
- Data Design and Implementation
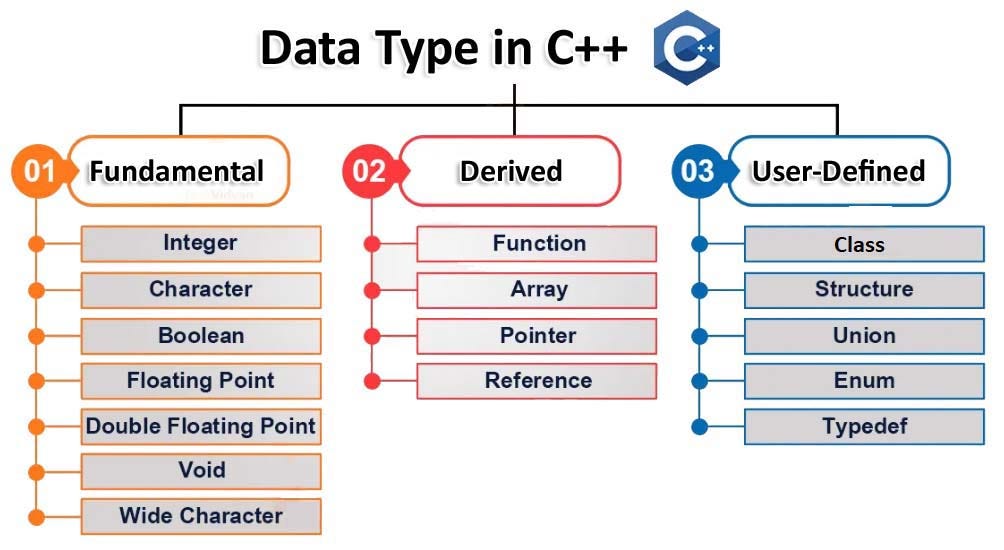
Data type
Data : 데이터는 프로그래밍 세계의 명사로 객체는 조작되는 대상, 정보는 처리되는 대상이다. C++는 다양한 데이터 유형을 제공하며 기본적인 데이터 유형은 크게 내장 유형과 복합 유형이 있다.
- 내장 유형
내장 유형은 프로그래밍 언어에 기본적으로 제공되는 데이터 유형이다. 프로그래머가 직접 정의하지 않고도 사용할 수 있는 유형이며, 일반적으로 언어의 가장 기본적인 데이터 요소를 나타낸다. 숫자형 , 문자열형, 논리형 , 불린형, 배열형, 객체형 등이 있다.
- 복합 데이터 유형(Composite Data Type)
복합 데이터 유형은 여러 개의 기본 데이터 유형을 결합하여 만들어진 데이터 유형으로 기본 데이터 유형을 조합하여 더 복잡한 데이터 구조를 만들 수 있도록 한다.
구조체(Struct): 이름 붙여진 속성 그룹으로 구성된 데이터 구조이다. 각 속성은 데이터 유형과 값을 가지고 있으묘 구조체는 사용자 정의 데이터 유형을 만드는 데 일반적으로 사용된다.
배열(Array): 동일한 데이터 유형의 값을 순서대로 저장하는 데이터 구조로 배열은 여러 개의 값을 효율적으로 저장하고 관리하는 데 사용된다.
이외에도 트리, 그래프, 연결리스트 등이 있다.
- 기타
포인터: 메모리 주소를 저장하는 데이터 형식으로 다른 데이터에 직접 접근하거나, 메모리 동적 할당을 수행하는 데 사용된다. 메모리 관리에 대한 직접적인 제어가 가능하며, 동적 데이터 구조를 구현하는 데 필수적인 요소이다.
참조: 객체 자체를 가리키는 별칭으로 포인터와 유사하지만, 자동으로 해제되고 NULL 값을 가질 수 없다는 점에서 차이가 있다. 객체에 대한 직접적인 접근을 제공하며 포인터보다 안전하고 사용하기 쉽고 객체에 대한 효율적인 접근을 가능하게 합니다.
데이터 추상화와 캡슐화
데이터 추상화 (Data Abstraction) : 데이터 유형의 논리적 속성을 구현 세부 정보와 분리하는 것을 의미하고 사용자는 데이터 유형이 무엇을 할 수 있는지, 어떻게 사용하는지에 대한 정보만 제공받고, 내부 작동 방식은 알 필요가 없다. 이를 통해 코드를 더욱 이해하기 쉽고 유지 관리하기 쉽게 만들 수 있습니다.
- Point 데이터 유형은 x 및 y 좌표를 나타내는 논리적 속성을 가지며 사용자는 Point 객체를 생성하고 좌표 값을 설정하고 거리 계산과 같은 작업을 수행할 수 있다. 하지만 Point 객체가 내부적으로 어떻게 표현되고 조작되는지는 알 필요가 없다.
캡슐화 (Data Encapsulation)는 데이터(속성)와 이를 조작하는 코드(메서드)를 하나의 단위(클래스 또는 구조체)로 묶는 것을 의미한다. 이를 통해 데이터를 외부 간섭으로부터 보호하고, 데이터 무결성을 유지하며, 코드의 재사용성을 높일 수 있다.
- BankAccount 클래스는 계좌 번호, 잔액, 입금 및 출금과 같은 메서드를 포함하는 데이터와 코드를 묶습니다. 이 캡슐화를 통해 외부 코드가 계좌 잔액을 직접 변경하는 것을 방지하고 데이터 무결성을 유지할 수 있다.
|
기준
|
추상화
|
캡슐화
|
|
초점
|
데이터 유형의 논리적 속성
|
데이터와 코드를 하나의 단위로 묶는 것
|
|
목적
|
코드를 더욱 이해하기 쉽고 유지 관리하기 쉽게 만드는 것
|
데이터를 보호하고 코드의 재사용성을 높이는 것
|
|
범위
|
데이터 유형 자체에 대한 개념
|
데이터와 코드를 포함하는 더 넓은 개념
|
ADT , Data Structures
ADT and Data Structures
Abstract Data Type (ADT) : 속성이 특정 구현과 독립적으로 지정된 데이터 유형으로 데이터의 논리적 속성에 초점을 맞춘 프로그래밍 개념이다. 데이터가 어떻게 구현되는지에 대한 세부 정보를 숨기고, 데이터를 조작하는 데 필요한 연산과 규칙만을 정의한다.
