C++ 라이브러리 정리
1. 자료구조
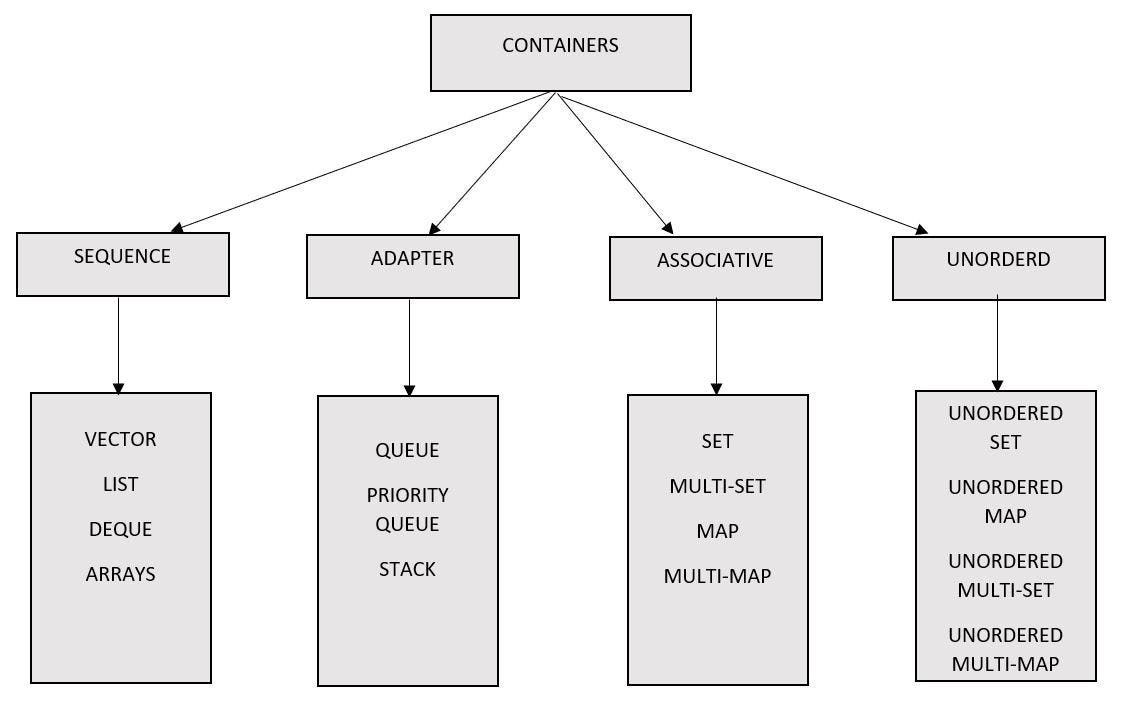
1.1 vector
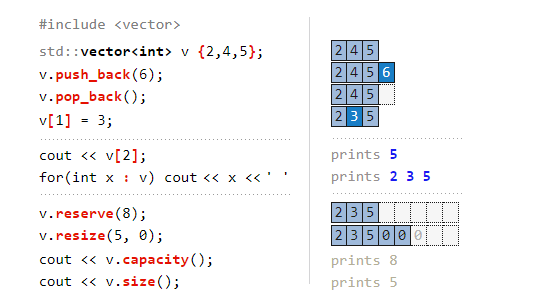
vector는 동적 배열로 크기를 자유롭게 변경할 수 있다. 인덱스를 통해 요소에 빠르게 접근할 수 있어 매우 효율적이다.
- push_back(value): 맨 뒤에 값을 추가한다.
- pop_back(): 맨 뒤의 값을 제거한다.
- size(): 요소의 개수를 반환한다.
- clear(): 모든 요소를 제거한다.
- resize(new_size): 크기를 변경한다.
- at(index): 특정 인덱스의 요소를 반환한다.
- sort(begin, end): 범위를 정렬한다(헤더 <algorithm> 필요).
int main() {
std::vector<int> vec = {3, 1, 4, 1, 5};
vec.push_back(9); // {3, 1, 4, 1, 5, 9}
vec.pop_back(); // {3, 1, 4, 1, 5}
std::sort(vec.begin(), vec.end()); // {1, 1, 3, 4, 5}
for (int val : vec) {
std::cout << val << " ";
}
return 0;
}
1.2 deque
deque는 양쪽 끝에서 삽입 및 삭제가 모두 가능한 자료구조다. 유연한 동작이 필요할 때 유용하다.
- push_front(value): 맨 앞에 값을 추가한다.
