
컴퓨터 비젼 수업의 기말 과제로 Panorama 이미지 생성 프로젝트를 진행했다. 수업 시간에 배운 수학적 원리와 이론을 활용하여 여러 이미지를 하나로 병합하는 과제이다. 코너 포인트 검출, 포인트 매칭, Homography 계산, 그리고 이미지 병합을 필수적으로 진행하고 선택적으로 이미지 전처리 및 노이즈 제거, RANSAC, 그룹 조정, 톤 매핑을 구현하면 추가 점수를 받는 방식이다. 모든 기능은 직접 구현했으며 코드는 로컬 이미지 데이터를 읽어 Panorama 이미지를 생성하고 결과를 화면에 출력하거나 저장했다.
0. 이미지 불러오기
import cv2
import os
# 이미지가 저장된 폴더 경로를 지정하세요
folder_path = 'your_folder_path_here' # 실제 폴더 경로로 변경하세요.
# 폴더 내의 모든 파일 목록 가져오기
file_names = os.listdir(folder_path)
# 이미지 파일만 필터링하기 (확장자별)
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']
image_files = [file for file in file_names if os.path.splitext(file)[1].lower() in image_extensions]
# 이미지 불러오기
images = []
for file_name in image_files:
img_path = os.path.join(folder_path, file_name)
img = cv2.imread(img_path)
if img is not None:
images.append(img)
else:
print(f"이미지를 불러올 수 없습니다: {img_path}")
# 이제 images 리스트에는 OpenCV로 불러온 이미지들이 저장되어 있습니다.
먼저, 파노라마에 사용할 이미지를 로컬 폴더에서 불러오는 작업이 필요하다
import cv2
import os
이미지 입출력을 위헤 OpenCV(cv2)와 Python의 표준 라이브러리인 os를 사용한다. OpenCV는 이미지 처리에 사용되는 라이브러리로, 이미지 읽기, 저장, 변환 등의 기능을 제공한다. os는 파일과 폴더를 다루는 데 필요한 기능을 제공하며, 여기서는 특정 폴더의 파일 목록을 가져오거나 경로를 결합하는 작업에 사용된다. 하지만 과제에서는 모두 직접 구현하는 것을 요구하고 있기 때문에 CV 라이브러리는 이미지를 불러오고 저장하는 외에는 사용하지 않는다.
folder_path = 'C:\Users\Jaehyun Byun\PycharmProjects\Panoramic\img'
folder_path는 이미지를 불러올 폴더의 경로를 지정하는 변수다. 이 값을 사용자가 원하는 폴더의 경로로 변경해야 한다. 이미지 파일들은 "C:\Users\Jaehyun Byun\PycharmProjects\Panoramic\img" 폴더에 저장되어 있기 때문에 folder_path를 이곳으로 설정해야 한다. 상대 경로를 사용할 수도 있는데 './images'는 현재 디렉터리의 images 폴더를 가리킨다.
file_names = os.listdir(folder_path)
os.listdir() 함수는 지정된 폴더 안에 있는 모든 파일과 디렉터리의 이름을 리스트로 반환한다. 이 단계에서는 해당 폴더 내의 모든 항목(이미지 파일뿐 아니라 다른 형식의 파일과 서브 디렉터리도 포함)을 가져온다. 예를 들어, 폴더 안에 image1.jpg, image2.png, document.txt가 있다면 file_names는 ['image1.jpg', 'image2.png', 'document.txt']가 된다.
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']
image_files = [file for file in file_names if os.path.splitext(file)[1].lower() in image_extensions]
image_extensions 변수는 불러올 이미지 파일의 확장자 목록을 정의한다. 확장자 필터링을 통해 이미지가 아닌 파일을 제외한다. os.path.splitext() 함수는 파일 이름과 확장자를 분리하며, .lower() 메서드는 확장자를 소문자로 변환해 대소문자 구분 없이 비교할 수 있게 한다. 예를 들어, file_names가 ['image1.jpg', 'image2.png', 'document.txt']라면, image_files는 ['image1.jpg', 'image2.png']가 된다.
images = []
for file_name in image_files:
img_path = os.path.join(folder_path, file_name)
img = cv2.imread(img_path)
if img is not None:
images.append(img)
else:
print(f"이미지를 불러올 수 없습니다: {img_path}")
이 단계에서는 image_files에 있는 파일 이름을 순회하며 이미지를 OpenCV로 불러온다. os.path.join(folder_path, file_name)을 사용해 파일 경로를 결합하고, cv2.imread()로 이미지를 읽어들인다. 성공적으로 불러온 이미지는 images 리스트에 추가되며, 실패한 경우에는 해당 파일 경로를 출력한다. 예를 들어, 폴더에 손상된 이미지가 있다면 오류 메시지가 출력되고, 정상적인 이미지만 images에 저장된다.
# 불러온 이미지의 개수 출력
print(f"불러온 이미지 개수: {len(images)}")
# 첫 번째 이미지를 출력
if len(images) > 0:
cv2.imshow('First Image', images[0])
cv2.waitKey(0)
cv2.destroyAllWindows()
최종적으로 images 리스트에는 OpenCV가 성공적으로 불러온 이미지가 numpy 배열 형태로 저장된다. 이 리스트는 이후 이미지 처리 작업에 사용할 수 있다. 예를 들어, 리스트의 첫 번째 이미지를 출력하거나 저장할 수 있다. 출력은 OpenCV의 cv2.imshow()를 사용하며, 리스트의 길이를 출력하여 불러온 이미지의 개수를 확인할 수도 있다.
for idx, img in enumerate(images):
cv2.imshow(f'Image {idx}', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
예를 들어 이 코드를 사용하면 불러온 이미지를 순서대로 화면에 표시할 수 있다.
1. 이미지 전처리, 노이즈 제거
Vision Theory [1] : 이미지의 정보와 처리
컴퓨터 비전에서는 이미지 정보와 처리의 원리를 잘 이해하는 것이 중요하다. 이미지 처리는 객체 인식, 추적, 분할 및 분석과 같은 컴퓨터 비전의 핵심 기술을 지원하며 효과적인 노이즈 제거,