Data Structures : 자료 구조는 데이터 요소를 효율적으로 저장하고 관리하는 방법을 다루며 개별 데이터 요소를 체계적으로 구성하고 추상적 데이터 유형에서 복합 데이터 멤버를 구현한다. 자료구조의 특징은 다음과 같다.
1. 구성 요소로 분해 가능: 데이터 구조는 더 작은 구성 요소로 분해될 수 있다. 이러한 구성 요소들은 서로 연관되어 있지만, 독립적으로 작동할 수도 있다. 예를 들어, 연결 리스트라는 데이터 구조는 데이터 노드라는 구성 요소로 구성된다. 각 데이터 노드는 데이터 값과 다음 노드를 가리키는 포인터를 가지고 있다. 연결 리스트를 구성하는 데이터 노드들을 분해하면, 각 노드는 데이터 값과 다음 노드를 가리키는 포인터를 가지고 있는 독립적인 단위가 된다.
2. 요소 배열 방식이 액세스 방식에 영향: 데이터 요소들이 어떤 방식으로 배열되는지는 데이터에 대한 액세스 방법에 영향을 미칩니다. 예를 들어, 배열 데이터 구조는 데이터 요소들을 인덱스를 사용하여 액세스할 수 있습니다. 인덱스는 데이터 요소의 위치를 나타내는 값이다. 반면에 연결 리스트 데이터 구조는 데이터 요소들을 포인터를 사용하여 액세스해야 합니다. 포인터는 다음 데이터 요소를 직접 가리키는 주소값이다.
3. 요소 배열 및 액세스 방식 캡슐화: 데이터 구조는 데이터 요소들의 배열과 액세스 방법을 캡슐화할 수 있다. 캡슐화는 데이터 구조의 내부 구현을 외부 코드로부터 숨기고 데이터에 대한 접근을 제어하는 것을 의미한다. 이를 통해 데이터 구조의 변경으로 인해 프로그램의 다른 부분에 영향이 미치는 것을 방지하고, 코드의 재사용성과 유지 관리성을 높일 수 있다.
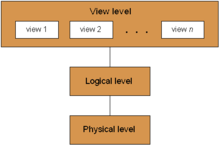
Data from 3 different levels
1. 응용 레벨(Application Level): 사용자 관점에서 데이터를 바라보는 레벨로 사용자가 실제로 프로그램과 상호작용하면서 다루는 데이터에 해당한다. 데이터의 의미와 해석에 중점을 두며, 데이터가 어떻게 저장되거나 구현되는지는 신경 쓰지 않는다.
- 독자가 실제로 책을 선택하고 읽는 부분이다. 독자는 책의 내용에 집중하며, 책이 어떻게 분류되고 보관되는지는 신경 쓰지 않는다.
2. 논리 레벨(Logical Level): 데이터의 구조와 관계에 초점을 둔 레벨로 데이터가 어떤 형태로 저장되고 서로 어떤 관계를 맺는지 정의한다. 실제 구현 세부 사항은 다루지 않지만, 데이터 간의 연결성과 제약 조건을 정의한다. 주로 추상 데이터 유형(ADT)를 사용하여 데이터를 정의합니다.
- 도서관 분류 체계이다. 책이 분야별로 분류되고 서로 관련된 책들이 함께 배치되는 방식을 말한다.
3. 구현 레벨(Implementation Level): 데이터가 실제로 컴퓨터 메모리에 어떻게 저장되고 관리되는지 다루는 레벨로 프로그램 개발자가 프로그램 언어의 특징을 이용하여 데이터를 구현하는 방법에 중점을 두고 있다. 데이터 구조(배열, 연결 리스트, 해시 테이블 등)를 사용하여 데이터를 저장하고 관리한다.
- 책장, 서랍, 서helves 등 실제 도서관에서 책을 물리적으로 보관하는 방식이다.
4 basic Type
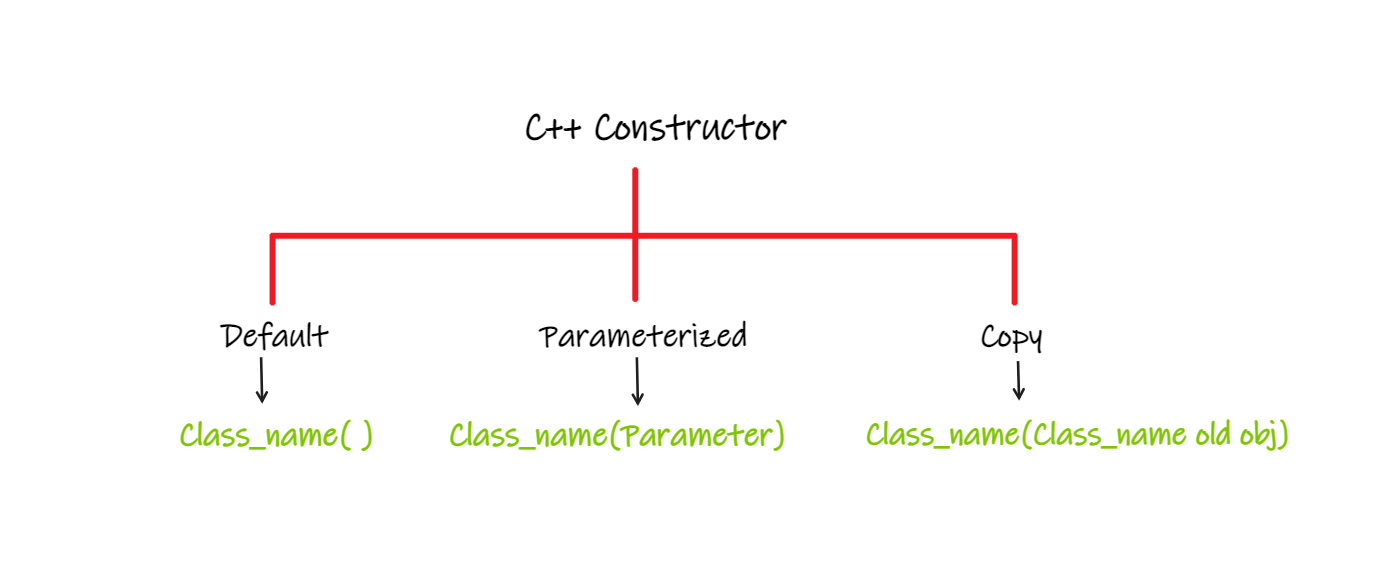
1. 생성자 (Constructor): 새로운 ADT 인스턴스를 생성하는 역할을 하며 일반적으로 초기값을 설정하거나 객체의 초기 상태를 정의하는 데 사용된다.생성자 이름은 클래스 또는 구조체 이름과 동일하며 반환값이 없다.
