
List
리스트는 순서가 있는 값들의 모음이다.
- 선형 관계 (Linear Relationship) : 첫 번째 요소를 제외 한 각 요소에는 고유한 선행 요소가 있고 마지막 요소를 제외한 각 요소에는 고유 한 후속 요소가 있다
- 길이 (Length) : list 안의 아이템의 개수; 길이는 프로그램 실행에 따라 달라질 수 있다.

Unsorted list vs Sorted list
1. Unsorted list : 데이터 항목들이 특정 순서 없이 저장되며 데이터 요소 간의 유일한 관계는 앞 요소과 뒤 요소 간의 관계이다. 즉, 어떤 데이터 뒤에 어떤 데이터가 있는지만 알 수 있고, 데이터 자체의 값에 따라 어떤 순서로 배열되어 있는지 알 수 없다.
2. Sorted list : 데이터 항목들이 특정 키(key) 값에 따라 정렬되어 저장되며 이 키 값은 리스트의 항목들을 논리적 순서로 정렬하는 데 사용되는 속성이다. 즉, 리스트의 모든 항목들은 서로 비교가 가능하며, 키 값을 기준으로 앞뒤 관계가 정해져 있다.
3. Key : Unsorted list와 Sorted List를 구분하는 역할을 한다. Sorted List 레코드 안에 해당하는 멤버 변수는 키를 포함해야한다. key가 되기 위한 조건은 크기의 대수관계를 비교할 수 있어야한다.
Unsorted List ADT Operations

Implement Unsorted ADT
- 생성자 ( 클래스의 특수 member function으로 클래스 객체가 생성될 때 암시적으로 호출되는 함수) 정의
2. 리스트 컨트롤 함수 구현
LengthIs(): 리스트의 길이를 반환
IsFull() : 리스트가 가득 찼는지 여부를 확인.length 멤버 변수의 값과 MAX_ITEMS 상수를 비교하여 같으면 true를, 다르면 false를 반환
ResetList() :기능: 리스트를 처음 위치로 초기화.currentPos 멤버 변수에 -1을 할당하여 리스트의 현재 위치를 초기화
GetNextItem() : ItemType& item: 참조 변수. 이 함수는 해당 변수에 다음 아이템을 저장한다. 리스트에서 다음 아이템을 가져온다.currentPos 멤버 변수를 1 증가시켜 다음 위치를 가리킨 후, 그 위치에 있는 아이템 (info 배열의 값)을 item 변수에 복사
3. 리스트 요소 컨트롤 함수 구현
1. InsertItem(ItemType item):
- 기능: 리스트에 새로운 아이템을 삽입합니다.
- 매개변수:
- ItemType item: 삽입할 아이템 객체
- 동작 과정:
- 현재 리스트 길이 (length)를 인덱스로 하여 info 배열에 item 객체를 복사합니다.
- length 멤버 변수를 1 증가시켜 리스트 길이를 늘립니다.
2. RetrieveItem(ItemType& item, bool& found):
- 기능: 리스트에서 특정 아이템을 검색하여 찾으면 아이템과 찾았다는 여부(true)를 반환합니다.
- 매개변수:
- ItemType& item: 검색할 아이템 객체 (참조 변수)
- bool& found: 아이템을 찾았는지 여부를 반환할 변수 (참조 변수)
- 동작 과정:
- found 변수를 false로 초기화합니다.
- 검색할 위치 (location)를 0으로 설정합니다.
- location이 리스트 길이보다 작고 found가 false일 때까지 반복합니다.
- item.ComparedTo(info[location]) 함수를 호출하여 검색할 아이템과 현재 위치의 아이템을 비교합니다.
- 비교 결과가 LESS 또는 GREATER이면 location을 1 증가시키고 반복을 계속합니다.
- 비교 결과가 EQUAL이면 검색 성공 (found를 true로 변경)하고, 현재 위치의 아이템을 item 변수에 복사합니다.
3. DeleteItem(ItemType item):
- 기능: 리스트에서 특정 아이템을 삭제합니다.
- 매개변수:
- ItemType item: 삭제할 아이템 객체
- 동작 과정:
- 삭제할 아이템을 찾아 위치 (location)를 확인합니다.
- item.ComparedTo(info[location]) 함수를 반복 호출하여 일치하는 아이템을 찾을 때까지 location을 증가시킵니다.
- 일치하는 아이템을 찾으면, 마지막 요소 (info[length-1])를 찾은 위치 (location)에 복사합니다.
- length 멤버 변수를 1 감소시켜 리스트 길이를 줄입니다.
[전체 코드]
Sorted List ADT Operations