metahyeon.tistory.com
여기서 배운 이론 내용을 토대로 Gaussian Filtering으로 Convolution 연산하는 과정을 직접 구현했다.
def gaussian_kernel(size, sigma):
"""2D Gaussian Kernel 생성"""
kernel = np.zeros((size, size), dtype=np.float32)
center = size // 2
for i in range(size):
for j in range(size):
diff = (i - center) ** 2 + (j - center) ** 2
kernel[i, j] = np.exp(-diff / (2 * sigma ** 2))
kernel /= np.sum(kernel) # 정규화
print(f"Gaussian Kernel 생성 완료 (크기: {size}, sigma: {sigma})")
return kernel
def apply_gaussian_filter(image, kernel):
"""이미지에 Gaussian Filter 적용"""
height, width, channels = image.shape
k_size = kernel.shape[0]
pad = k_size // 2
padded_image = np.pad(image, ((pad, pad), (pad, pad), (0, 0)), mode='constant', constant_values=0)
filtered_image = np.zeros_like(image)
print(f"이미지 크기: {image.shape}, 패딩 추가된 크기: {padded_image.shape}")
# Convolution 수행
for y in range(height):
if y % 100 == 0: # 100줄마다 진행 상황 표시
print(f"처리 중... {y}/{height} 줄 완료")
for x in range(width):
for c in range(channels): # 채널별 처리
region = padded_image[y:y + k_size, x:x + k_size, c]
filtered_image[y, x, c] = np.sum(region * kernel)
print(f"Gaussian Filter 적용 완료")
return filtered_image
# 이미지가 저장된 폴더 경로를 지정하세요
folder_path = 'C:/Users/Jaehyun Byun/PycharmProjects/Panoramic/img'
# 폴더 내의 모든 파일 목록 가져오기
file_names = os.listdir(folder_path)
print(f"폴더에서 {len(file_names)}개의 파일을 찾았습니다.")
# 이미지 파일만 필터링하기 (확장자별)
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.tiff']
image_files = [file for file in file_names if os.path.splitext(file)[1].lower() in image_extensions]
print(f"이미지 파일로 필터링된 파일 수: {len(image_files)}")
# Gaussian 커널 생성
kernel_size = 5 # 커널 크기 (홀수로 설정)
sigma = 1.0 # 표준 편차
gaussian_k = gaussian_kernel(kernel_size, sigma)
# 이미지 불러오기 및 Gaussian Smoothing Filter 적용
filtered_images = []
for idx, file_name in enumerate(image_files):
print(f"{idx+1}/{len(image_files)}: {file_name} 처리 중...")
img_path = os.path.join(folder_path, file_name)
img = cv2.imread(img_path)
if img is not None:
print(f"이미지 로드 성공: {file_name}, 크기: {img.shape}")
filtered_img = apply_gaussian_filter(img, gaussian_k)
filtered_images.append((file_name, filtered_img))
else:
print(f"이미지를 불러올 수 없습니다: {img_path}")
# 필터링된 이미지를 저장하거나 활용하기
output_folder = 'output_images' # 결과 이미지를 저장할 폴더 이름
os.makedirs(output_folder, exist_ok=True)
print(f"출력 폴더 생성 완료: {output_folder}")
for idx, (file_name, filtered_img) in enumerate(filtered_images):
output_path = os.path.join(output_folder, file_name)
cv2.imwrite(output_path, filtered_img)
print(f"{idx+1}/{len(filtered_images)}: 필터링된 이미지를 저장했습니다: {output_path}")
print("모든 작업이 완료되었습니다.")
Gaussian Kernel
먼저 2D Gaussian Kernel(가우시안 필터 커널)을 생성한다. 필터 크기와 표준 편차(σ)를 입력받아 커널을 계산하며, 가우시안 분포를 기반으로 각 요소의 값을 설정한다. 중심에서 멀어질수록 값이 작아지며, 커널 전체를 정규화하여 합이 1이 되도록 만든다.
def gaussian_kernel(size, sigma):
"""2D Gaussian Kernel 생성"""
가우시안 필터 커널을 생성하는 함수는 두 개의 매개변수를 받는다:
size: 커널의 크기로, 정사각형 행렬의 한 변의 길이를 의미한다. 예를 들어, size=5라면 5×5행렬이 생성된다. 반드시 홀수여야 중심이 명확히 정의된다.
sigma: Gaussian 분포의 표준 편차를 나타낸다. 값이 클수록 분포가 더 넓고 부드럽게 퍼진다.
kernel = np.zeros((size, size), dtype=np.float32) # size x size 크기의 빈 행렬 생성
이 코드는 size×size 크기의 2D 배열(행렬)을 생성하며, 초기값은 모두 0이다. 이 행렬은 Gaussian 커널의 값을 저장하기 위해 사용된다.
for i in range(size):
for j in range(size):
diff = (i - center) ** 2 + (j - center) ** 2 # 중심으로부터 거리 제곱
kernel[i, j] = np.exp(-diff / (2 * sigma ** 2)) # Gaussian 식 적용
커널의 각 위치에서 중심 좌표까지의 거리를 계산하고, 이를 Gaussian 함수에 대입해 값을 설정한다.