2. 변환자 (Transformer): 기존 ADT 인스턴스의 데이터를 변경하는 역할을 하며 변환자는 메서드 형태로 정의되어 ADT 인스턴스의 상태를 수정하거나 변형한다. 변환자는 일반적으로 반환값을 가지고 있으며, 변경된 데이터를 반환하거나 변경 여부를 나타내는 값을 반환할 수 있다.
3. 관찰자 (Observer): 기존 ADT 인스턴스의 데이터를 읽는 역할을 한다. 관찰자는 메서드 형태로 정의되며, ADT 인스턴스의 내부 상태를 직접 변경하지 않고 데이터를 확인한다. 관찰자는 일반적으로 반환값을 가지고 있으며, ADT 인스턴스의 현재 상태에 대한 정보를 반환한다.
4. 반복자 (Iterator): ADT 인스턴스에 저장된 데이터를 순차적으로 접근하는 역할을 하며 반복자는 데이터 컬렉션을 순회하면서 각 데이터 요소에 접근할 수 있는 방법을 제공한다. 반복자는 일반적으로 여러 메서드를 통해 데이터 컬렉션의 시작 위치로 이동, 다음 데이터 요소로 이동, 현재 데이터 요소 확인 등의 기능을 제공한다.
Records at the Logical level
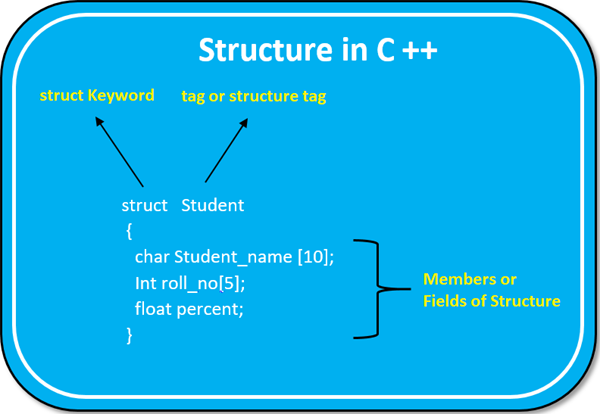
Structure in C++
레코드는 서로 관련된 데이터 필드들의 집합을 의미한다. 이는 하나의 논리적 단위로 묶여 처리되는 데이터 그룹이라고 생각하면 되며 레코드는 실제 메모리에서 어떻게 저장되는지와 상관없이 논리적 수준에서 정의된다. 데이터 추상화, 캡슐화, 데이터 조직이 가능하다.
- 구조체(struct): 구조체는 가장 기본적인 레코드 구현 방법으로 각 멤버 변수는 데이터 필드를 나타내고, 구조체 변수는 레코드 자체를 나타낸다.
- 클래스: 클래스는 객체 지향 프로그래밍에서 사용되는 레코드 구현 방법으로 구조체와 유사하게 데이터 필드를 나타내는 멤버 변수를 가지고 있지만, 메서드를 통해 레코드의 기능을 정의할 수 있다.
- 연합: 연합은 서로 다른 데이터 형식을 가진 데이터를 저장하는 데 사용되는 레코드 구현 방법으로 동시에 하나의 메모리 위치에 저장될 수 있는 여러 데이터 필드를 정의할 수 있다.
논리적 레벨의 레코드는 실제 메모리에서 어떻게 저장되는지와 상관없이 데이터를 구성하는 방식을 의미한다. 즉, 레코드는 배열, 링크드 리스트, 해시 테이블 등 다양한 데이터 구조를 사용하여 구현될 수 있다.
C++에서 구조체 멤버에 접근 멤버 참조 연산자(.)를 사용한다. 이 연산자는 구조체 변수 뒤에 멤버 이름을 붙여 사용하는데, 다음과 같이 구조체 멤버에 접근할 수 있다.
- 멤버 참조 연산자를 사용하기 위해서는 먼저 구조체 변수를 선언해야 하며 멤버 참조 연산자 뒤에는 접근하려는 멤버의 이름을 정확하게 작성해야 한다. 또한 구조체 멤버가 public으로 선언되어야 외부에서 접근할 수 있다. 멤버가 private으로 선언된 경우 해당 멤버에 대한 접근은 제한된다.
1. 같은 타입의 다른 구조체 변수에 할당 (Assignment)
구조체 변수는 다른 구조체 변수에 할당될 수 있다. 하지만 이는 단순한 메모리 복사가 아니라, 원본 구조체의 값을 복사본 구조체에 복사하는 작업이다.
2. 함수 매개변수로 전달 (Passing as a Parameter)
구조체 변수는 함수의 매개변수로 전달될 수 있다. 전달 방식은 값 복사 (pass by value) 또는 참조 복사 (pass by reference) 중 선택 가능다.
- 값 복사: 함수 호출 시 구조체의 값을 복사하여 함수에게 전달한다. 함수 내에서 변경된 값은 원본 구조체에 영향을 미치지 않는다.