SortedType class
정렬 목록 ADT에서 항상 정렬 상태 유지하기 : 정렬 목록 ADT 인스턴스가 항상 정렬된 상태를 유지하려면 InsertItem과 DeleteItem 멤버 함수의 구현을 변경해야 한다.
1. InsertItem:
- 새로운 항목을 삽입할 때 항목을 올바른 위치에 삽입해야 합니다.
- 이진 검색 트리와 같은 데이터 구조를 사용하면 새 항목을 로그 시간(O(log n))에 삽입할 수 있다.
- 단순 삽입 정렬을 사용하면 항목을 선형 시간(O(n))에 삽입할 수 있다.
2. DeleteItem:
- 항목을 삭제할 때 삭제된 항목의 빈 공간을 채워야 한다.
- 이진 검색 트리와 같은 데이터 구조를 사용하면 삭제된 항목의 자식 노드를 사용하여 빈 공간을 채울 수 있다.
- 단순 삽입 정렬을 사용하면 삭제된 항목 이후의 모든 항목을 한 칸씩 앞으로 이동해야 한다.
중복 항목: 중복 항목을 허용할 경우 삽입 및 삭제 시 중복 항목을 처리해야 한다.
정렬 기준: 항목을 어떤 기준으로 정렬할지 정의해야 한다. 정렬 기준이 변경되면 목록을 다시 정렬해야 한다.
정렬 목록 ADT 인스턴스를 항상 정렬된 상태로 유지하려면 InsertItem과 DeleteItem 멤버 함수를 적절하게 구현해야 한다. 또한 중복 항목 및 정렬 기준과 같은 추가적인 고려 사항도 처리해야 한다.
- 연결 리스트: 삽입 및 삭제가 비교적 간단하지만 검색 속도가 느림
- 배열: 검색 속도가 빠르지만 삽입 및 삭제가 비교적 복잡함
- 이진 검색 트리: 삽입, 삭제, 검색 속도가 모두 비교적 빠름
정렬되지 않은 목록(Unsorted List)에서 항목을 검색할 때는 info[0]부터 순차적으로 모든 요소를 검사하여 일치하는 키(key)를 찾거나 목록 끝에 도달할 때까지 반복했지만 정렬된 목록(Sorted List)에서는 이보다 더 효율적인 검색 방법을 사용할 수 있다.
- 정렬된 목록은 데이터가 특정 기준으로 순서대로 정렬되어 있다.
- 검색하려는 값보다 큰/작은 값을 만나면 더 이상 검색을 진행할 필요가 없다.

Binary Search (wikipedia)
이진 검색 (Binary Search): 목록의 중간 지점에 있는 요소와 검색하려는 값을 비교한다.
- 일치하는 경우 검색 종료.
- 검색값이 더 크면 목록의 오른쪽 절반만 검색.
- 검색값이 더 작으면 목록의 왼쪽 절반만 검색
- 이 과정을 반복하여 목록을 반으로 계속 좁혀나가며 검색
순차 탐색 (Linear Search): 여전히 사용할 수 있지만 이진 검색보다 느리다.
- 정렬된 목록에서도 사용할 수 있지만 이점이 없다.
- 반복문
2. 재귀
SortedList의 구현
Stack

Stack
스택 (Stack) : LIFO(Last In, First Out) 방식으로 작동하는 자료구조로 가장 마지막에 삽입된 데이터가 가장 먼저 추출되는 특징을 가진다.
- 스택은 동일한 타입의 데이터로 구성된 순서가 있는 집합이다.
- 스택에서 데이터 추가 및 제거는 맨 위 에서만 일어날 수 있다. 즉, 마치 접시를 쌓아 올리는 것처럼 나중에 넣은 데이터가 먼저 나온다.
스택 ADT Operations