kernel /= np.sum(kernel) # 커널 정규화 (합이 1이 되도록)
Gaussian 커널의 모든 요소의 합을 계산하고, 각 요소를 그 합으로 나누어 정규화한다. 이를 통해 커널의 총합이 1이 된다. 정규화를 하지 않으면 필터를 적용한 이미지의 밝기가 원본과 달라질 수 있다.

정규화(Normalization)는 데이터의 값을 특정 범위로 변환하여 계산 효율성을 높이고, 알고리즘의 성능을 개선하는 데 사용되는 과정이다. 데이터 분석이나 기계 학습에서 흔히 사용되며, 특히 값의 범위가 크게 다르거나 특정 값이 지나치게 크거나 작은 경우 정규화를 통해 문제를 완화할 수 있다.
정규화의 대표적인 방식 중 하나는 최소-최대 정규화(Min-Max Normalization)다. 이 방식은 데이터의 값을 0과 1 사이로 변환하며, 다음 공식을 따른다.
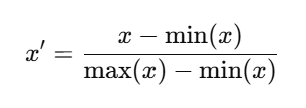
여기서:
- xx: 원본 데이터 값
- min(x): 데이터의 최소값
- max(x): 데이터의 최대값
- x′: 정규화된 값
이 공식은 각 데이터 값을 최소값을 기준으로 0부터 시작하게 만들고, 최대값에서 1로 끝나게 변환한다. 변환 후 모든 값은 0과 1 사이에 존재하며, 상대적인 크기는 유지된다. 예를 들어, x=[10,20,30,40,50]라는 데이터가 있다고 가정하자. 이 데이터의 최소값은 min(x)=10, 최대값은 max(x)=50이다.
정규화를 사용하는 이유는 다양하다. 예를 들어, 머신 러닝 알고리즘에서 입력 값의 범위가 다르면, 특정 값이 지나치게 큰 영향을 미칠 수 있다. 정규화를 통해 이러한 영향을 줄이고, 알고리즘이 데이터의 모든 특징을 고르게 학습할 수 있도록 한다. 또한, 정규화는 경사 하강법과 같은 최적화 알고리즘에서 수렴 속도를 높이고 계산의 안정성을 확보하는 데도 유리하다. 정규화는 상황에 따라 다른 방식으로 수행될 수 있다. 최소-최대 정규화 외에도 z-score 정규화(평균과 표준편차를 이용), 로깅 스케일(log scaling) 등 다양한 방법이 있다.
print(f"Gaussian Kernel 생성 완료 (크기: {size}, sigma: {sigma})")
return kernel
Gaussian Kernel 생성이 완료되었음을 출력하고, 생성된 커널을 반환한다
kernel = gaussian_kernel(5, 1.0)
Gaussian Filter
그 다음은 함수의 입력 이미지를 받아 Gaussian Kernel을 사용하여 Convolution 연산을 수행하고, 결과로 Gaussian Blur가 적용된 이미지를 반환한다. 이는 이미지를 부드럽게 만들어 노이즈를 제거하는 데 사용된다. 아래는 함수 내 각 코드와 계산 과정을 수식과 함께 자세히 설명한다.
def apply_gaussian_filter(image, kernel):
"""이미지에 Gaussian Filter 적용"""- image: Gaussian Blur를 적용할 입력 이미지. 이 이미지는 H×W×C의 크기를 가지며, 각각 높이, 너비, 채널(RGB 등)을 나타낸다.
- kernel: Gaussian Kernel(필터 행렬). k×k크기를 가지며, 이미지에 Convolution 연산을 수행하는 데 사용된다.
height, width, channels = image.shape
k_size = kernel.shape[0]
pad = k_size // 2- height, width, channels: 입력 이미지의 세 차원(높이, 너비, 채널 수)을 분리하여 저장한다.
- k_size: Gaussian Kernel의 크기를 가져온다. Kernel은 항상 정사각형이므로 k×k 형태이다.
- pad: Convolution 연산을 위해 이미지 경계에 패딩(padding)을 추가해야 한다. 패딩의 크기는 pad=k//2로 계산된다.
예를 들어:
- 입력 이미지 크기: 6×6×3 (RGB 이미지)
- Kernel 크기: 3×3
- 패딩 크기: 1 (경계 픽셀 1줄씩 추가)