- push_back(value): 맨 뒤에 값을 추가한다.
- pop_front(): 맨 앞의 값을 제거한다.
- pop_back(): 맨 뒤의 값을 제거한다.
- front(): 맨 앞의 값을 반환한다.
- back(): 맨 뒤의 값을 반환한다.
int main() {
std::deque<int> dq;
dq.push_back(1); // {1}
dq.push_front(2); // {2, 1}
dq.pop_back(); // {2}
dq.push_back(3); // {2, 3}
for (int val : dq) {
std::cout << val << " ";
}
return 0;
}
1.3 set
set은 중복을 허용하지 않는 정렬된 집합이다. 탐색, 삽입, 삭제가 O(logN)에 가능하다.
자주 쓰는 함수:
- insert(value): 값을 추가한다.
- erase(value): 값을 제거한다.
- find(value): 값을 찾는다. 없으면 end() 반환.
- count(value): 값이 존재하면 1, 아니면 0 반환.
- clear(): 모든 요소를 제거한다.
int main() {
std::set<int> s;
s.insert(4);
s.insert(2);
s.insert(4); // 중복 값은 무시됨
s.erase(2);
for (int val : s) {
std::cout << val << " "; // {4}
}
return 0;
}
4. map
map은 키-값 쌍을 저장하는 자료구조로, 키를 기준으로 정렬된다. 탐색, 삽입, 삭제가 O(logN)에 가능하다.
- insert({key, value}): 키-값 쌍을 추가한다.
- erase(key): 특정 키를 제거한다.
- find(key): 특정 키를 찾는다.
- operator[key]: 키에 해당하는 값을 반환한다(없으면 생성).
int main() {
std::map<std::string, int> mp;
mp["apple"] = 3;
mp["banana"] = 5;
for (auto &[key, value] : mp) {
std::cout << key << ": " << value << "\n";
}
return 0;
}
5. priority_queue
priority_queue는 힙 기반의 우선순위 큐로, 기본적으로 최대 힙이다.
- push(value): 값을 추가한다.
- pop(): 최댓값(또는 최솟값)을 제거한다.
- top(): 최댓값(또는 최솟값)을 반환한다.
- empty(): 비어 있는지 확인한다.
int main() {
std::priority_queue<int, std::vector<int>, std::greater<int>> pq; // 최소 힙
pq.push(3);
pq.push(1);
pq.push(4);
while (!pq.empty()) {
std::cout << pq.top() << " "; // 1 3 4
pq.pop();
}
return 0;
}
6. unordered_map
unordered_map은 해시 기반의 키-값 쌍을 저장하며, 탐색과 삽입이 평균 O(1)이다.
- insert({key, value}): 키-값 쌍을 추가한다.
- erase(key): 특정 키를 제거한다.
- find(key): 특정 키를 찾는다.
- operator[key]: 키에 해당하는 값을 반환한다.
int main() {
std::unordered_map<std::string, int> ump;
ump["cat"] = 1;
ump["dog"] = 2;
if (ump.find("cat") != ump.end()) {
std::cout << "Found: " << ump["cat"] << "\n";
}
return 0;
}
7. stack
stack은 LIFO(Last In, First Out) 구조로, 가장 나중에 추가된 요소가 가장 먼저 제거된다.
특징:
- LIFO 원칙에 따라 동작.
- 주로 재귀적 알고리즘을 반복적으로 구현하거나 DFS(깊이 우선 탐색)에 활용.
자주 쓰는 함수:
- push(value): 스택의 맨 위에 값을 추가한다.
- pop(): 스택의 맨 위 값을 제거한다.
- top(): 스택의 맨 위 값을 반환한다.
- empty(): 스택이 비어 있는지 확인한다.
- size(): 스택의 크기를 반환한다.
int main() {
std::stack<int> st;
st.push(1);
st.push(2);
st.push(3);
while (!st.empty()) {
std::cout << st.top() << " "; // 3 2 1
st.pop();
}
return 0;
}
8. queue
queue는 FIFO(First In, First Out) 구조로, 먼저 추가된 요소가 가장 먼저 제거된다.
특징:
- FIFO 원칙에 따라 동작.
- BFS(너비 우선 탐색)나 데이터 스트림 처리에서 주로 사용.
자주 쓰는 함수:
- push(value): 큐의 맨 뒤에 값을 추가한다.
- pop(): 큐의 맨 앞 값을 제거한다.
- front(): 큐의 맨 앞 값을 반환한다.
- back(): 큐의 맨 뒤 값을 반환한다.