[Observers - Observe State]
1. MakeEmpty : 스택을 비어 있는 상태로 만든다.
2. IsEmpty :현재 스택이 비어 있는지 여부를 확인하는데 스택이 비어 있으면 True를 반환하고, 데이터가 남아 있으면 False를 반환한다.
3. IsFull : 현재 스택이 가득 차있는지 여부를 확인하는데 스택이 더 이상 데이터를 저장할 수 없는 상태이면 True를 반환하고, 데이터를 추가할 수 있는 여유가 있으면 False를 반환한다.
4. ItemType Top : 스택의 맨 위에 있는 데이터의 사본을 반환합니다. 데이터를 제거하지 않고 값만 확인하는 용도로 사용됩니다. 스택이 비어 있으면 예외를 발생시킵니다.
[Transformers - Change State]
5. Push(ItemType newItem) : 새로운 데이터(newItem)를 스택의 맨 위에 추가한다. 스택이 이미 가득 차 있으면 예외를 발생시킨다.
6. Pop : 스택의 맨 위에 있는 데이터를 제거하고 반환하며 스택이 비어 있어 데이터를 제거할 수 없는 경우 예외를 발생시킨다.
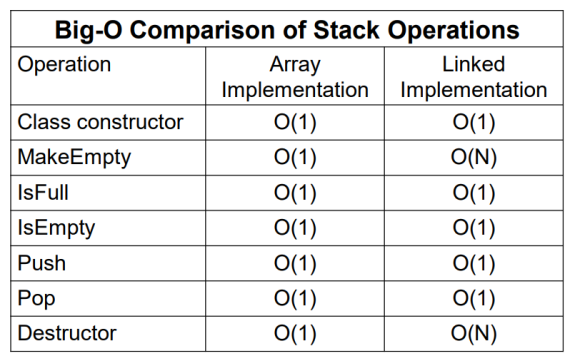
스택의 구현
1. 예외 클래스 및 템플릿 선언 : StackType이라는 이름의 템플릿 클래스를 선언한다. ItemType은 스택에 저장될 실제 데이터 형식으로 인스턴스화될 때 대체될 플레이스홀더이다. 그 후 생성자와 구현할 함수, 변수들을 클래스 안에 선언한다.
2. 1차원 배열을 사용해 스택을 생성
- top : 가장 최근에 입력되었던 자료를 가리키는 변수
- stack[0] ... stack[top] : 먼저 들어온 순으로 저장
- 공백 상태: top = -1
3. 스택의 검사 ( isEmpty / isFull ): 스택이 비어있거나 가득차 있는지 확인하고 부울 값 (true 또는 false)을 반환한다. 스택의 맨 위 요소의 인덱스를 추적하는 top 멤버 변수를 사용하는데, 요소가 스택에 푸시될 때마다 top이 증가하여 새로 추가된 요소의 위치를 가리키고 빈 스택은 top을 -1로 갖는다. 또한 top 변수는 가장 최근에 추가된 요소의 인덱스를 가리키는데 top이 MAX_ITEMS - 1에 도달하면 다음 푸시 작업은 할당된 공간을 넘어서 요소를 추가하려고 시도하여 스택이 가득 찬다는 것을 의미한다.
4. 스택의 삽입(Push) 및 삭제 (Pop) : 요소를 추가하면 IsFull() 함수를 호출하여 스택이 이미 가득 찼는지 확인하고 만약 스택이 가득 찬 경우 사용자가 정의한 FullStack 예외 클래스가 throw된다. top 변수는 항상 스택의 맨 위 요소를 가리키는 인덱스 역할을 하는데, 스택에 여유 공간이 있다면 top 변수를 1 증가시킨다. 요소를 제거하면 IsEmpty() 함수를 호출하여 스택이 비어 있는지 확인한다. 만약 비어 있다면 사용자가 정의한 EmptyStack 예외 클래스가 throw된다. 스택에 데이터가 있다면 top 변수를 1 감소시킵니다. 이렇게 하면 top이 다음으로 맨 위가 되는 요소를 가리키도록 한다.
c++로 Stack을 구현한 전체 코드이다.
Dinamically allocate Stack
ADT의 장점은 사용되는 구현의 종류를 변경할 수 있다는 것이다. 동적 할당이란 각 스택 요소를 푸시될 때마다 동적으로 메모리 공간을 할당하는 방법이다.
C++의 operator new 연산자는 힙이라고 불리는 자유 저장소 영역에서 메모리를 동적으로 할당하는 역할을 합니다.
핵심 기능:
- 프로그램 실행 도중 필요한 메모리 양을 정확히 알 수 없는 경우 유용합니다.
- 사용자가 원하는 객체를 위한 메모리를 할당하고, 할당된 메모리 영역의 주소값을 반환합니다.
- 할당된 메모리는 명시적으로 delete 연산자를 이용하여 해제해야 합니다. 해제하지 않으면 **메모리 누수 (memory leak)**가 발생할 수 있습니다.
동작 과정:
- operator new는 시스템에게 요청한 크기만큼의 메모리 공간을 자유 저장소에서 찾습니다.
- 메모리가 충분히 존재한다면, 해당 공간을 할당하고 그 주소값을 포인터 형태로 반환합니다.
- 반환된 주소값을 이용하여 원하는 객체를 생성할 수 있습니다.
- 객체가 더 이상 필요 없을 때는 반드시 delete 연산자를 이용하여 할당된 메모리를 해제해야 합니다.
로컬 스택 변수의 스코프가 끝나면 다음과 같은 일이 발생합니다.
- 스택 변수 해제: 로컬 변수 topPtr 자체가 저장되어 있는 스택 메모리는 해제됩니다.
- 연결 리스트 노드 유지: topPtr이 가리키는 연결 리스트의 실제 노드들은 자동으로 해제되지 않습니다.
- 소멸자 활용: 클래스 소멸자 (destructor)는 이러한 상황을 처리하기 위해 존재합니다. 클래스 소멸자는 클래스 객체가 소멸될 때 자동으로 호출되며, 객체가 관리하는 동적 메모리 해제를 담당합니다.
따라서 코드에서 topPtr이 연결 리스트의 헤드 노드를 가리키고 있다면, 클래스 소멸자는 topPtr을 시작으로 연결 리스트를 순회하며 각 노드가 가리키는 메모리를 해제해야 합니다. 이를 통해 메모리 누수 (memory leak)를 방지할 수 있습니다.