패딩(Padding)은 Convolution 연산에서 중요한 역할을 하며, 이미지의 경계를 처리하는 방법이다. Convolution은 필터(Kernel)를 입력 이미지 위에서 이동시키며 연산을 수행하는 과정이다. 필터가 이미지의 가장자리에 도달하면, 경계 바깥의 값이 없기 때문에 필터를 완전히 적용할 수 없다. 이를 해결하기 위해 경계에 값을 추가(패딩)하여 문제를 해결한다.

패딩의 크기는 Kernel 크기에 의해 결정된다. 가 Kernel의 한 변의 길이(홀수)일 때, 패딩 크기는 다음과 같이 계산된다:

즉, Kernel의 크기에서 중심 값을 기준으로 양쪽 경계를 확장하는 것이다.
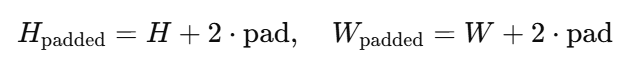
패딩은 여러 방식으로 추가할 수 있으며, 각 방식은 계산 결과에 영향을 미친다.
- Zero Padding (상수 값 패딩):

padded_image = np.pad(image, ((pad, pad), (pad, pad), (0, 0)), mode='constant', constant_values=0)
패딩을 추가하여 이미지를 확장한다. pad 크기만큼 경계를 0으로 채워 원본 이미지를 확장한다. 패딩을 추가하면 Kernel이 경계 픽셀을 포함한 모든 위치에 적용될 수 있다. 패딩 후 이미지 크기는 다음과 같다.

예를 들어:
- 원본 이미지 크기: 6×6×3
- 패딩 크기: 1
- 패딩된 이미지 크기: 8×8×3
filtered_image = np.zeros_like(image)
출력 이미지를 저장할 배열을 생성한다. 이 배열은 입력 이미지와 동일한 크기를 가지며, 초기값은 모두 0이다. 각 픽셀 위치에 Convolution 결과를 저장한다.
수식으로 표현하면:

for y in range(height):
if y % 100 == 0: # 100줄마다 진행 상황 표시
print(f"처리 중... {y}/{height} 줄 완료")
for x in range(width):
for c in range(channels): # 채널별 처리
region = padded_image[y:y + k_size, x:x + k_size, c]
filtered_image[y, x, c] = np.sum(region * kernel)
Convolution 연산은 Kernel을 이미지의 모든 픽셀에 적용하는 과정이다. (y,x) 위치에서 다음을 수행한다. 먼저 Region을 추출한다.