- 참조 복사: 함수 호출 시 구조체 변수의 메모리 주소를 함수에게 전달한다. 함수 내에서 구조체 필드에 접근하여 값을 변경하면 원본 구조체에도 영향을 미친다.
3. 함수 반환값으로 사용 (Returning as a Function Value)
함수는 구조체 변수를 반환값으로 사용할 수 있다. 이때 반환되는 것은 구조체의 복사본이며, 원본 구조체와는 별개의 변수이다.
Record at Application level
응용 레벨에서 레코드는 여러 속성을 가진 객체를 모델링하는 데 유용하다.
- 객체 특성 모형화: 레코드는 현실 세계의 객체를 프로그램 내부에서 표현하는 데 효과적으로 객체의 다양한 특징을 하나의 레코드에 담아 모델링할 수 있다.
- 데이터 종합: 레코드는 한 객체에 대한 다양한 유형의 데이터를 한꺼번에 캡슐화할 수 있다. 숫자, 문자열, 부울 값, 다른 레코드 등 다양한 데이터 타입을 포함한다.
- 단일 이름 참조: 레코드 전체를 단일 이름으로 참조할 수 있어 코드 가독성과 유지보수성이 향상된다.
- 멤버별 접근: 레코드에 포함된 개별 속성(멤버)은 이름을 통해 별도로 접근할 수 있다. 특정 속성만 변경하거나 조회하는 것이 편리하다.
- 다른 데이터 구조체 정의: 레코드를 기반으로 사용자 정의 데이터 구조체를 정의할 수도 있으며 더 복잡한 데이터 관계를 표현하는 데 활용 가능하다.
Records at the Implementation level
레코드를 실제 프로그램에서 사용하기 위해서는 몇 가지 구현 작업이 필요하다.
1. 메모리 할당: 레코드를 생성하기 위해서는 먼저 데이터를 저장할 메모리 공간을 확보해야 하는데, 레코드에 포함된 각 멤버가 차지하는 메모리 크기가 다를 수 있으므로 필요한 총 메모리 양을 계산해야 한다.
2. 접근 함수 정의: 레코드에 저장된 데이터에 접근하기 위해서는 별도의 함수를 정의해야 하며 이 함수들은 레코드의 멤버 변수에 값을 할당하거나 읽어오는 역할을 수행한다.
- 기본 주소 (Base Address): 레코드 전체가 차지하는 메모리 영역에서 첫 번째 데이터 항목의 위치를 말한다. 레코드 전체에 대한 참조점 역할을 한다.
- 멤버 길이 오프셋 테이블 (Member-Length-Offset Table): 이 테이블은 레코드에 포함된 각 멤버의 정보를 담고 있습니다. 주요 내용은 다음과 같다. 멤버 이름, 멤버 데이터 타입 (이를 통해 멤버가 차지하는 메모리 크기를 계산), 오프셋 (Offset): 기본 주소를 기준으로 각 멤버가 위치한 메모리 상대 위치이다.
One-Dimensional Array ate the Logical Level
구조화된 복합 자료형 (Structured Composite Data Type): 배열은 여러 개의 데이터 요소를 하나의 단위로 묶은 자료 구조로 이 데이터 요소들은 서로 연결되어 있으며, 전체를 하나의 구조체로 다룰 수 있다.
유한하고 고정된 크기 (Finite, Fixed Size): 배열은 생성 시 크기를 정해야 하고, 이 크기는 프로그램 실행 중 변경할 수 없다. 컴파일 타임에 배열의 크기가 결정된다.
동일한 데이터 타입 (Homogeneous): 배열을 구성하는 모든 요소들은 같은 데이터 타입을 가져야 한다. 예를 들어 정수만 저장하는 배열이나 문자열만 저장하는 배열처럼, 모두 같은 종류의 데이터만을 담을 수 있다.
상대 위치 (Relative Positions): 배열의 각 요소는 서로 상대적인 위치를 가지고 있습니다. 첫 번째 요소, 두 번째 요소 등과 같은 식으로 구분된다.
직접 접근 (Direct Access): 배열의 모든 요소에는 인덱스를 사용하여 직접 접근할 수 있다. 인덱스는 0부터 시작하며, 특정 인덱스 값을 이용하여 원하는 요소의 데이터를 읽거나 쓸 수 있다.
Two-Dimensional Array ate the Logical Level
구조화된 복합 자료형 (Structured Composite Data Type): 2차원 배열은 여러 개의 데이터 요소를 하나의 단위로 묶은 자료 구조입니다. 이 데이터 요소들은 서로 연결되어 있으며, 전체를 하나의 구조체로 다룰 수 있다.
Class data type
범위 확인 연산자 ( :: )
C++ 클래스를 사용할 때 중요한 개념 중 하나가 범위 확인 연산자 ( :: )로, 여러 클래스가 같은 이름의 멤버 함수를 가질 수 있을 때 이 연산자를 사용하여 어떤 클래스의 멤버 함수를 호출할지 명확하게 구분한다.
예외 처리 (Exception Handling)

Exception Handling
예외는 프로그램 실행 흐름을 탈선시키는 특수 상황을 나타내는 객체이며, 이를 효과적으로 처리한다.
- 예외 (Exception): 에러 상황을 나타내는 객체입니다. 보통 어떤 문제가 발생했는지에 대한 정보를 담고 있으며, 기본 클래스 std::exception을 상속받아 만들어집니다.
- 예외처리 (Exception Handling): 예외 발생 조건을 정의하고, 그러한 조건이 발생했을 때 예외를 던지고(throw), 적절한 위치에서 예외를 처리하는(catch) 과정입니다.
- 에러 조건 정의 (Define the Error Condition): 코드에서 발생할 수 있는 에러 상황을 파악하고, 이를 어떻게 예외를 이용하여 알릴지 결정한다.
- 에러가 발생할 수 있는 코드 둘러싸기 (try block): 예외가 발생할 가능성이 있는 코드를 try 블록 안에 감싼다.