스택의 구현 (동적 할당)
Queue

Queue
Queue : 큐(Queue)는 선입선출(FIFO, First In First Out) 방식으로 데이터를 저장하고 처리하는 자료구조이다. 먼저 들어온 데이터가 먼저 나오는 방식이며 마치 실제 줄을 서서 기다리는 것과 같다.
스택 ADT Operations

1. MakeEmpty : 큐를 비운 상태로 만든다. 큐에 저장된 모든 데이터가 제거된다.
2. IsEmpty : 큐가 비어있는지 여부를 확인한다. 큐에 하나의 데이터도 없으면 True를 반환하고, 하나라도 데이터가 있으면 False를 반환한다.
3. IsFull : 큐가 꽉 차 있는지 여부를 확인한다. 큐에 더 이상 데이터를 저장할 수 없는 상태이면 True를 반환하고, 데이터를 추가할 수 있는 여유가 있으면 False를 반환한다.
4. Enqueue (삽입) : 새로운 데이터(newItem)를 큐의 뒤쪽 끝에 추가합니다. 삽입된 데이터는 다음 Dequeue 명령어를 통해 꺼내질 수 있다.
5. Dequeue (삭제) : 기능: 큐의 앞쪽에 있는 데이터를 삭제하고 반환합니다. 반환된 데이터는 item 변수에 담을 수 있다다. 큐에서 가장 먼저 들어온 데이터가 삭제된다.
큐의 구현
Circular Queue

