

기존의 절차지향 프로그래밍은 데이터와 함수가 분리되어 있어 프로그램의 구조가 복잡해지고 유지보수가 어려워지는 단점이 있었다. 이러한 문제를 해결하기 위해 객체지향 프로그래밍(OOP)이 등장하였으며, 이는 객체를 중심으로 소프트웨어를 구성하는 방법이다. OOP는 데이터를 포함한 객체를 통해 관련된 기능을 묶어 관리함으로써 코드의 재사용성과 모듈화를 촉진하고, 프로그램의 이해도를 높인다. Unity를 예를 들면, Player라는 클래스를 정의하고 이 클래스에 체력이나 점수같은 멤버 변수들을 포함시키고 TakeDamage()와 IncreaseScore()와 같은 멤버 함수를 통해 플레이어의 상태와 행동을 관리할 수 있다. 이러한 방식으로 각 객체는 자신만의 속성과 기능을 가지게 되어, 복잡한 게임 시스템을 보다 효율적으로 설계하고 유지보수할 수 있게 한다. 이처럼 객체지향 프로그래밍은 현대 소프트웨어 개발에서 필수적인 접근 방식으로 자리잡고 있다.
1. 객체 지향
객체지향 프로그래밍(OOP)은 우리가 사는 실제 세계가 객체들로 구성되어 있는 것처럼 소프트웨어도 객체로 구성하는 방법이다. 객체는 고유한 기능을 수행하며 다른 객체들과 상호작용한다. 기존의 절차지향 프로그래밍은 데이터와 함수가 분리되어 있어 안정성이 떨어지고 이해하기 어렵다는 단점이 있다. 이러한 문제를 해결하기 위해 서로 관련된 함수와 데이터를 묶어서 생각해야 할 필요성이 대두되었고, 이로 인해 객체지향 개념이 등장했다. 객체는 변수와 함수의 집합으로 구성되며 멤버 변수는 객체의 상태를 저장하는 변수이다. 반면 멤버 함수는 객체 안에서 정의된 함수로 일반 함수와 구별하기 위해 이렇게 명명된다. 이를 통해 객체는 자신만의 데이터와 기능을 갖추어 프로그램을 보다 체계적으로 구성할 수 있다.
클래스(Class)는 특정 종류의 모든 객체가 공통적으로 가지는 멤버 변수와 멤버 함수를 정의하는 설계 틀이다. 예를 들어, class Circle { public: int radius; // 멤버 변수 int calcArea() { return radius; } // 멤버 함수 };와 같이 정의할 수 있는데 같은 클래스로 생성된 객체들은 각기 다른 메모리 공간이 할당되며, 따라서 멤버 변수의 값은 객체마다 다를 수 있다. 그러나 멤버 함수는 같은 클래스에 속하는 객체 간에 동일하게 정의되므로 모든 객체가 동일한 동작을 수행합니다. 이러한 클래스로부터 만들어지는 객체를 인스턴스(Instance)라고 하며, 인스턴스는 자료형 이름과 객체의 이름을 조합하여 생성한다.
class Circle {
public:
int radius; // 멤버 변수
// 멤버 함수: 원의 면적을 계산
int calcArea() {
return 3.14 * radius * radius; // 면적 계산
}
};
객체 내부에 정의된 멤버 변수와 함수를 사용하려면 도트(.) 연산자를 이용해야 한다. 멤버 함수는 일반 함수와 마찬가지로 중복 정의가 가능하며, 기본값을 지정하는 디폴트 매개변수 기법을 사용할 수 있다. 이를 통해 객체지향 프로그래밍의 유연성과 재사용성을 높일 수 있다.
2. 인터페이스
멤버 함수의 길이가 너무 길어지면 가독성이 떨어져 유지보수가 어려워지기 때문에, 클래스 외부에 멤버 함수를 정의하는 것이 좋다. 이를 위해 클래스 안에서는 함수들의 원형만 정의하고, 실제 구현은 클래스 외부에서 수행한다. 예를 들어, class Circle { public: double calcArea(); };와 같이 클래스에서 함수 원형을 정의하고, double Circle::calcArea() { return 3.14 * radius * radius; }와 같이 클래스 외부에서 멤버 함수를 구현할 수 있다. 이 방식은 클래스 선언과 정의를 분리하여 코드의 구조를 명확하게 하고, 헤더 파일(.h)과 소스 파일(.cpp)로 나누어 작성할 수 있어 관리가 용이하다.
#ifndef CIRCLE_H
#define CIRCLE_H
class Circle {
public:
Circle(double r); // 생성자
double calcArea(); // 멤버 함수 원형
private:
double radius; // 멤버 변수
};
#endif // CIRCLE_H#include "Circle.h"
#include <cmath>
// 생성자 구현
Circle::Circle(double r) : radius(r) {}
// 멤버 함수 calcArea()의 구현
double Circle::calcArea() {
return M_PI * radius * radius; // 원주율을 사용하여 면적 계산
}
또한, 인터페이스(Interface)는 소멸자와 순수 가상 함수만 선언된 클래스로 구성되어 있으며, 이를 통해 미리 정해진 규칙을 만들어 표준화하여 구현할 수 있는 기반을 제공한다. 이러한 접근은 코드의 일관성을 높이고, 다른 개발자와의 협업을 원활하게 해준다.
