 평균과 분산을 추정해 데이터를 가장 잘 설명하는 분포를 찾는다. MLE는 모델이 데이터의 특성을 정확히 반영하도록 돕는 핵심적인 방법이며, 확률적 모델
에서 손실 함수로 자주 사용된다.
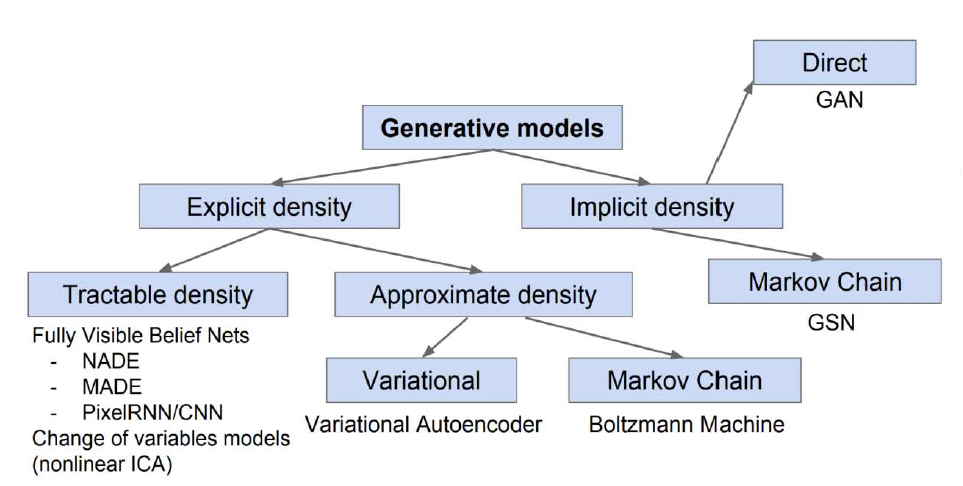
이러한 생성모델에는 여러가지 방식들이 있는데, 이 중에서 몇가지만 설명하자면, 학습 데이터의 분포를 기반으로 할 것인지(Explicit density) 혹은 그러한 분포를 몰라도 생성할 것인지(Implicit density)로 나뉘게 된다. 이러한 학습 데이터의 분포를 직접적으로 구하는 방법(Tractable density)이 있고, 이러한 분포를 단순히 추정하는 방법(Approximate density)이 있다. 여기에 추가적으로 생성모델 중에서도 가장 인기를 끌고 있는 적대적 생성모델(Generative Adversarial Network, GAN)도 있습니다.
1. Explicit density
1.1. Tractable density
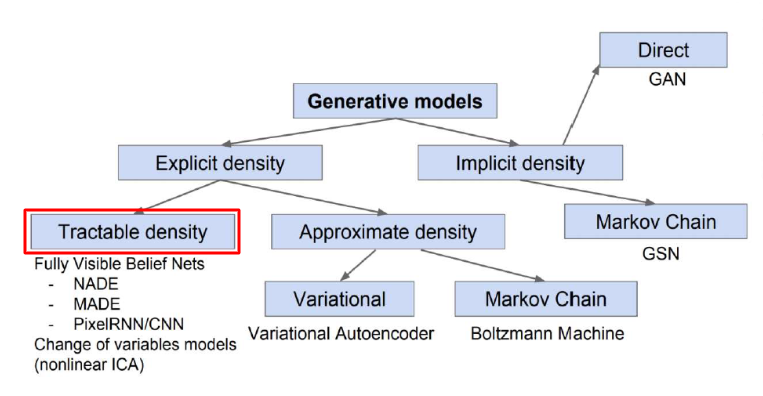
여기서는 직접적으로 학습 데이터의 분포를 학습하기 위해서, PixelRNN/CNN은 연쇄법칙(Chain rule)을 통해서 직접 구할 수 있다. 조금 더 설명하자면, 이전 픽셀들의 값을 통해서 현재 픽셀의 값을 결정하겠다는 것이다. 이렇게 하면 이미지 전체에 대해서 데이터를 생성할 수 있을 것이다. 여기서의 목표는 아래 함수를 최대화하는게 목표가 될 것이다.

1. AutoEncoder
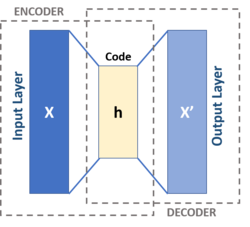
Autoencoder는 입력 데이터를 압축하고 이를 다시 복원하는 과정을 통해 데이터의 중요한 특징을 학습하는 신경망 모델이다. 이 모델은 크게 두 가지로 구성되며, 입력 데이터를 저차원 잠재 공간으로 변환하는 인코더(Encoder)와 이 잠재 표현을 기반으로 원래 데이터와 유사한 형태로 복원하는 디코더(Decoder)로 나뉜다. 인코더는 고차원의 입력 데이터를 저차원의 잠재 벡터로 압축하는 역할을 한다. 예를 들어, 이미지를 입력으로 받았을 때, 인코더는 해당 이미지의 중요한 특징만을 추출하여 이를 압축된 형태의 표현으로 변환한다. 이후 디코더는 이 압축된 잠재 벡터를 다시 원래의 도메인, 즉 초기 이미지와 유사한 형태로 복원한다. 이 과정은 데이터를 요약(압축)하고 다시 확장(복원)하는 일련의 작업으로, 데이터의 핵심 정보를 학습하여 저장하고 이를 바탕으로 원래 데이터와 최대한 비슷한 결과를 만들어내는 것을 목표로 한다.
2. Variational Autoencoder