Circular Queue
Circular Queue : 원형 큐는 선형 큐의 변형으로, 링 형태의 구조를 사용하여 데이터를 저장하고 관리하는 큐이다. 선형 큐와 마찬가지로 FIFO (First-In-First-Out) 방식을 따르며, 먼저 삽입된 데이터가 먼저 삭제된다.
선형 큐는 데이터를 배열에 저장하는데, 이 배열은 고정된 크기를 가지고 있다. 데이터를 삽입하고 삭제할 때마다 배열의 앞뒤로 데이터를 옮겨야 할 수 있으며, 이 과정에서 메모리 낭비가 발생할 수 있다. 반면 원형 큐는 링 형태의 구조를 사용하여 메모리를 효율적으로 활용한다. 즉, 데이터는 배열의 한쪽 끝에서 다른 쪽 끝으로 순환하며, 사용되지 않는 공간은 새로운 데이터를 저장하는 데 사용될 수 있다.
선형 큐는 배열의 크기가 제한되어 있기 때문에, 데이터가 너무 많이 삽입되면 오버플로 (overflow) 현상이 발생하여 데이터 손실이 발생할 수 있습니다. 하지만 원형 큐는 데이터가 배열의 끝에 도달하면 다시 처음으로 돌아가도록 설계되어 있어 데이터 손실 없이 데이터를 삽입할 수 있다.
원형 큐의 구현
1. 템플릿 선언 : CircularQue라는 이름의 템플릿 클래스를 선언한다. ItemType은 스택에 저장될 실제 데이터 형식으로 인스턴스화될 때 대체될 플레이스홀더이다. 그 후 생성자와 구현할 함수, 변수들을 클래스 안에 선언한다.
2.
동적 할당 큐
Linked List

연결 리스트 (Linked List) : 링크드 리스트란 배열과 비슷하게 선형적으로 연결된 자료구조이다. 하지만 인접한 메모리 공간에 저장되는 배열과 다르게 링크드 리스트는 인접한 메모리 공간에 저장되지 않는다. 위의 사진처럼 각 node마다 다음 node 주소를 저장하는 포인터가 있다. 연결 리스트는 실제 메모리 공간에서 아무 규칙없이 저장되어진다. 각 노드는 다음 노드의 주소값을 저장하고 있으므로 다음 노드의 값에 접근할 수 있다. 각 노드는 데이터를 저장하는 변수와 다른 노드를 가르키는 포인터 변수로 구성되어 있다.
- 배열의 사이즈는 고정되어 있고 배열을 선언할 때 배열의 사이즈를 항상 알아야 한다. 배열에 할당된 메모리들은 사용 유무와 상관없이 항상 메모리를 차지한다.
- 링크드 리스트는 사이즈의 변동이 자유롭다. 예를들어, 2번째 요소 2를 지우는 경우가 생긴다면, 그 뒤에 있는 3,4,5모든 요소들을 한 칸씩 앞으로 당겨줘야 하고, 이 작업은 효율성이 좋지 못하다.만약 index가 링크드 리스트로 만들어졌다면, 1다음에 3을 연결시켜 준 후 2를 지우면 된다.
링크드 리스트는 Random access가 불가능하며 배열의 경우 index[1]라는 변수를 이용해 2에 바로 접근이 가능하지만 링크드 리스트는 맨 첫번째 노드부터 다음 노드를 반복해서 검색한다. 배열과 다르게 포인터 변수를 저장하므로 각 노드마다 추가적인 메모리 공간을 요구한다는 단점이 있다.
Singly Linked List