// Character.h
class Character {
public:
virtual ~Character() {} // 소멸자
virtual void attack() = 0; // 순수 가상 함수
virtual void defend() = 0; // 순수 가상 함수
};
// Warrior.h
#include "Character.h"
class Warrior : public Character {
public:
void attack() override {
cout << "Warrior attacks with a sword!" << endl;
}
void defend() override {
cout << "Warrior defends with a shield!" << endl;
}
};
// Mage.h
#include "Character.h"
class Mage : public Character {
public:
void attack() override {
cout << "Mage casts a fireball!" << endl;
}
void defend() override {
cout << "Mage conjures a magical barrier!" << endl;
}
};
// main.cpp
#include "Warrior.h"
#include "Mage.h"
int main() {
Character* warrior = new Warrior();
Character* mage = new Mage();
warrior->attack(); // "Warrior attacks with a sword!"
mage->attack(); // "Mage casts a fireball!"
delete warrior;
delete mage;
return 0;
}
캡슐화(Encapsulation)는 관련된 데이터와 알고리즘을 하나의 단위인 객체로 묶어 관리하는 것을 의미한다. 캡슐화의 첫 번째 목적은 서로 관련된 데이터와 알고리즘을 함께 포장하여 코드의 구조를 명확히 하고, 두 번째 목적은 객체 내부의 상태를 보호하기 위해 외부에서 직접 접근하지 못하도록 하는 것입니다. 이를 통해 정보 은닉(Information Hiding)을 구현하게 되며, 다른 객체는 내부 데이터를 직접 조작하는 대신 제공된 함수 호출을 통해 상호작용하게 된다. 이러한 방식은 코드의 안정성과 유지보수성을 높이고, 객체 간의 의존성을 줄여 시스템의 전반적인 유연성을 향상시키는 데 기여한다.
#ifndef BANKACCOUNT_H
#define BANKACCOUNT_H
class BankAccount {
public:
BankAccount(double initialBalance); // 생성자
void deposit(double amount); // 입금 함수
void withdraw(double amount); // 출금 함수
double getBalance() const; // 잔고 조회 함수
private:
double balance; // 계좌 잔고 (비공개)
};
#endif // BANKACCOUNT_H#include "BankAccount.h"
// 생성자 구현
BankAccount::BankAccount(double initialBalance) : balance(initialBalance) {}
// 입금 함수 구현
void BankAccount::deposit(double amount) {
if (amount > 0) {
balance += amount; // 잔고에 금액 추가
}
}
// 출금 함수 구현
void BankAccount::withdraw(double amount) {
if (amount > 0 && amount <= balance) {
balance -= amount; // 잔고에서 금액 차감
}
}
// 잔고 조회 함수 구현
double BankAccount::getBalance() const {
return balance; // 현재 잔고 반환
}

상속(Inheritance)은 객체 지향 프로그래밍의 핵심 개념으로, 이미 작성된 부모 클래스를 기반으로 새로운 자식 클래스를 생성하는 기법이다. 이를 통해 자식 클래스는 부모 클래스의 속성과 기능을 상속받아 코드의 재사용성을 높이고, 계층 구조를 형성하여 유사한 객체들을 그룹화할 수 있다. 다형성(Polymorphism)은 객체가 상황에 따라 다양한 형태로 동작할 수 있는 능력을 의미하며, 이는 같은 인터페이스를 통해 서로 다른 클래스의 객체들이 각기 다른 방식으로 동작하도록 할 수 있다. 이 두 개념은 함께 사용되어 코드의 유연성과 확장성을 높이며, 프로그램의 유지보수를 용이하게 한다. 예를 들어, 다양한 동물 클래스가 있을 때, 모든 동물 클래스가 speak()라는 메서드를 가지고 있지만, 각 동물 클래스는 이 메서드를 통해 서로 다른 소리를 낼 수 있다.
#include <iostream>
#include <string>
// 부모 클래스
class Animal {
public:
// 가상 함수 (Polymorphism을 위한)
virtual void speak() {
std::cout << "Animal makes a sound" << std::endl;
}
};
// 자식 클래스: Dog
class Dog : public Animal {
public:
void speak() override { // 부모 클래스의 speak() 함수 오버라이드
std::cout << "Dog barks" << std::endl;
}
};
// 자식 클래스: Cat
class Cat : public Animal {
public:
void speak() override { // 부모 클래스의 speak() 함수 오버라이드
std::cout << "Cat meows" << std::endl;
}
};
int main() {
Animal* animal1 = new Dog(); // Animal 포인터로 Dog 객체 생성
Animal* animal2 = new Cat(); // Animal 포인터로 Cat 객체 생성
animal1->speak(); // "Dog barks" 출력
animal2->speak(); // "Cat meows" 출력
// 메모리 해제
delete animal1;
delete animal2;
return 0;
}
3. 생성자와 소멸자, 접근자와 설정자, 객체와 함수
생성자(Constructor)는 객체가 생성될 때 자동으로 호출되어 멤버 변수를 초기화하고 객체의 동작에 필요한 메모리 공간이나 기타 자원을 할당하는 특수한 함수이다. 생성자는 반환 타입이 없으며 클래스 이름과 동일한 이름을 가지고 여러 개의 생성자를 중복 정의할 수 있어 객체 초기화의 편리성을 제공한다. 반면, 소멸자(Destructor)는 객체가 소멸될 때 호출되어 프로그램 종료 전에 자원을 반납하는 역할을 한다. 접근 제어는 클래스 외부에서 특정 멤버 변수나 멤버 함수에 접근하는 것을 제한하는 것으로 private은 클래스 내부에서만 접근할 수 있도록 하여 정보 은닉을 지원하고 public은 모든 객체에서 접근할 수 있게 한다. 이를 통해 실수로 잘못된 값이 변수에 할당되는 것을 방지하고, 멤버 변수에 대한 안전한 접근을 보장하기 위해 접근 제어를 활용해야 한다.