- 에러 발생 시 시스템 알림 (throw): 에러 조건이 감지되면 throw 키워드를 사용하여 예외 객체를 던진다. 이는 try 블록의 정상적인 실행 흐름을 멈추고 에러가 발생했음을 알리는 것이다.
- 던져진 에러 처리 (catch block): try 블록 뒤에 하나 이상의 catch 블록을 사용한다. catch 블록은 처리할 수 있는 예외의 타입을 지정하며 try 블록 내부에서 예외가 발생하면 제어 흐름은 해당 예외를 처리할 수 있는 첫 번째 catch 블록으로 이동한다. 그리고 해당 catch 블록 내의 코드가 실행되어 에러를 처리합니다.
네임스페이스 (Namespace) : 서로 다른 라이브러리나 모듈에서 같은 이름의 변수나 함수를 정의할 수 있지만, 네임스페이스를 사용하면 서로 구분하여 충돌을 방지할 수 있다.
- 각 참조마다 자격을 부여 (Qualify each reference)
- using 선언 (Using declaration)
Genaric Data tye
Operation이 정의되지만 조작되는 항목의 data type은 정의되지 않는 Type이다.
ADT Unsorted List Operations
.
함수의 이름은 관용적으로 적용되는 이름이기 때문에 그대로 사용한다.
Class Constructor : 클래스의 특수 member function으로 클래스 객체가 생성될 때 암시적으로 호출되는 함수이다. 객체 초기화 , 메모리 할당객체, 유효성 검사의 역할을 수행한다.
- 반환 값 없음: 생성자는 함수처럼 동작하지만 반환 값을 가지지 않고 객체를 생성하는 역할만 수행한다.
- 여러 생성자 정의: 클래스는 하나 이상의 생성자를 가질 수 있다. 이러한 생성자들은 매개변수(parameter)의 갯수와 타입에 따라 구분된다. 컴파일러는 객체를 생성할 때 사용되는 매개변수의 갯수와 타입을 비교하여 적합한 생성자를 호출한다.
- 매개변수 목록: 생성자는 매개변수 목록을 가질 수 있다. 이 매개변수들은 객체 생성 시 초기값을 설정하는 데 사용된다. 매개변수 목록은 클래스 객체를 선언할 때 괄호 안에 콤마(,)로 구분하여 나열한다.
- 기본 생성자 (Default Constructor): 매개변수가 없는 생성자를 기본 생성자라고 한다. 만약 클래스에 명시적으로 생성자를 정의하지 않으면 컴파일러가 기본 생성자를 자동으로 생성한다. 기본 생성자는 보통 멤버 변수들을 기본값 (예: int 0, string등)으로 초기화한다.
- 배열과 생성자: 만약 클래스에 적어도 하나의 생성자가 정의되어 있고, 이 클래스 객체로 이루어진 배열을 선언할 경우, 반드시 기본 생성자가 존재해야 한다. 배열의 각 요소를 생성할 때 기본 생성자가 자동으로 호출된다.
클래스 템플릿은 컴파일러가 템플릿 매개 변수를 이용하여 여러 종류의 클래스를 생성할 수 있는 기능이다. 즉, 클래스 설계도를 가지고 여러 데이터 타입을 사용할 수 있는 클래스를 만들 수 있다는 것이다.
- 템플릿 매개 변수: 클래스 설계도에서 데이터 타입을 대신하는 placeholder와 같은 역할을 하는 문자로 T와 같은 문자를 사용합니다.
- 실제 매개 변수: 클래스를 사용할 때 템플릿 매개 변수를 구체적인 데이터 타입으로 하는 값이다. 예를 들어 int나 double과 같은 실제 데이터 타입을 넣을 수 있다.
클래스 템플릿 정의에서는 꺾쇠 < > 안에 템플릿 매개 변수를 선언하고, 실제 클래스를 사용할 때는 같은 꺾쇠 안에 실제 매개 변수를 넣어 사용합니다.
ItemType Class
class ItemType는 템플릿(template) 클래스 또는 함수에서 사용되는 특수 키워드입니다. 템플릿은 코드를 재사용할 수 있도록 일반화하는 데 사용되는 강력한 프로그래밍 기능입니다. 템플릿 클래스 또는 함수는 특정 데이터 형식을 알 수 없이 정의할 수 있으며, 이후 Specifying class ItemType 키워드를 사용하여 실제 데이터 형식을 지정할 수 있습니다.
C++ 클래스 템플릿: 데이터 타입 재사용
C++ 클래스 템플릿은 클래스를 일반화하여 다양한 데이터 타입과 함께 작동하도록 하는 기능이다.
- 템플릿 매개 변수: 클래스 템플릿은 template<typename T>과 같은 선언문으로 시작하며, T는 템플릿 매개 변수이다.
- 실제 매개 변수: 클래스 템플릿을 사용할 때 T를 구체적인 데이터 타입으로 설정한다. 예를 들어, Vector<int>은 정수를 저장하는 벡터 클래스를 만들고, Vector<std::string>은 문자열을 저장하는 벡터 클래스를 만든다.
- 빌트인 또는 사용자 정의 데이터 타입: 템플릿 매개 변수로는 int, double, char과 같은 기본 데이터 타입이나 사용자가 정의한 클래스, 구조체 등을 사용할 수 있다.
Msg는 길이 8인 문자열 배열을 선언한다. Msg는 배열의 첫 번째 요소를 가리키는 포인터 역할을 한다. msg 는 포인터 상수이므로 프로그램 실행 중에 값을 변경할 수 없고 msg 를 사용하여 배열의 각 요소에 편리하게 접근할 수 있다.
msg[8]: msg라는 이름의 문자 배열을 선언한다. 이 배열은 8개의 char 타입 데이터를 저장할 수 있다. 이 코드에서 msg의 값 자체는 변경되지 않는다. 왜냐하면 msg는 선언된 배열의 주소를 가리키도록 고정되어 있기 때문이다. 배열의 내용은 수정할 수 있지만, msg가 가리키는 주소 자체는 변경할 수 없다.