- empty(): 큐가 비어 있는지 확인한다.
- size(): 큐의 크기를 반환한다.
int main() {
std::queue<int> q;
q.push(1);
q.push(2);
q.push(3);
while (!q.empty()) {
std::cout << q.front() << " "; // 1 2 3
q.pop();
}
return 0;
}
9. list
list는 이중 연결 리스트로 구현된 자료구조다. 삽입, 삭제가 O(1)O(1)로 효율적이며, 순차적인 데이터 접근에 적합하다.
특징:
- 중간 삽입/삭제가 빠르다.
- 인덱스 기반 접근은 비효율적이다.
자주 쓰는 함수:
- push_back(value): 맨 뒤에 값을 추가한다.
- push_front(value): 맨 앞에 값을 추가한다.
- pop_back(): 맨 뒤 값을 제거한다.
- pop_front(): 맨 앞 값을 제거한다.
- insert(it, value): 특정 위치에 값을 삽입한다.
- erase(it): 특정 위치의 값을 제거한다.
int main() {
std::list<int> lst = {1, 2, 3};
lst.push_front(0); // {0, 1, 2, 3}
lst.push_back(4); // {0, 1, 2, 3, 4}
lst.erase(++lst.begin()); // {0, 2, 3, 4}
for (int val : lst) {
std::cout << val << " "; // 0 2 3 4
}
return 0;
}
10. string
C++의 std::string은 동적 문자열 자료구조로, 문자열 데이터를 효율적으로 저장, 조작, 처리할 수 있게 한다. 문자열은 코딩 테스트에서 자주 등장하는 데이터 유형이므로 중요한 메서드와 특징을 이해하는 것이 필요하다.
삽입 및 삭제
- append(str) 또는 +=: 문자열을 추가한다.
- insert(pos, str): 특정 위치에 문자열을 삽입한다.
- erase(pos, len): 특정 위치에서 지정한 길이만큼 문자열을 삭제한다.
- clear(): 문자열을 비운다.
탐색 및 조회
- size() 또는 length(): 문자열의 길이를 반환한다.
- find(str): 문자열에서 특정 문자열 또는 문자를 찾고, 시작 위치를 반환한다(없으면 std::string::npos 반환).
- rfind(str): 뒤에서부터 문자열을 검색한다.
- substr(pos, len): 특정 위치에서 길이만큼 부분 문자열을 반환한다.
- at(index): 특정 인덱스의 문자를 반환한다(경계 체크 포함).
변환 및 조작
- replace(pos, len, str): 문자열의 일부를 다른 문자열로 교체한다.
- to_string(num): 숫자를 문자열로 변환한다.
- stoi(str) 또는 stol(str): 문자열을 정수로 변환한다.
비교
- compare(str): 문자열을 비교하여 같으면 0, 작으면 음수, 크면 양수를 반환한다.
문자열 처리
- empty(): 문자열이 비어 있는지 확인한다.
- resize(n): 문자열 크기를 조정한다.
- swap(str): 두 문자열의 내용을 교환한다.
int main() {
std::string str = "Hello";
str += " World"; // "Hello World"
str.insert(5, ","); // "Hello, World"
str.erase(5, 1); // "Hello World"
str.replace(6, 5, "C++"); // "Hello C++"
std::cout << str << "\n"; // 출력: Hello C++
return 0;
}
2. 알고리즘
2.1 algorithm
algorithm 헤더는 다양한 알고리즘 함수들을 제공하며, 정렬, 탐색, 조합, 변환 등 다목적 작업을 쉽게 수행할 수 있다.
정렬 및 정리
- sort(begin, end): 지정한 범위를 오름차순으로 정렬한다.
- reverse(begin, end): 지정한 범위를 뒤집는다.
- unique(begin, end): 인접한 중복 요소를 제거한다(정렬된 상태 필요).
- rotate(begin, new_begin, end); 컨테이너의 요소를 회전시킨다. 첫 번째 요소를 새로운 시작 위치로 옮기고, 나머지 요소들을 순환 이동한다.
- partition(begin, end, condition); 주어진 조건에 따라 컨테이너를 분할한다. 조건을 만족하는 요소들은 앞쪽에, 만족하지 않는 요소들은 뒤쪽에 배치된다.
- merge(begin1, end1, begin2, end2, output); 이진 탐색
탐색
- lower_bound(begin, end, value): 정렬된 범위에서 value 이상의 첫 위치를 반환한다.
- upper_bound(begin, end, value): 정렬된 범위에서 value보다 큰 첫 위치를 반환한다.