#include <iostream>
#include <string>
class Student {
private:
std::string name; // private 멤버 변수
int age; // private 멤버 변수
public:
// 생성자
Student(std::string n, int a) : name(n), age(a) {
std::cout << "Student object created: " << name << ", Age: " << age << std::endl;
}
// 소멸자
~Student() {
std::cout << "Student object destroyed: " << name << std::endl;
}
// public 멤버 함수: 정보를 출력
void displayInfo() {
std::cout << "Name: " << name << ", Age: " << age << std::endl;
}
// public 멤버 함수: 나이 변경
void setAge(int a) {
if (a >= 0) { // 나이가 음수가 아닌 경우에만 변경
age = a;
} else {
std::cout << "Age cannot be negative!" << std::endl;
}
}
};
int main() {
Student student1("Alice", 20); // 객체 생성
student1.displayInfo(); // 정보 출력
student1.setAge(22); // 나이 변경
student1.displayInfo(); // 변경된 정보 출력
return 0; // main 함수 종료 시 student1 객체 소멸
}설정자(setter)와 접근자(getter)는 객체의 정보 은닉을 유지하면서 멤버 변수에 안전하게 접근하고 변경할 수 있도록 돕는 중요한 함수이다. 설정자는 외부에서 멤버 변수를 변경할 수 있게 해주는 함수로 잘못된 값이 들어가는 것을 방지하는 유효성 검사를 포함할 수 있다. 반면 접근자는 private로 선언된 멤버 변수를 외부로 읽어 전달해주는 함수이다. 이 두 가지를 사용하면 객체의 내부 상태를 안전하게 관리할 수 있다. 객체의 참조자가 함수의 매개변수로 전달될 때 해당 객체의 생성자와 소멸자는 호출되지 않으며 이는 같은 객체를 가리키기 때문이다. 이는 "call by reference"와 동일한 원리로 작용하여 메모리 효율성을 높이고 성능을 향상시킨다.
#include <iostream>
using namespace std;
class Person {
private:
string name; // private 멤버 변수
int age; // private 멤버 변수
public:
// 접근자 (getter)
string getName() const {
return name;
}
int getAge() const {
return age;
}
// 설정자 (setter)
void setName(const string& newName) {
name = newName; // 안전하게 name 변경
}
void setAge(int newAge) {
if (newAge >= 0) { // 유효성 검사
age = newAge; // 안전하게 age 변경
} else {
cout << "나이는 음수가 될 수 없습니다." << endl;
}
}
};
int main() {
Person person; // Person 객체 생성
// 설정자 사용
person.setName("홍길동");
person.setAge(30);
// 접근자 사용
cout << "이름: " << person.getName() << endl; // 이름: 홍길동
cout << "나이: " << person.getAge() << endl; // 나이: 30
return 0;
}
객체 배열은 객체들을 요소로 갖는 배열로, 객체들이 모여 있는 컨테이너 역할을 합니다. 이 배열을 생성할 때, 각 배열 요소는 해당 클래스의 기본 생성자를 호출하여 초기화됩니다. 만약 기본 생성자가 정의되어 있지 않다면, 객체 배열을 생성하는 과정에서 오류가 발생합니다. 따라서 객체 배열을 초기화하려면 각 요소별로 생성자를 호출해야 하며, 이를 통해 각 객체의 상태를 설정하고 배열을 효과적으로 사용할 수 있습니다.
#include <iostream>
using namespace std;
class Circle {
public:
double radius;
Circle(double r) : radius(r) {} // 생성자
double calcArea() {
return 3.14 * radius * radius; // 면적 계산
}
};
int main() {
const int size = 3; // 배열 크기
Circle circles[size] = {Circle(1.0), Circle(2.0), Circle(3.0)}; // 객체 배열 초기화
for (int i = 0; i < size; i++) {
cout << "Circle " << i + 1 << " Area: " << circles[i].calcArea() <<
- 벡터는 크기를 동적으로 변경할 수 있는 배열로, 컴파일 시간에 배열의 크기를 미리 결정할 필요가 없어 가변적인 데이터 처리에 유용합니다. 임의의 위치에 있는 요소에 빠르게 접근할 수 있지만, 요소를 중간에 삽입하거나 삭제할 경우 뒤의 요소들을 이동해야 하므로 시간이 소요됩니다. 또한, 벡터의 크기가 증가할 때마다 새로운 메모리 영역을 찾아 벡터를 이동해야 하기 때문에 비효율적일 수 있습니다. 따라서 크기를 미리 예측할 수 있다면 고정된 크기의 배열을 사용하는 것이 더 나을 수 있습니다. 벡터의 요소 위치는 반복자를 사용하여 표시하며, 반복자는 일반화된 포인터로 생각할 수 있습니다. STL 알고리즘을 사용할 때는 반드시 반복자를 통해 접근해야 하며, 벡터는 다양한 연산자들이 중복 정의되어 있어 다른 벡터와의 복사 및 비교를 쉽게 할 수 있습니다. 그러나 벡터는 생성과 소멸 시 시간이 소요되므로, 동적 크기 변경 기능은 없지만 성능 저하 없이 벡터의 장점을 제공하는 std::array 클래스를 사용할 수도 있습니다.
#include <iostream>
#include <vector>
using namespace std;
class Circle {
public:
double radius;
Circle(double r) : radius(r) {} // 생성자
double calcArea() {
return 3.14 * radius * radius; // 면적 계산
}
};
int main() {
vector<Circle> circles; // Circle 객체를 저장할 벡터
// 벡터에 Circle 객체 추가
circles.push_back(Circle(1.0));
circles.push_back(Circle(2.0));
circles.push_back(Circle(3.0));
for (size_t i = 0; i < circles.size(); i++) {
cout << "Circle " << i + 1 << " Area: " << circles[i].calcArea() << endl; // 면적 출력
}
return 0;
}
4. 포인터와 동적 객체 생성

동적 메모리 할당에서는 변수 생성 시 메모리 주소를 참조해야 하므로 포인터가 필요합니다. 포인터는 메모리 주소를 저장하는 변수로, 초기화되지 않은 상태에서는 임의의 주소를 가리킬 수 있어 주의가 필요합니다. 주소 연산자 &를 사용하여 변수의 주소를 얻을 수 있고, 간접 참조 연산자 *를 통해 포인터가 가리키는 메모리 공간의 값을 읽거나 변경할 수 있습니다. 예를 들어, int *p; *p = 100;과 같은 코드는 위험한 코드로, 포인터 p가 초기화되지 않았기 때문에 임의의 주소를 가리킬 수 있습니다. 이를 방지하기 위해 int* p = nullptr;로 초기화하는 것이 바람직합니다. nullptr는 널 포인터를 의미하며, 포인터의 타입은 변수의 타입과 일치해야 합니다.