컴퓨터 메모리는 작은 단위의 셀로 구성되어 있으며, 각 셀에는 고유한 주소가 있다. 변수를 선언하면, 컴퓨터는 해당 변수의 데이터 타입에 맞게 메모리 공간을 할당한다. 이 메모리 공간의 시작 주소가 변수 이름과 연결된다.
NULL 포인터
NULL 포인터는 유효한 메모리 위치를 가리키지 않는 포인터이다. 즉, 어떤 변수의 실제 값을 가리키지 않고, 가상의 없음을 나타낸다. 주의할 점은 NULL 포인터는 실제 메모리 주소 0과 동일하지 않다는 것이다.
- 포인터 초기화: 아직 할당되지 않은 포인터 변수를 초기화할 때 NULL을 사용하여 프로그램 실행 도중 잘못된 메모리 접근을 방지할 수 있다.
- 리스트의 끝 감지: 연결 리스트와 같은 자료 구조에서 마지막 노드를 구분하기 위해 NULL 포인터를 사용한다. while (ptr != NULL) 과 같은 코드는 포인터 ptr이 NULL이 아닌 동안 반복을 수행하는데, 이는 리스트를 순회하면서 마지막 노드에 도달하면 반복을 종료하는 방법이다.
- 절대 NULL 포인터를 역참조하면 안된다. 따라서 반드시 ptr != NULL 과 같이 NULL 여부를 검사하고 나서야 포인터를 사용해야한다.
정적 메모리와 동적 메모리
1. 정적 메모리 할당 (Static Allocation)
정적 메모리 할당은 프로그램이 컴파일될 때 메모리 공간을 확보하는 방식이다. 변수 선언 시 데이터 타입과 함께 변수 이름을 지정하면 컴파일러가 자동으로 메모리 공간을 할당한다. 프로그램 실행 기간 동안 메모리 할당 위치는 변경되지 않으며, 프로그램 종료 시 해당 메모리 공간이 자동으로 해제된다.
2. 동적 메모리 할당 (Dynamic Allocation)
동적 메모리 할당은 프로그램이 실행 도중 필요한 시점에 new 연산자를 이용하여 메모리 공간을 확보하는 방식으로 프로그램 실행 시점에 필요한 메모리 양을 파악할 수 있을 때 유용하다. 프로그램이 종료되거나 더 이상 필요하지 않은 경우 delete 연산자를 이용하여 메모리 공간을 해제해야 한다. 메모리 해제를 잊어버리면 메모리 누수 (memory leak)가 발생할 수 있다.
정적 데이터 (Static Data)
프로그램 실행 전반에 걸쳐 메모리 할당이 존재한다
- 컴파일 시 이미 메모리 위치가 결정되기 때문에 프로그램 실행 시 별도의 메모리 할당 과정이 필요하지 않아 속도가 빠르다.
- 메모리 초과 사용 (out-of-bounds)과 같은 문제가 발생하기 어려워 안전하다.
- 프로그램 실행 중에 필요한 메모리 양을 정확하게 예측하기 어려울 경우 미리 충분한 메모리를 할당해야 해 유연성이 부족하다.
자동 데이터 (Automatic Data)
함수 진입 시 자동으로 생성되고, 함수의 활성화 프레임에 상주하며, 함수에서 복귀할 때 소멸된다. 함수 내부에서 정의된 변수들은 모두 자동 데이터이다. 함수가 호출된 후 반환될 때까지 메모리를 유지하고 함수가 호출을 마치고 반환되면 자동으로 해제된다. 함수 외부에서는 접근할 수 없다.
동적 데이터 (Dynamic Data)
단항 연산자 new 및 delete를 사용하여 프로그래머가 작성한 C++ 명령어에 의해 프로그램 실행 중에 명시적으로 할당 및 할당 해제된다. 프로그램 실행 도중 필요한 시점에 new 연산자를 이용하여 메모리 공간을 명시적으로 할당한다. 프로그램 실행 중 필요한 기간 동안 유지된다.
- 메모리 요청: 프로그램이 new 연산자를 이용하여 메모리 할당을 요청한다.
- 프리 스토어 (free store, 힙) 검사: 시스템은 프리 스토어 (free store)라고 불리는 메모리 영역 (일반적으로 힙이라고도 불림)에서 요청된 크기만큼의 사용 가능한 메모리를 찾는다.
- 메모리 할당: 만약 사용 가능한 메모리가 충분하다면, new 연산자는 요청된 크기만큼의 메모리를 할당하고, 그 **메모리 영역의 시작 주소 (address)**를 포인터 형태로 반환한다.
- NULL 반환: 만약 사용 가능한 메모리가 부족한 경우, new 연산자는 NULL 포인터 (0) 를 반환합니다.
- new 연산자로 할당된 메모리는 더 이상 필요하지 않을 때 delete 연산자를 이용하여 명시적으로 해제해야 한다.
- 메모리 해제를 잊어버리면 메모리 누수 (memory leak)가 발생하여 프로그램 성능 저하를 야기할 수 있다.
new 연산자는 힙 (heap)이라고 불리는 메모리 영역에서 동적 메모리 할당을 수행한다.
보통 변수를 선언하면 프로그램 실행 시 메모리가 자동으로 할당된다. 하지만 프로그램 실행 중에 정확히 얼마나 많은 메모리가 필요한지 모르는 상황이 발생할 수 있습니다. 이런 경우 new 연산자를 사용하여 프로그램 실행 도중 필요한 시점에 메모리를 직접 할당할 수 있다.
new 연산자의 동작 과정
- 메모리 요청: 프로그램이 new 연산자 뒤에 객체 또는 배열 타입과 함께 메모리 할당을 요청합니다. 예시: int* ptr = new int; // 정수 저장을 위한 메모리 할당
- 힙 검사: 시스템은 힙と呼ばれる 메모리 영역에서 요청된 크기만큼 사용 가능한 공간이 있는지 확인합니다.