- binary_search(begin, end, value): 정렬된 범위에서 value 존재 여부를 확인한다.
- find(begin, end, value); 특정 값을 찾아 첫 번째 위치를 반환한다. 값이 없으면 end()를 반환한다
- binary_search(begin, end, value);
조합 및 순열
- next_permutation(begin, end): 다음 순열로 변환한다.
- prev_permutation(begin, end): 이전 순열로 변환한다.
기타 유용한 함수
- max(a, b), min(a, b): 최대값과 최소값을 반환한다.
- accumulate(begin, end, init): 범위의 합을 계산한다(헤더 <numeric> 필요).
- count(begin, end, value): 범위에서 특정 값의 개수를 세어 반환한다.
2.1 cmath
cmath 헤더는 수학적 연산을 위한 함수를 제공한다. 삼각 함수, 지수 함수, 로그, 제곱근, 절대값 등을 다룰 수 있다.
기본 수학 연산
- abs(x): 절대값을 반환한다(정수/실수 모두 사용 가능).
- pow(base, exp): base를 exp 제곱한 값을 반환한다.
- sqrt(x): 제곱근을 반환한다.
삼각 함수
- sin(x), cos(x), tan(x): 각각 사인, 코사인, 탄젠트 값을 반환한다.
- asin(x), acos(x), atan(x): 역삼각 함수 값을 반환한다.
- atan2(y, x): y/x의 아크탄젠트를 반환한다(각도는 라디안).
로그 및 지수
- log(x): 자연로그(ln(x)\ln(x))를 반환한다.
- log10(x): 상용로그(log10(x)\log_{10}(x))를 반환한다.
- exp(x): exe^x 값을 반환한다.
반올림 및 절삭
- ceil(x): 올림값을 반환한다.
- floor(x): 내림값을 반환한다.
- round(x): 반올림값을 반환한다.
<vector>
동적 배열을 지원하는 STL 컨테이너로, 크기가 가변적이다. 요소를 추가하거나 삭제할 때 자동으로 크기를 조정한다.
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v = {5, 3, 8, 1};
v.push_back(10); // 요소 추가
sort(v.begin(), v.end()); // 정렬
// 크기와 용량
cout << "Size: " << v.size() << ", Capacity: " << v.capacity() << endl;
// 요소 제거
v.pop_back(); // 마지막 요소 제거
v.erase(v.begin() + 1); // 두 번째 요소 제거
// 특정 조건의 요소 제거
v.erase(remove(v.begin(), v.end(), 8), v.end()); // 값 8 제거
// 출력
for (int x : v) cout << x << " ";
return 0;
}
최대값
int max_value = *std::max_element(numbers.begin(), numbers.end())
회전
정의: 지정된 범위에서 요소를 왼쪽 또는 오른쪽으로 회전시키는 함수
헤더 파일: <algorithm>
사용법:
- first: 회전 범위의 시작 반복자.
- middle: 새로 시작할 위치(회전의 기준점).
- last: 회전 범위의 끝 반복자.
rotate(first, middle, last);
rotate(vec.begin(), vec.begin() + 2, vec.end());
rotate(vec.rbegin(), vec.rbegin() + 2, vec.rend());
동작 원리:
- [first, middle) 범위의 요소를 뒤로 이동.
- [middle, last) 범위의 요소를 앞으로 이동.
2. 입출력
<iostream>
표준 입출력을 위한 헤더 파일로, cin, cout과 같은 표준 입력과 출력을 사용할 수 있다. 예를 들어, 사용자 입력을 받거나 결과를 출력할 때 사용한다.
#include <iostream>
using namespace std;
int main() {
int x;
double y;
cout << "Enter an integer and a float: ";
cin >> x >> y; // 입력
cout << "You entered: " << x << " and " << y << endl; // 출력
cerr << "This is an error message." << endl; // 표준 에러 출력
clog << "This is a log message." << endl; // 로그 메시지 출력
return 0;
}
<algorithm>
정렬, 이분 탐색, 최대/최소값 찾기, 순열 생성 등 다양한 알고리즘 함수를 제공한다.
#include <algorithm>
#include <vector>
using namespace std;
int main() {
vector<int> v = {5, 3, 8, 1};
// 최대/최소
int maxVal = *max_element(v.begin(), v.end());
int minVal = *min_element(v.begin(), v.end());
// 이분 탐색
sort(v.begin(), v.end());
bool found = binary_search(v.begin(), v.end(), 3);
// 순열 생성
do {
for (int x : v) cout << x << " ";
cout << endl;
} while (next_permutation(v.begin(), v.end()));
return 0;
}
<cmath>
수학 함수들을 제공하며, 절댓값(abs), 제곱근(sqrt), 삼각 함수(sin, cos) 등을 포함한다.