동적 메모리 할당은 프로그램 실행 중 필요한 만큼 메모리를 할당받는 과정을 의미합니다. 이때 컴퓨터는 아직 사용되지 않은 메모리 공간인 힙을 관리하여, 사용자가 요청한 메모리 크기만큼을 할당합니다. 이를 위해 라이브러리 함수를 호출하여 운영체제에 메모리 요청을 하며, 할당된 메모리를 사용하여 작업을 수행합니다. 작업이 끝난 후에는 반드시 메모리를 운영체제에 반납해야 하며, 이를 소홀히 할 경우 다른 프로그램이 동적 메모리를 사용할 수 없게 되는 문제가 발생합니다. 동적 메모리는 포인터를 통해서만 접근할 수 있기 때문에, 포인터가 자주 사용되는 주요 이유 중 하나입니다.
#include <iostream>
int main() {
// 동적 메모리 할당
int* p = new int; // 정수를 위한 메모리 할당
*p = 42; // 할당된 메모리에 값 대입
std::cout << "동적 할당된 메모리의 값: " << *p << std::endl;
// 메모리 해제
delete p; // 동적 메모리 해제
// 동적 배열 예시
int size = 5;
int* arr = new int[size]; // 정수형 배열 동적 할당
// 배열 초기화
for (int i = 0; i < size; ++i) {
arr[i] = i + 1; // 1부터 5까지의 값으로 초기화
}
// 배열 출력
std::cout << "동적 할당된 배열의 값: ";
for (int i = 0; i < size; ++i) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
// 배열 메모리 해제
delete[] arr; // 동적 배열 메모리 해제
return 0;
}
n 동적 메모리 할당은 프로그램 실행 중에 메모리 크기를 동적으로 결정할 수 있게 해주는 기법으로, new 연산자를 사용하여 힙(heap) 영역에서 메모리를 할당받습니다. 정적 배열과 달리 동적 배열은 크기 변경이 가능하며, 요청한 메모리가 부족할 경우 bad_alloc 오류가 발생할 수 있습니다. 따라서 동적 메모리를 사용한 후에는 반드시 해제를 해야 하며, delete 또는 delete[] 키워드를 사용하여 메모리를 반납해야 합니다. 예를 들어, int* p = new int[10];로 10개의 정수를 저장할 수 있는 동적 배열을 생성한 경우, 메모리 해제를 위해서는 delete[] p;를 사용해야 합니다
스마트 포인터는 일반 포인터의 사용으로 발생할 수 있는 문제를 줄이기 위해 고안된 도구로, 메모리 관리의 효율성을 높이고 메모리 누수를 방지하는 데 도움을 줍니다. unique_ptr는 기본 포인터를 감싸는 객체로, 해당 객체의 소멸자가 호출될 때 자동으로 포인터가 가리키는 메모리 공간도 해제합니다. 이러한 방식으로 메모리 관리를 자동화하여 개발자는 메모리 해제를 명시적으로 수행할 필요가 없으며, 실행 시간의 오버헤드가 없기 때문에 성능 관점에서도 효율적입니다. 예를 들어, unique_ptr<int> p(new int);와 같이 동적 메모리를 할당하고, unique_ptr<int[]> buf(new int[10]);를 사용하여 배열을 동적으로 할당할 수 있습니다. 이 경우, p와 buf가 삭제될 때 해당 메모리도 자동으로 해제되어 메모리 누수가 발생하지 않습니다.
#include <iostream>
#include <memory> // 스마트 포인터를 사용하기 위한 헤더 파일
int main() {
// unique_ptr을 사용하여 정수 동적 할당
std::unique_ptr<int> p(new int(42)); // 포인터 p는 42를 가리킴
std::cout << "p가 가리키는 값: " << *p << std::endl;
// unique_ptr을 사용하여 정수 배열 동적 할당
std::unique_ptr<int[]> buf(new int[10]); // 크기가 10인 정수 배열
for (int i = 0; i < 10; ++i) {
buf[i] = i * 5; // 배열 초기화
}
// 배열 값 출력
std::cout << "buf 배열의 값: ";
for (int i = 0; i < 10; ++i) {
std::cout << buf[i] << " "; // 0, 5, 10, ..., 45
}
std::cout << std::endl;
// p와 buf가 범위를 벗어날 때 자동으로 메모리 해제됨
return 0; // 프로그램 종료
}
객체는 동적으로 생성할 수 있으며, 이는 객체 지향 프로그래밍에서 종종 필요한 경우입니다. 예를 들어, 객체의 개수를 미리 알 수 없는 상황에서는 동적 생성이 유리합니다. 포인터를 사용하여 동적으로 생성된 객체에 접근할 때, (*pDog).getAge();와 같이 포인터를 역참조하여 접근할 수 있지만, 이는 번거롭기 때문에 pDog->getAge();와 같이 화살표 연산자를 사용하는 것이 더 간편합니다. 포인터를 멤버 변수로 가진 클래스에서는 생성자에서 동적 메모리를 할당하고 기본값으로 설정한 후, 소멸자에서 해당 메모리를 해제해야 합니다. 더 이상 사용되지 않는 포인터는 nullptr로 설정할 필요가 없으며, 멤버 변수가 포인터인 경우 반드시 소멸자를 작성해야 합니다. 디폴트 소멸자는 객체를 소멸시키지만, 힙에서 동적으로 할당된 메모리는 여전히 남아 있기 때문에 소멸자에서 이를 명시적으로 해제해야 합니다.
또한, this 포인터는 함수가 실행되는 객체의 주소값을 가지고 있으며, 인스턴스가 생성될 때 활성화됩니다. this 포인터는 포인터지만, 생성하거나 소멸할 필요가 없으며 컴파일러가 자동으로 처리합니다. this 포인터를 통해 멤버에 접근하는 것은 매개변수와 멤버 변수를 구분하고 가독성을 높이기 위해 권장됩니다. 마지막으로, const 포인터는 별표 기호를 기준으로 왼쪽에 위치할 경우 객체가 변경되지 않음을 의미하며, 오른쪽에 위치할 경우 포인터 자체가 변경되지 않음을 나타냅니다. 멤버 함수를 const로 정의하면 해당 함수 안에서 멤버 변수를 변경하는 것이 금지됩니다.