현재 픽셀 (y,x)를 중심으로 k×k크기의 지역(region)을 가져온다. 그 다음은 Kernel과의 곱셈 및 합산을 계산한다.

지역(region)과 Kernel의 각 요소를 곱한 후 그 합을 결과 이미지의 해당 위치에 저장한다.
Region 예시

print(f"Gaussian Filter 적용 완료")
return filtered_image
Convolution 연산이 모든 픽셀에 대해 완료되면, 필터링된 이미지를 반환한다. 출력 이미지에는 Gaussian Blur가 적용되어 원본 이미지보다 부드럽고 노이즈가 제거된 결과를 확인할 수 있다.


진행 과정 예시




2. 코너 포인트 찾기 (필수 구현)
Vision Theory [2] : 에지 검출
1. What are Edges? 이미지에서 밝기 변화가 급격히 일어나는 지점인 Discontinuities in intensity는 에지(edge)로 이는 물체의 형태와 구조를 정의하는 데 필수적이다. 예를 들어 풍경 사진에서 하늘과 땅의
metahyeon.tistory.com
Harris Corner Detection은 이미지에서 코너(모서리)를 찾는 알고리즘으로, 코너는 이미지에서 밝기 변화가 두 방향으로 모두 뚜렷한 지점을 말한다. 이 알고리즘은 주로 이미지의 특징을 추출하거나 객체를 추적하는 데 사용된다. 간단히 말해, Harris 코너 검출은 작은 창(window)을 이미지 상에서 이동시키며 밝기 변화량을 측정하는 방식으로 작동한다. 변화량이 가장 큰 지점이 바로 코너이다. 예를 들어, 체스판 이미지를 생각해보면, 체스판의 흑백 경계가 만나는 지점들이 코너로 검출된다. 수학적으로는, 이미지의 그라디언트를 활용하여 코너 응답 함수(특이값 분해 방식으로 측정된 에너지 값)를 계산하며, 이 값이 임계값을 넘는 지점을 코너로 판단한다. 이는 이미지의 텍스처 분석과 객체 인식에 매우 유용하다.
def to_grayscale(image):
"""이미지를 그레이스케일로 변환"""
print(f"[DEBUG] Converting image to grayscale. Image shape: {image.shape}")
if len(image.shape) == 3 and image.shape[2] == 3:
grayscale = 0.299 * image[:, :, 2] + 0.587 * image[:, :, 1] + 0.114 * image[:, :, 0]
grayscale = grayscale.astype(np.float32)
print(f"[DEBUG] Grayscale conversion using RGB weights completed.")
else:
grayscale = image.astype(np.float32)
print(f"[DEBUG] Image is already grayscale.")
print("그레이스케일 변환 완료")
return grayscale
def compute_image_gradients(image):
"""Sobel 필터를 사용하여 이미지 그라디언트 계산"""
print(f"[DEBUG] Computing image gradients. Image shape: {image.shape}")
# Sobel 커널 정의
sobel_x = np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]], dtype=np.float32)
sobel_y = np.array([[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]], dtype=np.float32)
k_size = sobel_x.shape[0]
pad = k_size // 2
padded_image = np.pad(image, ((pad, pad), (pad, pad)), mode='constant', constant_values=0)
print(f"[DEBUG] Padded image for gradients: {padded_image.shape}")
I_x = np.zeros_like(image, dtype=np.float32)
I_y = np.zeros_like(image, dtype=np.float32)
height, width = image.shape
print("그라디언트 계산 시작")
for y in range(height):
if y % max(1, height // 10) == 0: # 10% 진행 시마다 표시
print(f"[DEBUG] Gradient processing row {y+1}/{height} ({(y+1)/height*100:.1f}%)")
for x in range(width):
region = padded_image[y:y + k_size, x:x + k_size]
I_x[y, x] = np.sum(region * sobel_x)
I_y[y, x] = np.sum(region * sobel_y)
if y == 0 and x == 0:
print(f"[DEBUG] First gradient values: I_x={I_x[y, x]}, I_y={I_y[y, x]}")
print("그라디언트 계산 완료")
return I_x, I_y
def compute_harris_response(I_x, I_y, kernel, k=0.04):
"""Harris 응답 계산"""
print("[DEBUG] Computing Harris response.")
# Ixx, Iyy, Ixy 계산
Ixx = I_x ** 2
Iyy = I_y ** 2
Ixy = I_x * I_y