단방향 연결 리스트의 첫번째 노드는 head라고 불린다. head노드는 리스트가 비어있어도 항상 존재한다. head로 정해진 노드는 data변수에 아무것도 저장하지 않는다.리스트가 비어있다면 head의 포인터 변수는 NULL을 향하고 있다.
data변수의 data type은 무엇이든 될 수 있다. head를 포함한 모든 단방향 연결 리스트의 노드는 위 사진처럼 data를 저장하는 부분과 다음 노드의 주소값을 저장하는 포인터 변수로 구성되어진다.
SortedType
상속 따라가는 연산이 있어 입력되는 데이터의 개수에 비례해 복잡도가 증가
정렬 - 삽입할 정확환 위치를 찾아야되는데 누적이됨
Retrieveitem 기존에는 바이너리 서치를 적용했으나 안됨
정렬리스트 - 따져야할게 많음
unsorted list와 마찬가지로 특정 아이템을 검색해야하는 것은 동일
어디에 들어가야 정당한지 검색하기 위해서
- 앞 항목과 비교: 정렬된 리스트에서 새로운 항목을 삽입할 때 다음과 같은 코드를 사용할 수 없습니다.
C++
if (item == (location->next)->info) { // 코드 실행 }
코드를 사용할 때는 주의가 필요합니다.
문제는 만약 새로운 항목을 리스트의 끝에 삽입해야 하는 경우입니다. 위 코드는 다음 항목과만 비교하기 때문에 끝에 도달했는지 판단하지 못합니다.
- 이전 포인터 유지: 정렬된 리스트를 순회하면서 삽입 위치를 찾을 때는 현재 위치 (current pointer)뿐만 아니라 **이전 위치 (previous pointer)**도 함께 유지해야 합니다.
이전 위치를 알고 있으면 새로운 항목을 현재 위치와 이전 위치 사이에 삽입할 수 있습니다.
결론
정렬된 자료형을 효율적으로 구현하기 위해서는 다음을 수행해야 합니다.
- 리스트를 순회하면서 현재 위치와 이전 위치를 모두 유지해야 합니다.
- 새로운 항목의 삽입 위치를 찾을 때 앞 항목과만 비교하는 것은 불충분합니다.
Circular Linked List

원형 연결 리스트(circular linked list) : 단순 연결 리스트의 단점을 보완한 리스트이다. 단순 연결 리스트는 한 방향으로 움직이면서 그 끝이 정해져 있기 때문에 리스트를 검색할 때 항상 리스트의 처음부터 접근해야하는 단점이 있고 리스트가 순환을 요구한다면 더욱 불리하다. 이를 해결하기 위해 단순 연결리스트의 마지막 노드가 리스트의 처음 노드를 가리키도록 만든 것이 원형 연결 리스트이다.
- 메리트가 그렇게 많지않음.
- 원소가 하나면 자기자신을 next로 가르킴
Doubly Linked List

Doubly Linked List
이중 연결 리스트 : 각 노드가 두 개의 링크를 가지고 있어 양방향으로 이동이 가능한 연결 리스트이다. 일반적인 단순 연결 리스트에서는 다음 노드만을 가리키는 반면, 이중 연결 리스트는 이전 노드와 다음 노드를 모두 가리키며 삽입하고자하는 위치가 판명이되면 이전 원소를 가리키고 있는 포인터를 따라가면 된다.
- 탐색에서는 단일 연결 리스트보다 시간적 우위를 지닌다.
- 기준에 따라 Head에서 출발하거나, Tail에서 출발하는 것이 가능하다.
- 각 노드의 관리에 유의해야 하기 때문에, 작업량이 많아져 구현이 복잡하고 포인터가 차지하는 비율이 커져 자료구조의 크기와 사용 메모리가 증가한다.
이중 연결 리스트의 구현
3번이 어색하다면 포인터에 대해 되짚기
* & - 어설프게 알고있으면 이해 불가, 없애면 동작불가
location = Find item 부모의 Next를 직접 따오기위함
메모리주소 함수가 변경될때 다 사라져버림
list 연결관계 유지해야하기 때문에
Special Case


'Computer Scinece > Programming Principles' 카테고리의 다른 글
| Programming Principles [6] : 최적화 (optimization) (1) | 2024.09.18 |
|---|---|
| Programming Principles [5] : 알고리즘 (Algorithms) (0) | 2024.09.18 |
| Programming Principles [3] : 자료의 설계와 구현 (정리중) (1) | 2024.09.18 |
| Programming Principles [2] : 객체지향 프로그래밍 (Object-Oriented Programming) (1) | 2024.09.18 |
| Programming Principles[1] : C++의 기본 문법 (C++ basics) (0) | 2024.09.18 |