#include <iostream>
class Dog {
private:
int* age; // 나이를 저장할 포인터
public:
// 생성자: 동적 메모리 할당 및 초기화
Dog(int a) {
age = new int; // 동적 메모리 할당
*age = a; // 초기값 설정
}
// 멤버 함수: 개의 나이를 반환
int getAge() const {
return *age; // 포인터를 통해 나이 반환
}
// 소멸자: 동적 메모리 해제
~Dog() {
delete age; // 동적 할당된 메모리 해제
}
// this 포인터 사용 예시
void printAge() const {
std::cout << "개 나이: " << this->getAge() << std::endl; // this 포인터를 통해 접근
}
};
int main() {
// Dog 객체를 동적으로 생성
Dog* pDog = new Dog(5); // 나이를 5로 설정
// 객체의 멤버 함수 호출
pDog->printAge();
// 동적 할당된 객체 메모리 해제
delete pDog;
return 0; // 프로그램 종료
}
5. 복사생성자와 정적 멤버
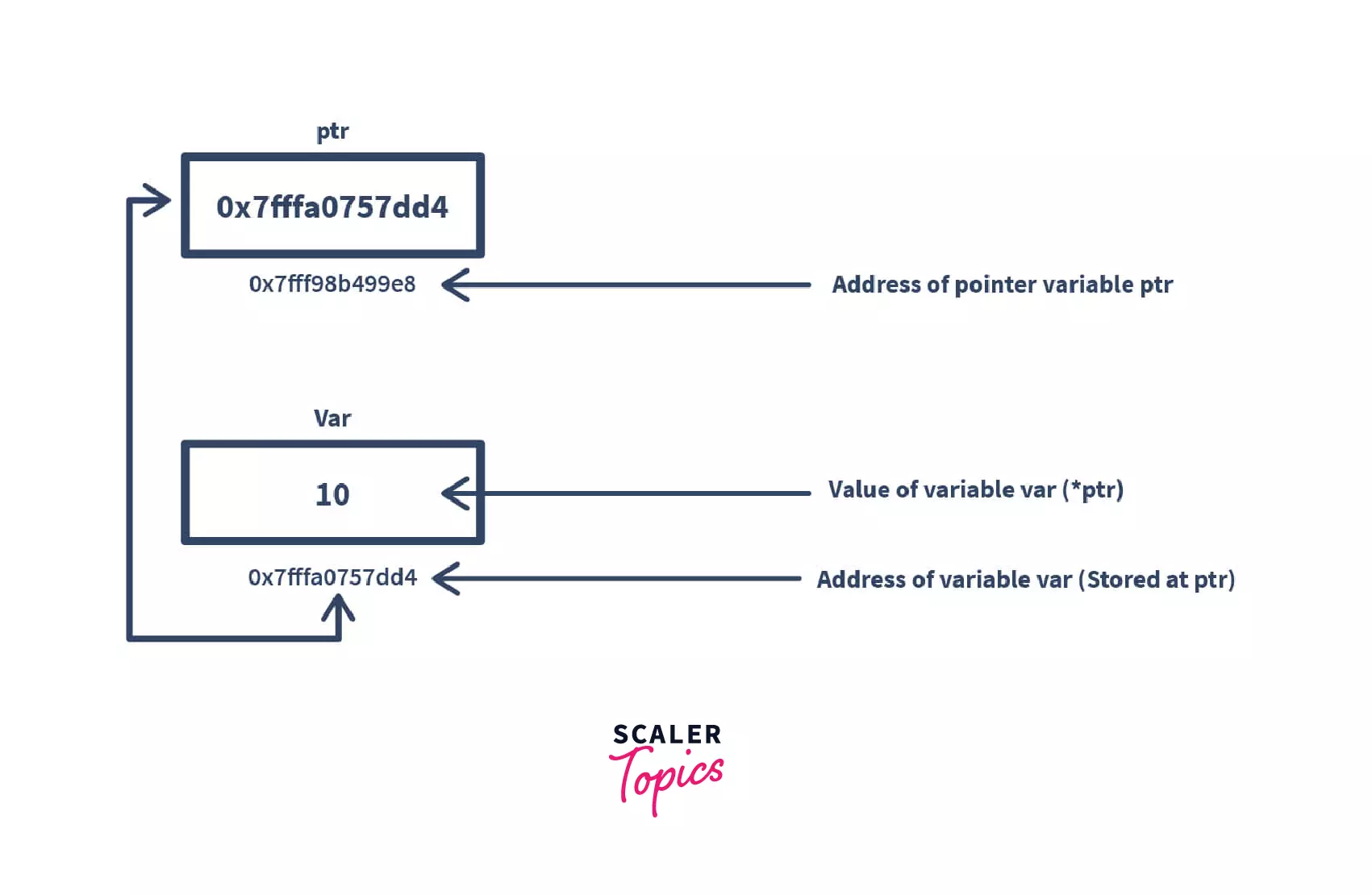
값에 의한 호출(call by value)에서는 인수의 값이 매개변수로 복사되어 새로운 객체가 생성되며, 이 과정에서 복사 생성자가 호출됩니다. 반면, 참조에 의한 호출(call by reference)에서는 변수의 주소 또는 참조자를 함수로 전달하여 원본 객체를 직접 사용합니다. 이 경우, & 연산자를 사용해 참조 매개변수를 정의하면 객체가 아닌 주소값이 전달되므로 생성자나 소멸자가 호출되지 않고, 객체를 복사하지 않아 시간 소모가 줄어듭니다. 따라서, 참조 매개변수를 사용하면 원본 객체를 효율적으로 전달할 수 있습니다.