#include <cmath>
#include <iostream>
using namespace std;
int main() {
double x = -8.3;
cout << "Absolute: " << abs(x) << endl; // 절댓값
cout << "Ceiling: " << ceil(x) << endl; // 올림
cout << "Floor: " << floor(x) << endl; // 내림
cout << "Round: " << round(x) << endl; // 반올림
cout << "Power: " << pow(2, 3) << endl; // 2^3
cout << "Logarithm: " << log(10) << endl; // 자연로그
cout << "Exponential: " << exp(1) << endl; // e^1
cout << "Square Root: " << sqrt(16) << endl; // 제곱근
cout << "Trigonometry (sin): " << sin(M_PI / 2) << endl; // 삼각 함수
return 0;
}
<string>
문자열을 다루기 위한 헤더 파일로, 문자열 비교, 연결, 부분 문자열 추출 등을 지원한다.
#include <string>
#include <iostream>
using namespace std;
int main() {
string s = "hello";
s.insert(5, " world"); // 삽입
s.replace(0, 5, "Hi"); // 대체
s.erase(0, 3); // 삭제
cout << "Substring: " << s.substr(0, 5) << endl; // 부분 문자열
cout << "Find: " << s.find("world") << endl; // 특정 문자열 찾기
cout << "Reverse: " << string(s.rbegin(), s.rend()) << endl; // 역순
return 0;
}
<queue>
FIFO(First-In-First-Out) 방식의 자료구조를 제공한다. priority_queue는 우선순위 큐를 지원한다.
#include <queue>
#include <iostream>
using namespace std;
int main() {
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
while (!q.empty()) {
cout << q.front() << " "; // 맨 앞 요소
q.pop(); // 제거
}
// 우선순위 큐 (기본: 최대 힙)
priority_queue<int> pq;
pq.push(10);
pq.push(5);
pq.push(20);
while (!pq.empty()) {
cout << pq.top() << " "; // 최대값
pq.pop();
}
return 0;
}
<stack>
LIFO(Last-In-First-Out) 방식의 자료구조를 제공한다.
#include <stack>
using namespace std;
stack<int> s;
s.push(1);
s.pop(); // 1 제거
<map>
키-값 쌍으로 이루어진 연관 컨테이너로, 키를 기준으로 정렬된 상태를 유지하며, 탐색, 삽입, 삭제 연산이 O(log N)이다.
#include <map>
#include <iostream>
using namespace std;
int main() {
map<string, int> m;
m["apple"] = 3;
m["banana"] = 5;
// 키로 값 접근
cout << "Apple: " << m["apple"] << endl;
// 반복문
for (auto &p : m) {
cout << p.first << ": " << p.second << endl;
}
// 특정 키 삭제
m.erase("banana");
return 0;
}
<set>
유일한 요소를 저장하며, 자동으로 정렬 상태를 유지한다. 삽입, 삭제, 탐색이 O(log N)이다.
#include <set>
#include <iostream>
using namespace std;
int main() {
set<int> s = {3, 1, 4};
// 요소 추가
s.insert(2);
// 요소 검색
if (s.find(3) != s.end()) {
cout << "Found 3" << endl;
}
// 요소 삭제
s.erase(3);
// 반복문
for (int x : s) {
cout << x << " ";
}
return 0;
}
<deque>
양쪽에서 삽입과 삭제가 가능한 자료구조이다. queue와 비슷하지만 앞뒤에서 삽입/삭제가 가능하다는 점이 다르다.
#include <deque>
#include <iostream>
using namespace std;
int main() {
deque<int> d = {1, 2, 3};
d.push_back(4); // 뒤에 추가
d.push_front(0); // 앞에 추가
d.pop_back(); // 뒤에서 제거
d.pop_front(); // 앞에서 제거
for (int x : d) {
cout << x << " ";
}
return 0;
}
<numeric>
accumulate, partial_sum 등 숫자 연산을 위한 함수를 제공한다.