- 메모리 할당 성공:
- 만약 힙에 충분한 메모리가 있다면, new 연산자는 요청된 크기만큼 메모리를 할당하고, 그 **메모리 영역의 시작 주소 (address)**를 포인터 변수에 담아 반환합니다. 이 포인터를 통해 할당된 메모리에 접근할 수 있습니다.
- 메모리 할당 실패:
- 만약 힙에 충분한 메모리가 없다면, new 연산자는 NULL 포인터 (0) 를 반환합니다. 이는 메모리 할당에 실패했음을 의미합니다.
동적 메모리 해제
new 연산자로 할당된 메모리는 더 이상 필요하지 않을 때 delete 연산자를 이용하여 명시적으로 해제해야 합니다. 메모리 해제를 잊어버리면 **메모리 누수 (memory leak)**가 발생하여 프로그램 성능 저하를 야기할 수 있습니다.
동적 할당된 객체의 유지 기간
new 연산자를 통해 할당된 객체는 프로그램이 종료되거나 delete 연산자를 이용하여 메모리를 해제할 때까지 메모리에 존재합니다.
현재 포인터가 가리키는 개체나 배열은 할당이 취소되고 포인터는 할당되지 않은 것으로 간주됩니다. 메모리는 무료 저장소로 반환됩니다. 대괄호는 동적으로 할당된 클래스 배열을 할당 해제하기 위해 delete와 함께 사용됩니다.
위 코드는 동적 메모리 할당과 해제를 보여주는 예시입니다.
- char *ptr 선언: 문자열을 가리킬 수 있는 포인터 ptr 을 선언합니다.
- ptr = new char[5]: new 연산자를 이용하여 5개의 문자를 저장할 수 있는 메모리 공간을 동적으로 할당하고, 그 주소를 ptr 에 저장합니다.
- strcpy(ptr, "Bye"): strcpy 함수를 이용하여 문자열 "Bye"를 ptr이 가리키는 메모리 공간에 복사합니다. (실제로는 \0 문자를 포함하여 6칸 할당)
- ptr[1] = 'u': ptr이 가리키는 배열의 두 번째 요소 (인덱스 1)를 'u' 문자로 변경합니다. 이제 문자열은 "Buye"가 됩니다.
- delete ptr: delete 연산자를 이용하여 ptr이 가리키는 메모리 공간을 해제합니다. 동적 할당된 메모리가 해제되면서 "Buye" 문자열이 저장되어 있던 공간은 사용할 수 없게 됩니다.
주의사항
- delete ptr 코드는 포인터가 가리키는 배열의 메모리만 해제합니다.
- ptr 포인터 자체는 해제되지 않고 아직 메모리 어딘가를 가리키고 있을 수도 있습니다.
- 이 경우 ptr의 값은 예측할 수 없으며 더 이상 사용해서는 안됩니다.
메모리 누수
메모리 누수는 프로그램 실행 중 동적 메모리 할당(new 연산자) 후 해당 메모리를 해제할 수 없는 상황을 말한다.
위 코드에서 ptr은 처음에 메모리를 할당받았지만, 새로운 포인터 ptr2가 할당되면서 더 이상 사용되지 않는다. 하지만 delete ptr;를 이용하여 해제되지 않아 메모리 누수가 발생한다.
메모리 누수 외에도 다음과 같은 경우 객체에 접근할 수 없게 됩니다.
- 스코프 벗어남 (Scope Out of Reach): 지역 변수 또는 블록 내부에서 선언된 객체는 해당 스코프를 벗어나면 더 이상 접근할 수 없다.
- 포인터 해제 (Deallocated Pointer): delete 연산자를 이용하여 동적 메모리 해제를 수행하면 해당 객체에 더 이상 접근할 수 없습니다.
- 순환 참조 (Circular Reference): 두 객체가 서로 서로를 가리키는 경우 적절한 메모리 해제 없이는 객체에 접근하기 어려울 수 있습니다. (가비지 콜렉터가 없는 C++에서는 특히 주의
I'd be glad to explain dangling pointers in C++ in Korean:
Dangling 포인터란 포인터가 더 이상 유효하지 않은 메모리 위치를 가리키는 경우를 말합니다. 이는 프로그램에서 예기치 못한 동작, 충돌(crash), 보안 문제 등을 야기할 수 있는 심각한 버그의 원인이 될 수 있습니다.
다음과 같은 상황에서 Dangling 포인터가 발생합니다.
- 메모리 해제 (delete) 후 사용:
- new 연산자를 사용하여 힙 메모리를 할당하고, 포인터를 사용하여 해당 메모리에 데이터를 저장합니다.
- 이후 delete 연산자를 사용하여 메모리를 해제하지만, 여전히 해당 메모리 위치를 가리키는 포인터를 사용하려고 합니다. 이 경우 포인터는 더 이상 유효한 메모리 위치를 가리키고 있으므로 메모리 접근 위험이 발생합니다.
Specifying class ItemType
Class ItemType
ItemType 클래스는 아이템을 나타내는 클래스이며 공통되는 기능을 제공한다.
- RelationType ComparedTo(ItemType other) const: 두 ItemType 객체를 비교하여 관계를 반환한다. 반환값은 RelationType 열거형의 값, 즉 LESS, EQUAL, GREATER 중 하나이다.
- void Print() const: 객체의 데이터(value)를 출력한다. 출력 형식은 구현에 따라 다를 수 있다.
- void Initialize(int number): 객체의 데이터(value)를 매개변수로 받은 number 값으로 초기화한다.
Implement
여러 알고리즘 비교: 어떻게 선택할까?
같은 작업을 수행하는 여러 가지 알고리즘이 존재할 때 효율성 측면을 비교하여 최적의 알고리즘을 선택하는 것이 중요하다.