#include <iostream>
class Sample {
private:
int value;
public:
// 기본 생성자
Sample(int v) : value(v) {}
// 복사 생성자
Sample(const Sample& other) : value(other.value) {
std::cout << "복사 생성자 호출\n";
}
// 값에 의한 호출
void callByValue(Sample obj) {
std::cout << "callByValue: " << obj.value << std::endl;
}
// 참조에 의한 호출
void callByReference(Sample& obj) {
std::cout << "callByReference: " << obj.value << std::endl;
}
};
int main() {
Sample sample1(10);
// 값에 의한 호출
sample1.callByValue(sample1); // 복사 생성자 호출
// 참조에 의한 호출
sample1.callByReference(sample1); // 복사 생성자 호출되지 않음
return 0;
}
정적 변수(static variable)는 static 키워드를 사용하여 선언되며, 클래스마다 하나의 인스턴스만 생성됩니다. 즉, 모든 객체가 동일한 정적 변수를 공유하게 되어, 클래스의 인스턴스가 생성될 때마다 정적 변수가 증가하는 방식으로 특정 정보를 추적할 수 있습니다. 예를 들어, 카운터 변수를 정적 변수로 선언하고 생성자에서 증가시키면 현재까지 생성된 객체의 수를 파악할 수 있습니다. 정적 변수의 초기화는 반드시 클래스 외부에서 수행해야 하며, 이는 정적 변수가 객체의 멤버가 아니라 전역 변수처럼 작동하기 때문입니다.
#include <iostream>
class Circle {
private:
static int count; // 정적 변수 선언
double radius;
public:
// 생성자
Circle(double r) : radius(r) {
count++; // 객체가 생성될 때마다 카운트 증가
}
// 정적 함수: 현재 생성된 Circle 객체의 개수를 반환
static int getCount() {
return count;
}
};
// 정적 변수 초기화
int Circle::count = 0;
int main() {
Circle c1(5.0);
Circle c2(10.0);
Circle c3(15.0);
std::cout << "생성된 Circle 객체의 수: " << Circle::getCount() << std::endl; // 3
return 0;
}
7. 연산자 중복 정의와 프렌드 함수
연산자 중복(Operator overloading)은 개발자가 특정 연산자의 의미를 객체에 대해 재정의할 수 있는 기능을 말합니다. 이를 통해 기본 데이터 타입뿐만 아니라 사용자 정의 데이터 타입에 대해서도 연산자를 사용할 수 있게 됩니다. 중복된 연산자는 특수한 이름을 가진 함수로, operator 키워드에 연산자 기호를 붙여서 정의됩니다. 이렇게 함으로써 객체 간의 연산을 자연스럽게 표현할 수 있으며, 코드의 가독성을 향상시킬 수 있습니다.
#include <iostream>
class Point {
public:
int x, y;
// 생성자
Point(int xCoord, int yCoord) : x(xCoord), y(yCoord) {}
// 연산자 중복: + 연산자를 오버로드
Point operator+(const Point& other) {
return Point(x + other.x, y + other.y);
}
// 연산자 중복: << 연산자를 오버로드 (출력용)
friend std::ostream& operator<<(std::ostream& os, const Point& point) {
os << "(" << point.x << ", " << point.y << ")";
return os;
}
};
int main() {
Point p1(2, 3);
Point p2(4, 5);
Point p3 = p1 + p2; // + 연산자 사용
std::cout << "p1: " << p1 << std::endl;
std::cout << "p2: " << p2 << std::endl;
std::cout << "p3 (p1 + p2): " << p3 << std::endl;
return 0;
}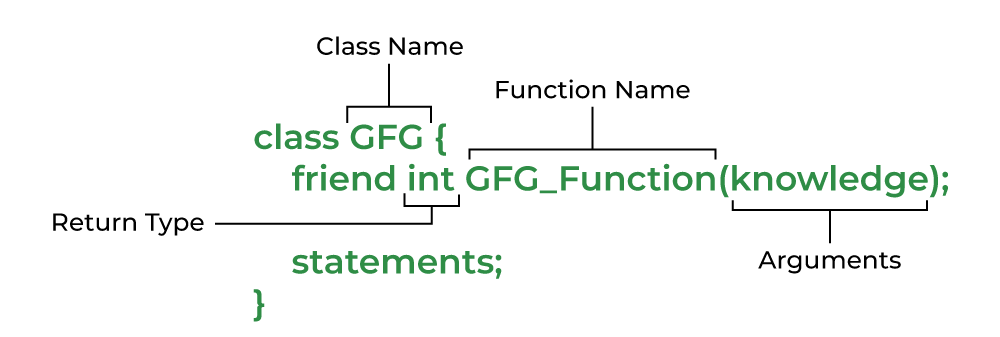
프렌드 함수(friend function)는 C++에서 외부 클래스나 함수가 특정 클래스의 내부 데이터를 사용할 수 있도록 허가하는 메커니즘입니다. 프렌드 함수는 해당 클래스의 멤버가 아니기 때문에 private나 public 접근 제어자의 영향을 받지 않습니다. 따라서 클래스 내부의 멤버에 직접 접근할 수 있으며, 보통 두 개의 객체를 비교하거나 조작할 때 많이 사용됩니다. 프렌드 함수를 사용하지 않으면 복잡한 멤버 함수 형태로 코드를 작성해야 하므로, 코드의 가독성과 이해가 어려워질 수 있습니다.