#include <numeric>
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int> v = {1, 2, 3, 4};
int sum = accumulate(v.begin(), v.end(), 0); // 합계
cout << "Sum: " << sum << endl;
vector<int> partialSums(v.size());
partial_sum(v.begin(), v.end(), partialSums.begin()); // 부분 합
for (int x : partialSums) cout << x << " ";
return 0;
}
2. 빠른 입출력 설정
코딩 테스트에서는 입출력 속도가 중요한데, cin과 cout은 기본적으로 느리다. 이를 개선하기 위해 아래와 같이 설정하면 된다. C++ 표준 스트림(cin/cout)과 C 표준 스트림(scanf/printf)의 동기화를 끊어, 불필요한 작업을 제거해 입출력 속도를 높인다. 또 cin이 cout 버퍼를 자동으로 비우는 동작을 비활성화하여 추가적인 성능 향상을 제공한다.
ios::sync_with_stdio(false);
cin.tie(0);
이 설정을 사용할 때는 cin/cout과 scanf/printf를 혼용하면 버퍼 동기화 문제로 인해 예상치 못한 결과가 발생할 수 있으므로, 하나의 방식을 통일하여 사용하는 것이 중요하다.
3. 주요 내장 알고리즘
1. 이진 탐색 (Binary Search)
- binary_search
정렬된 컨테이너에서 특정 값이 존재하는지 확인하는 함수이다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 3, 5, 7, 9};
std::sort(v.begin(), v.end()); // 반드시 정렬되어 있어야 함
if (std::binary_search(v.begin(), v.end(), 5)) {
std::cout << "Found 5" << std::endl;
} else {
std::cout << "5 not found" << std::endl;
}
return 0;
}
2. 값의 삽입 위치 찾기
- lower_bound
특정 값 이상의 첫 위치를 반환한다. 정렬된 컨테이너에서 사용한다. - upper_bound
특정 값 초과의 첫 위치를 반환한다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 3, 3, 7, 9};
std::sort(v.begin(), v.end());
auto lower = std::lower_bound(v.begin(), v.end(), 3);
auto upper = std::upper_bound(v.begin(), v.end(), 3);
std::cout << "Lower bound of 3: " << (lower - v.begin()) << std::endl;
std::cout << "Upper bound of 3: " << (upper - v.begin()) << std::endl;
return 0;
}
3. 최댓값, 최솟값 찾기
- max_element / min_element
컨테이너에서 최댓값 또는 최솟값의 위치를 반환한다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {4, 2, 8, 6, 1};
auto maxIt = std::max_element(v.begin(), v.end());
auto minIt = std::min_element(v.begin(), v.end());
std::cout << "Max element: " << *maxIt << std::endl;
std::cout << "Min element: " << *minIt << std::endl;
return 0;
}
4. 부분합 계산
- accumulate
배열이나 벡터의 합을 구할 때 사용한다.
#include <iostream>
#include <vector>
#include <numeric>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
int sum = std::accumulate(v.begin(), v.end(), 0);
std::cout << "Sum: " << sum << std::endl;
return 0;
}
5. 중복 제거
- unique
중복된 요소를 제거할 때 사용한다. 정렬과 함께 사용하는 경우가 많다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 2, 2, 3, 4, 4, 5};
std::sort(v.begin(), v.end());
auto it = std::unique(v.begin(), v.end());
v.erase(it, v.end());
for (int x : v) std::cout << x << " ";
return 0;
}6. 정렬
- sort
기본 정렬 함수로, 기본적으로 오름차순으로 정렬한다.
비교 함수로 내림차순 정렬도 가능하다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {4, 2, 8, 6, 1};
std::sort(v.begin(), v.end()); // 오름차순
std::sort(v.begin(), v.end(), std::greater<int>()); // 내림차순
for (int x : v) std::cout << x << " ";
return 0;
}
7. 순열
- next_permutation다음 순열을 생성한다. 정렬된 상태에서 시작해야 한다.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 2, 3};
do {
for (int x : v) std::cout << x << " ";
std::cout << std::endl;
} while (std::next_permutation(v.begin(), v.end()));
return 0;
}
4. 매크로 정의
자주 사용하는 반복문, 상수 등을 매크로로 정의하면 코드를 더 간결하게 작성할 수 있다.
#define FOR(i, a, b) for (int i = a; i < b; ++i)
#define REP(i, n) FOR(i, 0, n)
#define ALL(v) (v).begin(), (v).end()
#define PB push_back
#define MP make_pair
#define F first
#define S second
5. 유용한 함수
자주 사용하는 함수를 미리 정의해 두면 편리하다.