print(f"[DEBUG] Computed Ixx, Iyy, Ixy. Sample values: Ixx[0,0]={Ixx[0,0]}, Iyy[0,0]={Iyy[0,0]}, Ixy[0,0]={Ixy[0,0]}")
# Gaussian 필터 적용
print("Harris 응답을 위한 Ixx, Iyy, Ixy에 Gaussian 필터 적용")
Ixx = apply_gaussian_filter(Ixx[..., np.newaxis], kernel)[..., 0]
Iyy = apply_gaussian_filter(Iyy[..., np.newaxis], kernel)[..., 0]
Ixy = apply_gaussian_filter(Ixy[..., np.newaxis], kernel)[..., 0]
print(f"[DEBUG] Applied Gaussian filter to Ixx, Iyy, Ixy. Sample values: Ixx[0,0]={Ixx[0,0]}, Iyy[0,0]={Iyy[0,0]}, Ixy[0,0]={Ixy[0,0]}")
# Harris 응답 계산
print("Harris 응답 계산 중")
det_M = Ixx * Iyy - Ixy ** 2
trace_M = Ixx + Iyy
R = det_M - k * (trace_M ** 2)
print(f"[DEBUG] Computed Harris response R. Sample R[0,0]={R[0,0]}")
print("Harris 응답 계산 완료")
return R
def find_corners(R, threshold_ratio=0.01, window_size=3):
"""Harris 응답에서 코너 포인트 찾기"""
print("[DEBUG] Finding corners in Harris response.")
threshold = threshold_ratio * np.max(R)
print(f"코너 임계값 설정: {threshold}")
corners = []
height, width = R.shape
offset = window_size // 2
for y in range(offset, height - offset):
if y % max(1, height // 10) == 0: # 10% 진행 시마다 표시
print(f"[DEBUG] Corner detection processing row {y+1}/{height} ({(y+1)/height*100:.1f}%)")
for x in range(offset, width - offset):
window = R[y - offset:y + offset + 1, x - offset:x + offset + 1]
if R[y, x] == np.max(window) and R[y, x] > threshold:
corners.append((x, y))
if len(corners) <= 5: # 처음 5개 코너 포인트 출력
print(f"[DEBUG] Corner found at (x={x}, y={y}) with R={R[y, x]}")
print(f"총 {len(corners)}개의 코너 포인트 발견")
return corners
def mark_corners(image, corners, color=(0, 0, 255)):
"""코너 포인트를 이미지에 표시"""
print("[DEBUG] Marking corners on image.")
marked_image = image.copy()
for idx, (x, y) in enumerate(corners):
cv2.circle(marked_image, (x, y), radius=3, color=color, thickness=1)
if idx < 5: # 처음 5개 코너 포인트 표시
print(f"[DEBUG] Drawing circle at (x={x}, y={y})")
return marked_image
corners_dict = {}
# Harris 코너 검출 및 코너 표시
print("[DEBUG] Starting Harris corner detection on filtered images.")
for idx, (file_name, filtered_img) in enumerate(filtered_images):
print(f"{idx+1}/{len(filtered_images)}: {file_name}에 Harris 코너 검출 적용 중...")
grayscale = to_grayscale(filtered_img)
I_x, I_y = compute_image_gradients(grayscale)
R = compute_harris_response(I_x, I_y, gaussian_k, k=0.04)
corners = find_corners(R, threshold_ratio=0.01, window_size=3)
corners_dict[file_name] = corners
# 코너 포인트 시각화
marked_img = mark_corners(filtered_img, corners, color=(0, 0, 255))
# 필터링된 이미지와 코너가 표시된 이미지를 저장
output_folder = 'output_images'
os.makedirs(output_folder, exist_ok=True)
output_path = os.path.join(output_folder, f"corners_{file_name}")
cv2.imwrite(output_path, marked_img)
print(f"{idx+1}/{len(filtered_images)}: 코너가 표시된 이미지를 저장했습니다: {output_path}")
print("모든 작업이 완료되었습니다.")