#include <iostream>
class Box {
private:
double width;
public:
Box(double w) : width(w) {}
// 프렌드 함수 선언
friend bool operator<(const Box& b1, const Box& b2);
};
// 프렌드 함수 정의
bool operator<(const Box& b1, const Box& b2) {
return b1.width < b2.width; // 두 박스의 넓이를 비교
}
int main() {
Box box1(10.0);
Box box2(20.0);
if (box1 < box2) { // 프렌드 함수 사용
std::cout << "box1 is smaller than box2." << std::endl;
} else {
std::cout << "box1 is not smaller than box2." << std::endl;
}
return 0;
}
8. 상속

상속(Inheritance)은 기존에 존재하는 클래스로부터 속성과 동작을 이어받아 자신이 필요한 기능을 추가하는 기법입니다. 여러 클래스에 공통적인 특징이 있는 경우, 이를 새로운 클래스로 정의하고 상속받음으로써 코드의 중복을 줄일 수 있습니다. 자식 클래스의 생성자에서 가장 먼저 수행되는 작업은 부모 클래스의 생성자를 호출하는 것이며, 소멸자는 역순으로 호출됩니다. 상속은 is-a 관계를 나타내며, 만약 has-a 관계를 나타내고자 한다면, 하나의 클래스 안에 다른 클래스의 객체를 포함시켜야 합니다. 자식 클래스의 생성자 헤더 뒤에 콜론(:)을 추가하여 원하는 부모 클래스의 생성자를 지정할 수 있습니다.
#include <iostream>
// 부모 클래스
class Animal {
public:
Animal() {
std::cout << "Animal constructor called." << std::endl;
}
void speak() {
std::cout << "Animal speaks." << std::endl;
}
~Animal() {
std::cout << "Animal destructor called." << std::endl;
}
};
// 자식 클래스
class Dog : public Animal {
public:
Dog() : Animal() { // 부모 클래스 생성자 호출
std::cout << "Dog constructor called." << std::endl;
}
void bark() {
std::cout << "Dog barks." << std::endl;
}
~Dog() {
std::cout << "Dog destructor called." << std::endl;
}
};
int main() {
Dog myDog; // Dog 객체 생성
myDog.speak(); // 부모 클래스의 메서드 호출
myDog.bark(); // 자식 클래스의 메서드 호출
return 0; // 메인 함수 종료
}
오버라이딩(Overriding): 자식클래스가 필요에 따라 상속된 멤버 함수를 재정의하여 사용하는 것을 의미
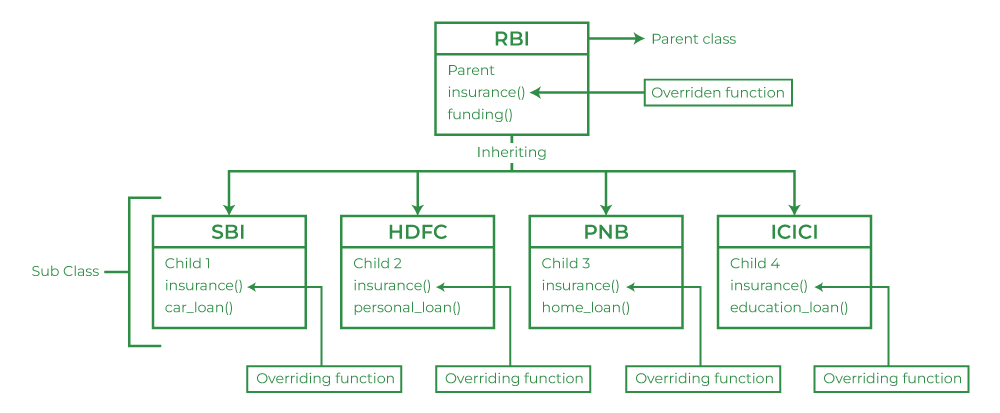
오버라이딩(Overriding)은 자식 클래스가 필요에 따라 상속된 멤버 함수를 재정의하여 사용하는 것을 의미합니다. 이를 위해서는 멤버 함수의 선언부는 부모 클래스의 것과 동일해야 하며, 구현부만 자식 클래스에 맞게 변경합니다. 즉, 멤버 함수의 이름, 반환형, 매개변수의 개수와 자료형이 일치해야 합니다. 오버라이딩은 상속받은 멤버 함수를 다시 정의하는 것이며, 오버로딩은 같은 이름의 멤버 함수를 여러 개 정의하는 것입니다. 보통 자식 클래스에서는 부모의 멤버 함수를 완전히 대치하는 경우보다 내용을 추가하는 경우가 많습니다.
#include <iostream>
// 부모 클래스
class Animal {
public:
virtual void speak() { // 가상 함수로 선언
std::cout << "Animal speaks." << std::endl;
}
};
// 자식 클래스
class Dog : public Animal {
public:
void speak() override { // 부모 클래스의 speak() 함수 재정의
std::cout << "Dog barks." << std::endl;
}
};
int main() {
Animal* animal = new Animal();
Animal* dog = new Dog(); // Animal 포인터로 Dog 객체 생성
animal->speak(); // Animal speaks.
dog->speak(); // Dog barks. (오버라이딩된 메서드 호출)
delete animal;
delete dog; // 메모리 해제
return 0;
}다중 상속(multiple inheritance)은 하나의 자식 클래스가 두 개 이상의 부모 클래스로부터 멤버를 상속받는 기법입니다. 이 경우 부모 클래스들에 동일한 이름의 멤버 변수가 존재할 수 있으며, 이로 인해 이름 충돌이 발생할 수 있습니다. 이러한 충돌을 해결하기 위해 자식 클래스에서는 부모 클래스의 접근 지정자를 사용하여 각 부모 클래스의 멤버를 명확히 구분할 수 있습니다. 이를 통해 동일한 이름의 멤버에 접근할 때 혼란을 줄일 수 있습니다.