// 최대공약수 (GCD)
int gcd(int a, int b) { return b == 0 ? a : gcd(b, a % b); }
// 최소공배수 (LCM)
int lcm(int a, int b) { return a / gcd(a, b) * b; }
// 소수 판별
bool isPrime(int n) {
if (n <= 1) return false;
for (int i = 2; i * i <= n; ++i)
if (n % i == 0) return false;
return true;
}
// 팩토리얼 계산
long long factorial(int n) {
return n == 0 ? 1 : n * factorial(n - 1);
}
// 좌표 이동 (상, 하, 좌, 우)
const int dx[4] = {-1, 1, 0, 0};
const int dy[4] = {0, 0, -1, 1};
// 빠른 제곱 계산 (거듭제곱)
long long power(long long base, int exp) {
long long result = 1;
while (exp > 0) {
if (exp % 2 == 1) result *= base;
base *= base;
exp /= 2;
}
return result;
}
// nCr 조합 계산
long long combination(int n, int r) {
if (r > n) return 0;
if (r == 0 || r == n) return 1;
return combination(n - 1, r - 1) + combination(n - 1, r);
}
// 범위 내의 소수 구하기 (에라토스테네스의 체)
vector<int> sieve(int n) {
vector<int> primes;
vector<bool> is_prime(n + 1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; ++i) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * 2; j <= n; j += i) {
is_prime[j] = false;
}
}
}
return primes;
}
// 유클리드 거리 계산
double euclideanDistance(int x1, int y1, int x2, int y2) {
return sqrt(pow(x2 - x1, 2) + pow(y2 - y1, 2));
}
// 문자열 반전
string reverseString(const string& str) {
return string(str.rbegin(), str.rend());
}
// 문자열을 공백 기준으로 분할
vector<string> split(const string& str, char delimiter) {
vector<string> tokens;
string token;
istringstream tokenStream(str);
while (getline(tokenStream, token, delimiter)) {
tokens.push_back(token);
}
return tokens;
}
// 숫자의 자리수 합 구하기
int digitSum(int n) {
int sum = 0;
while (n > 0) {
sum += n % 10;
n /= 10;
}
return sum;
}
// 이진수로 변환
string toBinary(int n) {
string binary;
while (n > 0) {
binary.push_back((n % 2) + '0');
n /= 2;
}
reverse(binary.begin(), binary.end());
return binary.empty() ? "0" : binary;
}
// 배열의 최댓값 찾기
int maxElement(const vector<int>& arr) {
return *max_element(arr.begin(), arr.end());
}
// 배열의 최솟값 찾기
int minElement(const vector<int>& arr) {
return *min_element(arr.begin(), arr.end());
}
// 배열 합 계산
int sumArray(const vector<int>& arr) {
return accumulate(arr.begin(), arr.end(), 0);
}
// 중복 제거 후 정렬된 배열 반환
vector<int> uniqueSortedArray(vector<int> arr) {
sort(arr.begin(), arr.end());
arr.erase(unique(arr.begin(), arr.end()), arr.end());
return arr;
}
// 두 점 사이의 맨해튼 거리
int manhattanDistance(int x1, int y1, int x2, int y2) {
return abs(x1 - x2) + abs(y1 - y2);
}
// 방향 벡터 (8방향 - 상, 하, 좌, 우, 대각선)
const int dx8[8] = {-1, 1, 0, 0, -1, -1, 1, 1};
const int dy8[8] = {0, 0, -1, 1, -1, 1, -1, 1};
// 배열 원소 찾기 (이진 탐색)
int binarySearch(const vector<int>& arr, int target) {
int left = 0, right = arr.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) return mid;
else if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1; // 찾지 못한 경우
}
// 모듈러 덧셈 (큰 수 연산)
long long modularAdd(long long a, long long b, long long mod) {
return ((a % mod) + (b % mod)) % mod;
}
// 모듈러 곱셈 (큰 수 연산)
long long modularMultiply(long long a, long long b, long long mod) {
return ((a % mod) * (b % mod)) % mod;
}6. 디버그용 매크로
디버깅을 빠르게 할 수 있는 매크로를 준비하면 문제 해결에 유리하다.
#define DEBUG(x) cout << #x << " = " << x << endl
int x = 42;
DEBUG(x); // 출력: x = 42
7. 템플릿 코드 구조
코딩 테스트에서 자주 사용하는 기본 코드 구조는 아래와 같다.
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
int t; // 테스트 케이스 개수
cin >> t;
while (t--) {
// 문제 풀이 코드
}
return 0;
}
8. 기타
띄어쓰기로 배열에 입력 넣기
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> numbers;
int num;
while (cin >> num) {
numbers.push_back(num);
}
return 0;
}
구조체 활용
struct STUDENT {
string name;
int korean;
int english;
int math;
}
C++의 유용한 함수
sort()
sort는 기본적으로 오름차순으로 정렬되지만, 이를 사용자 정의 함수로 원하는 기준에 맞게 변경할 수 있다.
std::sort(시작_이터레이터, 끝_이터레이터, 비교_함수);
여기서 비교_함수는 두 요소를 비교하는 함수로, 두 값을 받아 첫 번째 값이 두 번째 값보다 작으면 true를 반환해야 한다.