프로그램 작성 시간 vs. 프로그램 실행 시간 : 일반적으로 알고리즘 자체의 효율성은 프로그램 실행 시간에 더 큰 영향을 미친다. 즉, 좀 더 복잡한 알고리즘을 사용하더라도 프로그램 실행 시간이 훨씬 짧다면 그 복잡한 알고리즘을 선택하는 것이 더 유리할 수 있다.
객관적인 측정 방법: 알고리즘의 효율성을 비교하기 위해서는 객관적인 측정 방법을 사용해야 한다. 대표적인 방법으로는 다음과 같은 것들이 있습니다.
- 실행 시간 (Execution time): 프로그램이 실제로 실행되는 데 걸리는 시간입니다. 보통 초 (second)나 밀리초 (millisecond) 단위로 측정됩니다.
- 명령문 수 (Number of statements): 프로그램을 구성하는 명령문의 총 개수입니다. 하지만 단순히 명령문 수만 가지고 효율성을 판단하기는 어렵습니다.
- 기본 연산 개수 (Number of fundamental operations): 알고리즘이 수행하는 기본적인 연산 (덧셈, koszulka 鑓繰り (카리쓰기), 비교 등)의 총 개수입니다. 이는 일반적으로 알고리즘의 시간 복잡도와 연관이 있습니다.
- 비용이 많이 드는 연산 빈도 (Frequency of expensive operations): 특히 많은 시간을 소요하는 연산이 얼마나 자주 발생하는지도 고려해야 합니다.
- 문제 정의: 먼저 해결해야 하는 문제를 정확하게 정의한다.
- 알고리즘 선택: 해당 문제를 해결하는 데 사용할 수 있는 여러 알고리즘을 고려한다.
- 효율성 분석: 각 알고리즘의 시간 복잡도나 위에서 언급한 객관적인 측정 방법을 사용하여 효율성을 분석한다.
- 데이터 크기 고려: 일반적으로 알고리즘의 효율성은 데이터 크기에 따라 달라질 수 있습니다. 따라서 해당 문제에서 예상되는 데이터 크기를 고려하여 비교해야 한다.
- 최적 알고리즘 선택: 분석 결과를 바탕으로 가장 효율적인 알고리즘을 선택
Big O natation
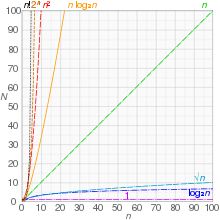
- 시간 복잡도
시간 복잡도는 알고리즘을 실행하는 데 걸리는 시간이 입력 크기에 따라 어떻게 변하는지를 나타내는 척도이다. 쉽게 말하면, 문제의 크기가 커질 때 알고리즘의 실행 속도가 얼마나 느려지는지를 예측하는 방법이다. 시간 복잡도는 알고리즘의 효율성을 평가하는 데 중요한 역할을 하기에 알고리즘 설계시 필수적으로 고려해야한다.
시간 복잡도를 측정하는 방법 : 시간 복잡도는 일반적으로 빅오 표기법을 사용하여 표현된다. 빅오 표기법은 자료구조 페이지를 참고하자.
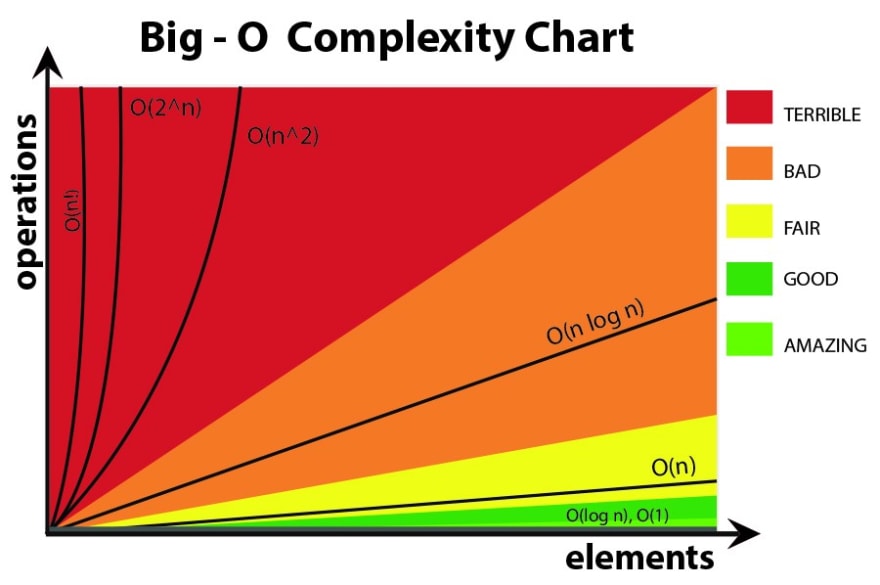
시간복잡도 그래프
- O(1) 상수 시간 : 입력 크기에 관계없이 일정한 시간 안에 실행
- O(log n) 로그 시간 : 입력 크기가 n배 증가할 때마다 실행 시간이 log n배 증가
- O(n) 선형 시간 : 입력 크기가 n배 증가할 때마다 실행 시간이 n배 증가
- O(n log n) 선형 로그 시간 : 입력 크기가 n배 증가할 때마다 실행 시간이 n log n배 증가
- O(n^2) 제곱 시간 : 입력 크기가 n배 증가할 때마다 실행 시간이 n^2배 증가
- O(2^n) 지수 시간 : 입력 크기가 n배 증가할 때마다 실행 시간이 2^n배 증가.
'Computer Scinece > Programming Principles' 카테고리의 다른 글
| Programming Principles [6] : 최적화 알고리즘 (Optimization Algorithms) (1) | 2024.09.18 |
|---|---|
| Programming Principles [5] : 재귀 알고리즘 (Recursive Algorithm) (0) | 2024.09.18 |
| Programming Principles [4] : 자료 구조 (Data Structures) (정리 중) (0) | 2024.09.18 |
| Programming Principles [2] : 객체지향 프로그래밍 (Object-Oriented Programming) (1) | 2024.09.18 |
| Programming Principles[1] : 프로그래밍 기본 (Basic Algorithms) (0) | 2024.09.18 |