#include <iostream>
// 부모 클래스 1
class Father {
public:
void show() {
std::cout << "Father's show()" << std::endl;
}
};
// 부모 클래스 2
class Mother {
public:
void show() {
std::cout << "Mother's show()" << std::endl;
}
};
// 자식 클래스
class Child : public Father, public Mother {
public:
void showBoth() {
Father::show(); // Father의 show() 호출
Mother::show(); // Mother의 show() 호출
}
};
int main() {
Child child;
child.showBoth(); // 각각의 부모 클래스의 show() 함수 호출
return 0;
}
9. 다형성과 가상 함수
다형성(polymorphism)은 객체 지향 프로그래밍의 핵심 특징 중 하나로, 동일한 코드를 사용하여 다양한 타입의 객체를 처리할 수 있는 기술입니다. 다형성은 크게 두 가지 유형으로 나뉘는데, 컴파일 시간 다형성은 함수 오버로딩이나 연산자 오버로딩을 통해 구현되며, 실행 시간 다형성은 객체의 타입이 다를 때 동일한 메시지가 전달되어도 서로 다른 동작을 수행하게 됩니다. **상향 형변환(up-casting)**은 자식 클래스의 포인터가 부모 클래스를 가리키도록 변환하는 것으로, 이 경우 자식 클래스에서 상속받은 부분만 접근할 수 있습니다. **하향 형변환(down-casting)**은 부모 클래스를 가리키는 포인터가 자식 클래스를 가리키도록 변환하는 것으로, 이때 포인터가 실제로 가리키고 있는 객체가 자식 클래스인 경우에만 안전하게 사용할 수 있습니다. 이와 같은 형변환은 포인터뿐만 아니라 참조자에서도 적용할 수 있습니다.
#include <iostream>
// 부모 클래스
class Animal {
public:
virtual void speak() {
std::cout << "Animal speaks" << std::endl;
}
};
// 자식 클래스 1
class Dog : public Animal {
public:
void speak() override {
std::cout << "Dog barks" << std::endl;
}
};
// 자식 클래스 2
class Cat : public Animal {
public:
void speak() override {
std::cout << "Cat meows" << std::endl;
}
};
int main() {
Animal* animal; // 부모 클래스 포인터
// 상향 형변환
Dog dog;
animal = &dog; // Dog 객체를 Animal 포인터로 가리킴
animal->speak(); // "Dog barks" 출력
// 하향 형변환
Cat cat;
Animal* animalPtr = &cat; // 부모 클래스 포인터
Cat* catPtr = dynamic_cast<Cat*>(animalPtr); // 하향 형변환
if (catPtr) {
catPtr->speak(); // "Cat meows" 출력
}
return 0;
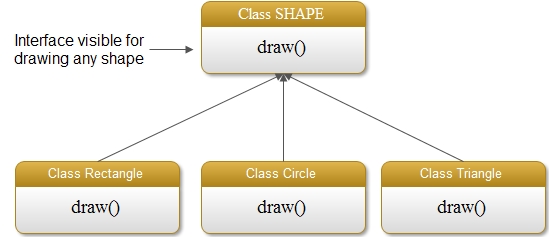
}가상 함수(virtual function)는 객체 지향 프로그래밍에서 다형성을 구현하는 중요한 개념으로, 부모 클래스의 포인터를 통해 자식 클래스의 멤버 함수를 호출할 때, 객체의 종류에 따라 적절한 함수가 실행되도록 합니다. virtual 키워드는 멤버 함수에만 사용 가능하며, 부모 클래스에서 virtual로 정의한 경우, 자식 클래스에서 이 키워드를 사용하지 않더라도 자동으로 가상 함수가 됩니다. **동적 바인딩(Dynamic Binding)**은 함수 호출을 해당 함수의 몸체와 연결하는 과정을 의미하며, 일반 함수는 컴파일 단계에서 모든 바인딩이 완료되는 반면, 가상 함수는 실행 시까지 바인딩이 지연되어 실행 시간에 호출될 함수를 결정합니다. 이를 통해 다형성을 구현할 수 있습니다. 가상 소멸자(virtual destructor)는 다형성을 사용할 때 소멸자가 가상 함수로 설정되지 않으면 문제가 발생할 수 있으므로, 부모 클래스의 소멸자에 virtual 키워드를 사용해야 합니다. **순수 가상 함수(pure virtual function)**는 함수의 선언부만 존재하고 몸체가 없는 함수로, 이러한 함수를 하나라도 포함한 클래스는 **추상 클래스(abstract class)**가 되며, 객체를 생성할 수 없습니다. 추상 클래스는 주로 추상적인 개념을 나타내거나 클래스 간의 인터페이스를 정의하는 데 사용되며, 이를 상속받은 자식 클래스는 반드시 순수 가상 함수를 구현해야 합니다.
#include <iostream>
using namespace std;
// 추상 클래스
class Shape {
public:
// 순수 가상 함수
virtual void draw() = 0; // 이 함수는 자식 클래스에서 반드시 구현해야 함
virtual ~Shape() { cout << "Shape 소멸자" << endl; } // 가상 소멸자
};
// 자식 클래스 1
class Circle : public Shape {
public:
void draw() override {
cout << "Circle 그리기" << endl;
}
~Circle() { cout << "Circle 소멸자" << endl; }
};
// 자식 클래스 2
class Rectangle : public Shape {
public:
void draw() override {
cout << "Rectangle 그리기" << endl;
}
~Rectangle() { cout << "Rectangle 소멸자" << endl; }
};
void drawShape(Shape* shape) {
shape->draw(); // 동적 바인딩을 통해 호출
}
int main() {
Shape* circle = new Circle(); // Circle 객체 생성
Shape* rectangle = new Rectangle(); // Rectangle 객체 생성
drawShape(circle); // "Circle 그리기" 출력
drawShape(rectangle); // "Rectangle 그리기" 출력
delete circle; // Circle 소멸자 호출
delete rectangle; // Rectangle 소멸자 호출
return 0;
}'Computer Scinece > Programming Principles' 카테고리의 다른 글
| Programming Principles [6] : 최적화 알고리즘 (Optimization Algorithms) (1) | 2024.09.18 |
|---|---|
| Programming Principles [5] : 재귀 알고리즘 (Recursive Algorithm) (0) | 2024.09.18 |
| Programming Principles [4] : 자료 구조 (Data Structures) (0) | 2024.09.18 |
| Programming Principles [3]: 데이터 추상화와 리스트 (Data Structures & List) (1) | 2024.09.18 |
| Programming Principles[1]: 프로그래밍 기본 (Basic Algorithms) (0) | 2024.09.18 |