예제 1: 정수 배열을 내림차순으로 정렬
#include <iostream>
#include <vector>
#include <algorithm>
// 사용자 정의 비교 함수
bool customCompare(int a, int b) {
return a > b; // 내림차순
}
int main() {
std::vector<int> nums = {5, 2, 9, 1, 5, 6};
// 사용자 정의 함수로 정렬
std::sort(nums.begin(), nums.end(), customCompare);
// 결과 출력
for (int num : nums) {
std::cout << num << " ";
}
return 0;
}
위 예제에서 customCompare는 두 숫자를 비교하여 더 큰 숫자가 앞으로 오게 한다. 출력 결과는 9 6 5 5 2 1이다.
2. 구조체 또는 클래스 정렬
구조체나 클래스 데이터를 정렬하려면 특정 멤버 변수를 기준으로 비교해야 한다. 이를 위해 사용자 정의 비교 함수나 람다 함수를 사용할 수 있다.
예제 2: 구조체를 특정 멤버 변수로 정렬
#include <iostream>
#include <vector>
#include <algorithm>
// 구조체 정의
struct Person {
std::string name;
int age;
};
// 비교 함수: 나이 기준 오름차순
bool compareByAge(const Person &a, const Person &b) {
return a.age < b.age;
}
int main() {
std::vector<Person> people = {
{"Alice", 25},
{"Bob", 20},
{"Charlie", 30}
};
// 사용자 정의 함수로 정렬
std::sort(people.begin(), people.end(), compareByAge);
// 결과 출력
for (const auto &person : people) {
std::cout << person.name << " (" << person.age << ")\n";
}
return 0;
}
이 예제에서 compareByAge는 age 멤버를 기준으로 정렬한다. 출력 결과는 다음과 같다:
Bob (20)
Alice (25)
Charlie (30)
std::sort를 사용하여 정렬 기준을 지정하면 단순한 정수 배열뿐만 아니라, 복잡한 데이터 구조에도 적합한 정렬을 수행할 수 있다. 비교 함수는 유연하게 작성할 수 있으므로, 다중 기준 정렬이나 특정 조건에 따른 동작을 쉽게 구현할 수 있다.
복합 기준 정렬 (나이 -> 이름 순)
#include <iostream>
#include <vector>
#include <algorithm>
struct Person {
std::string name;
int age;
};
int main() {
std::vector<Person> people = {
{"Alice", 25},
{"Bob", 25},
{"Charlie", 30},
{"David", 20}
};
// 람다 함수로 복합 기준 정렬: 나이 -> 이름 순
std::sort(people.begin(), people.end(), [](const Person &a, const Person &b) {
if (a.age == b.age) {
return a.name < b.name; // 나이가 같으면 이름 기준 오름차순
}
return a.age < b.age; // 나이 기준 오름차순
});
// 결과 출력
for (const auto &person : people) {
std::cout << person.name << " (" << person.age << ")\n";
}
return 0;
}
복합 기준으로 정렬하여 나이를 기준으로 오름차순, 같은 나이에서는 이름을 기준으로 오름차순 정렬한다. 출력 결과는 다음과 같다:
David (20)
Alice (25)
Bob (25)
Charlie (30)
이처럼 C++의 std::sort는 매우 유연하며, 사용자 정의 비교 함수를 통해 다양한 정렬 요구를 충족할 수 있다. 이를 활용하면 간단한 데이터부터 복잡한 데이터 구조까지 효과적으로 정렬할 수 있다.
유용한 메서드 정리
배열의 중복값
bool Is_same(const vector<string>& vec) {
set<string> s(vec.begin(), vec.end());
return (s.size() != vec.size());
}
Set을 사용하여 중복 제거
string
substr(pos, count)는 원본 문자열에서 pos 인덱스부터 count개의 문자를 잘라서 새로운 문자열을 반환합니다.
'Development > Coding Test' 카테고리의 다른 글
| Coding Test [2]: SQL 프로그래밍 (SQL Programming) (0) | 2025.01.11 |
|---|---|
| Coding Test [0] : 코딩테스트 준비 (Coding Test Environment) (3) | 2024.12.27 |